

Le mois d'avril 2026 apporte d'importantes nouveautés dans l'écosystème Snowflake, notamment la possibilité de structurer et d'appliquer une rigueur accrue dans l'utilisation de l'Intelligence Artificielle. Ces évolutions passent par la disponibilité générale (GA) des garde-fous et des budgets dédiés à l'IA, ainsi que par l'amélioration du Trust Center de Snowflake. Côté Data Engineering, nous observerons des évolutions sur le format Iceberg et les tables dynamiques, visant à simplifier nos architectures
On vous détaille ci-après les 4 actualités majeures de Snowflake.
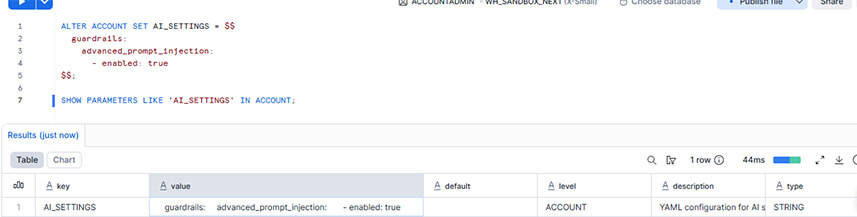
Snowflake - Cortex AI Guardrails (GA)
Le passage de l'IA de la phase "pilote" à la production s'accompagne de nouveaux risques de sécurité majeurs : les requêtes malveillantes. En disponibilité générale (GA) depuis le 20 avril pour les clients Snowflake Enterprise Edition, Cortex AI Guardrails s'intègre directement au catalogue Snowflake Horizon pour neutraliser ces menaces en temps réel.
Le fonctionnement de Cortex Guardrails
- Détection des Prompt Injections : Le système identifie et bloque les utilisateurs essayant de contourner les instructions système de vos agents (par exemple, pour forcer Cortex Code à exécuter des commandes non prévues ou accéder à des données non autorisées)
- Prévention des "Jailbreaks" : Empêche les tentatives de contournement des protocoles de sécurité du modèle sous-jacent
- Gouvernance centralisée : Plutôt que de coder des règles de sécurité application par application, l'activation se fait au niveau global du compte. Snowflake utilise un raisonnement contextuel pour bloquer même les attaques "Zero-day" (schémas d'attaque inédits)
Note FinOps : Modèle de facturation : L'activation de cette protection avancée s'accompagne d'une tarification basée sur l'usage (calcul géré par Snowflake). La fonction de sécurité AI_GUARDRAILS consomme exactement 0,35 crédit par million de tokens scannés (au 24 Avril 2026). Cette facturation s'applique au volume de texte analysé par le bouclier lors de la vérification des requêtes, ce qui permet de sécuriser vos applications avec un coût prédictible et proportionnel à votre activité

Exemple d’utilisation de Cortex Complete où la partie guardrails est le plus grand consommateur de tokens
Snowflake - Budgets IA & Détections Trust Center (GA)
1/ Le contrôle FinOps : Budgets dédiés pour l'IA (Shared Resources) Les fonctionnalités d'Intelligence Artificielle (Cortex Code, Cortex Agents, Fonctions IA) sont des ressources "partagées" à l'échelle du compte. Pour éviter un coût global illisible, Snowflake nous permet désormais de suivre et limiter ces dépenses (AI_SERVICES) par équipe ou par centre de coûts
- Le fonctionnement : Vous appliquez un Tag à vos utilisateurs (ex: cost_center = 'FINANCE'). Vous associez ensuite ce tag à un budget spécifique, puis vous y ajoutez la ressource IA à surveiller (ex: AI FUNCTION)
- Le bénéfice : Le budget comptabilisera uniquement les crédits IA consommés par les membres de cette équipe. Une fois la limite de dépense atteinte, des alertes automatiques sont déclenchées (avec possibilité de configurer des actions personnalisées), vous garantissant une visibilité et une maîtrise totale de votre enveloppe financière par métier

2/ Le contrôle SecOps : Trust Center Detections Le Trust Center n'est plus un simple tableau de bord statique, il devient proactif. La fonctionnalité "Detections" (et "Data Security") analyse en continu votre environnement pour identifier les vulnérabilités
- Action : Le système audite votre configuration face aux standards de l'industrie (CIS Benchmarks) et aux meilleures pratiques Snowflake.
- Bénéfice : Vous êtes alerté automatiquement en cas de dérive de sécurité : un compte à privilèges sans MFA activé, un rôle PUBLIC disposant de droits trop permissifs, ou encore des politiques réseau (Network Policies) mal configurées
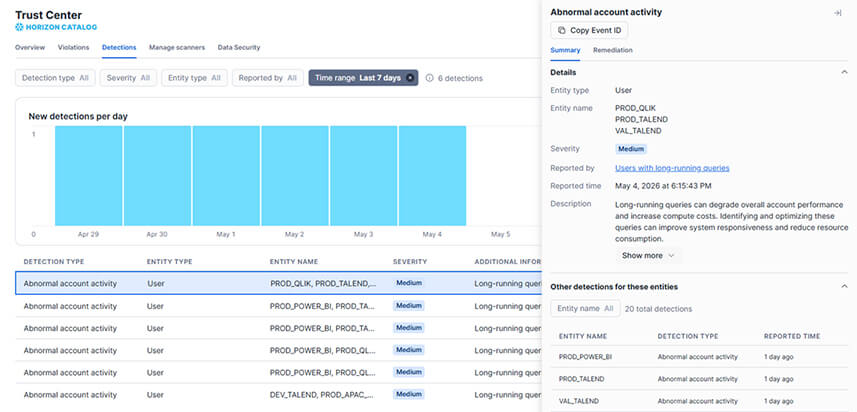
Exemple de détections au niveau du Trust Center (Une des détections concerne une query avec une durée de 9 secondes, qui a déclenché le report “long-running queries”)
Le scanner pour les Long-Running queries se base sur la moyenne de temps d’exécution, une query avec un temps de traitement de 8 secondes peut donc déclencher une alerte si la majorité de vos queries sont traitées en moins de 4 secondes
Stockage géré par Snowflake pour Apache Iceberg (Preview)
Jusqu'à présent, adopter le format ouvert Iceberg dans Snowflake nécessitait de provisionner et de sécuriser vous-même un espace de stockage externe (un bucket S3 ou un Azure Data Lake), puis de créer un EXTERNAL VOLUME avec les permissions IAM associées.
Depuis avril, Snowflake simplifie radicalement cette architecture : vous pouvez désormais laisser Snowflake gérer intégralement le stockage physique de vos fichiers Iceberg.
Les avantages clés pour votre architecture :
- Infrastructure "Zero-Friction" : Fini les configurations de stockage complexes. Snowflake stocke les fichiers de données et de métadonnées en interne. Il suffit d'utiliser le volume réservé SNOWFLAKE_MANAGED
- Interopérabilité maintenue (Horizon Catalog) : Bien que le stockage soit interne à Snowflake, la table reste une véritable table Iceberg. Grâce au Snowflake Horizon Catalog, vos moteurs de requêtes externes (Spark, Trino, etc.) peuvent toujours s'y connecter et lire la donnée
- Optimisation FinOps : Contrairement aux tables Iceberg externes classiques, cette nouveauté supporte la création de tables Transient. Si vous stockez des données temporaires, vous évitez ainsi les coûts de stockage liés au Fail-safe (les 7 jours de rétention de secours de Snowflake).
- Ingestion temps réel : Ces tables sont 100% compatibles avec Snowpipe et l'API haute performance Snowpipe Streaming.
CREATE ICEBERG TABLE ma_table_iceberg_interne (colonne int)
CATALOG = SNOWFLAKE
EXTERNAL_VOLUME = SNOWFLAKE_MANAGED;
Exemple de création de tables Iceberg & transient Iceberg stockées en interne dans Snowflake
CREATE TRANSIENT ICEBERG TABLE ma_table_iceberg_transient_interne(ma_colonne int)
CATALOG = SNOWFLAKE
EXTERNAL_VOLUME = SNOWFLAKE_MANAGED;
Support des clés Primaires pour les tables dynamiques (GA)
C'était une attente forte des Data Engineers : depuis le 16 avril, les Tables Dynamiques (Dynamic Tables) gèrent nativement les clés primaires.
Les avantages :
- Déduction automatique (Query-derived keys) : Vous n'avez pas forcément besoin de déclarer la clé. Snowflake analyse votre requête SQL : s'il détecte un GROUP BY ou un filtre QUALIFY ROW_NUMBER() = 1, il en déduit automatiquement une contrainte d'unicité et l'utilise pour tracker les changements
- Rafraîchissement incrémental : Auparavant, si une table dynamique "Amont" était rafraîchie en mode Full Refresh (recalcul total), toutes les tables dynamiques "Aval" devaient aussi être en Full Refresh. Ce n’est plus le cas, une table aval peut désormais être rafraîchie de manière Incrémentale depuis une table amont en Full Refresh, à condition que cette dernière possède une clé primaire déduite par le système
- Clés primaires définies : Si votre table de base (source) possède une clé primaire définie avec la propriété RELY, Snowflake s'appuie dessus. Même si vous écrasez cette table source avec un INSERT OVERWRITE massif, Snowflake saura identifier les lignes réellement modifiées pour ne mettre à jour que le strict nécessaire en aval
En bref : Les nouveautés d'avril 2026
- CHECK constraints pour les tables standard (GA) : Les contraintes CHECK (ex: s'assurer qu'une colonne d'âge contient une valeur > 0) sont désormais pleinement supportées pour garantir la qualité des données dès l'ingestion, s'alignant ainsi sur les standards SQL classiques
- Fonctions de métriques au niveau du schéma (GA) : Il est désormais possible d'appliquer des fonctions de qualité des données (Data Metric Functions) globalement à l'échelle d'un schéma complet, simplifiant considérablement l'audit de qualité sans avoir à paramétrer table par table
- Snowflake Native Apps : Communication Inter-App (GA) : Les applications natives déployées sur Snowflake peuvent désormais communiquer entre elles. Une avancée majeure pour les développeurs construisant des architectures micro-services ou des écosystèmes d'applications complexes sur le Data Cloud
- Écriture sur Iceberg depuis Databricks Unity Catalog (Azure) (GA) : L'interopérabilité s'accélère. Les tables Iceberg gérées par Snowflake peuvent désormais recevoir des écritures directes (Write support) depuis des clusters utilisant le Unity Catalog de Databricks sur l'infrastructure Azure
- Réplication de Cortex Search et des Workspaces (GA) : Pour consolider vos Plans de Continuité d'Activité (PCA/PRA), les objets de recherche vectorielle (Cortex Search) et vos environnements de développement (Workspaces) sont désormais nativement pris en charge par les groupes de réplication inter-régions
- Connecteur Kafka v4.0 (GA) : Le connecteur natif pour Apache Kafka fait peau neuve avec une version 4.0 stabilisée pour vos flux d'ingestion en temps réel
- Extraction de documents et d'images (GA) : Les fonctions AI_COMPLETE et AI_PARSE_DOCUMENT sortent de la phase de test. Il est désormais possible de traiter des PDF, d'extraire du texte depuis des images, et d'analyser des documents non structurés avec des plafonds de traitement augmentés (jusqu'à 2 000 pages)
Agenda : Prochains Rendez-vous Snowflake
- 18 - 29 Mai 2026 : Accelerate Virtual Event Series (Virtuel) Une série de webinaires spécialisés par secteur d'activité (Finance, Retail, Santé, etc)
- 1 - 4 Juin 2026 : Snowflake Data Cloud Summit '26 (San Francisco) Le rendez-vous mondial majeur
- 7 Octobre 2026 : Snowflake World Tour (Paris)
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ? Rendez-vous sur la page Contact.