

Si le mois dernier marquait une explosion des cas d'usages IA et de l'ouverture des données, ce mois de mars 2026 apporte les outils pour contrôler ces contextes. En mars Snowflake introduit l'Infrastructure-as-Code native (DCM), permet l'écriture sur vos tables Iceberg par des moteurs externes, et déploie des outils pour évaluer la fiabilité de vos agents IA et maîtriser leurs coûts. Mars se focalise sur le passage à l'échelle sous contrôle.
Alerte FinOps : Cortex Code devient payant au 1er Avril
Avant de plonger dans les nouveautés, une information cruciale pour vos budgets : la période de gratuité de la Preview de Cortex Code dans Snowsight touche à sa fin.
Quand ?
→ À partir du 1er avril 2026, l'utilisation de l'assistant de codage IA est facturée à la consommation (tokens), venant directement débiter vos crédits Snowflake.
Comment suivre vos coûts ?
→ Snowflake a mis à disposition la vue système CORTEX_CODE_SNOWSIGHT_USAGE_HISTORY (dans le schéma SNOWFLAKE.ACCOUNT_USAGE).
Les 3 Actualités Majeures
1. DCM Projects (L'Infra-as-Code native)
En Preview publique depuis le 20 mars, Declarative Configuration Management (DCM) est la nouveauté infrastructure. Avec l'arrivée de DCM, Snowflake intègre nativement une approche déclarative. Le principe est simple : vous décrivez l'état final que vous souhaitez pour votre base de données dans de simples fichiers texte. Snowflake s'occupe de calculer la différence avec l'existant et génère automatiquement les actions pour y parvenir, en toute sécurité.
Pourquoi ça change tout pour vos équipes DataOps ?
- Déploiement fiabilisé : Vous définissez l'état final souhaité de vos objets (tables, tâches, pipelines) à l'aide de templates Jinja et de fichiers YAML. Snowflake se charge de calculer et d'exécuter les modifications nécessaires (plan / apply connu des utilisateurs de Terraform).
- Intégration Git native : Vos définitions d'infrastructure vivent directement dans votre dépôt Git, synchronisé avec Snowflake. Le versioning de vos bases de données devient naturel et sécurisé.
- Indépendance : Plus besoin de maintenir une infrastructure tierce complexe pour orchestrer vos déploiements basiques sur Snowflake.
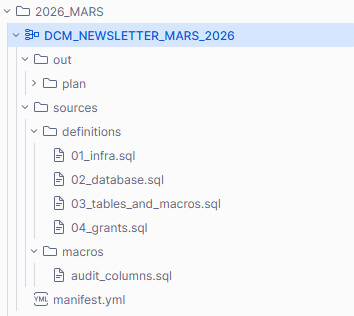
Exemple de structure d’un projet DCM, déployé dans un workspace partagé
La structure d’un projet DCM :
- manifest.yml (Configuration racine) : Définit les métadonnées du projet, les variables d'environnement et les configurations de déploiement (Dev, QA, Prod). C'est le point de départ lu par Snowflake.
- Sources/definitions/ (État de l'infrastructure) : Contient les fichiers .sql utilisant la syntaxe déclarative (ex:
DEFINE TABLE, GRANT). Définit l'état cible exact des objets Snowflake et des permissions, en remplacement des commandes impératives (CREATE OR REPLACE). - Sources/macros/ (Logique dynamique) : Regroupe les fonctions Jinja réutilisables. Permet de standardiser la configuration, comme l'application automatique de préfixes selon l'environnement ou l'injection de tags de facturation.
- out/ et out/plan/ (Artefacts d'exécution) : Répertoires générés automatiquement lors de la commande snow dcm plan. Ils contiennent les éléments pré-déploiement à auditer ou intégrer dans une chaîne CI/CD.
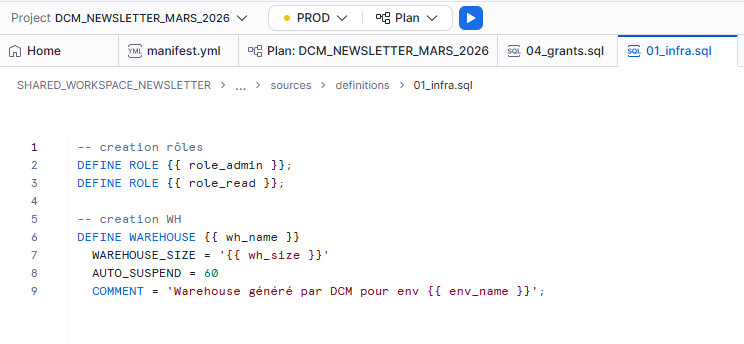
Exemple de fichier .sql avec l’utilisation de DEFINE et variable du manifest.yml
Exemple de contenu Manifest.yml :
manifest_version: 2
type: DCM_PROJECT
default_target: DEV
targets:
DEV:
account_identifier: xxxxxxxxxxxxx
project_name: DCM_DEMO.NEWSLETTER.DCM_POC_DEV
project_owner: ROLE_POC_DCM_DEV_DEPLOIEMENT
templating_config: CONFIG_DEV
PROD:
account_identifier: xxxxxxxxxxxxxxx
project_name: DCM_DEMO.NEWSLETTER.DCM_POC_PROD
project_owner: ROLE_POC_DCM_PROD_DEPLOIEMENT
templating_config: CONFIG_PROD
templating:
configurations:
CONFIG_DEV:
env_name: "DEV"
db_name: "DCM_POC_DEV"
wh_name: "WH_DCM_POC_DEV"
wh_size: "X-SMALL"
retention_days: 1
role_admin: "ROLE_DCM_POC_DEV_ADMIN"
role_read: "ROLE_DCM_POC_DEV_READ"
role_owner: "ROLE_POC_DCM_DEV_DEPLOIEMENT"
CONFIG_PROD:
env_name: "PROD"
db_name: "DCM_POC_PROD"
wh_name: "WH_DCM_POC_PROD"
wh_size: "SMALL" # plus de puissance
retention_days: 5 # La PROD garde l'historique plus longtemps
role_admin: "ROLE_DCM_POC_PROD_ADMIN"
role_read: "ROLE_DCM_POC_PROD_READ"
role_owner: "ROLE_POC_DCM_PROD_DEPLOIEMENT"
Exemple de déclenchement de Plan :
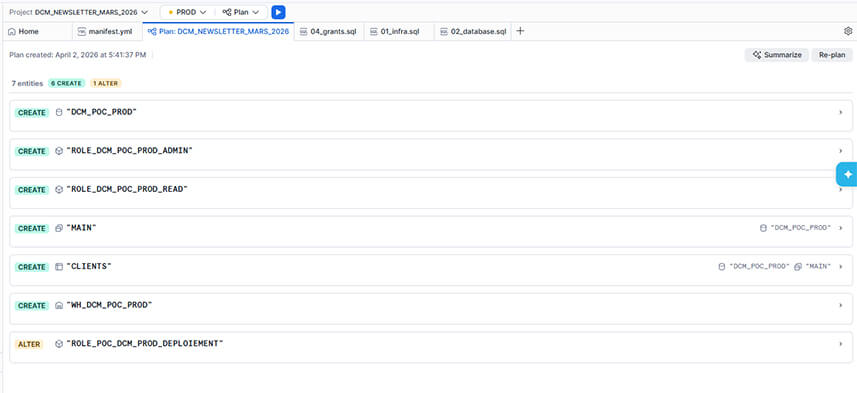
Le bandeau supérieur indique le bilan des opérations calculées par Snowflake : 6 créations (CREATE) et 1 modification (ALTER). Aucune suppression inattendue (DROP) n'est prévue, garantissant la sécurité du déploiement.
L'interface liste précisément l'infrastructure qui sera provisionnée : une base de données, des rôles RBAC spécifiques (ADMIN, READ), un schéma, une table (CLIENTS) et un entrepôt virtuel dédié (WH_DCM_POC_PROD)
2. Écriture sur les tables Iceberg par des moteurs externes (Preview)
Implications architecturales :
- Séparation du calcul (ETL) et de l'analytique : Les charges de travail d'ingénierie de données ou d'ingestion en continu peuvent être exécutées sur des clusters externes, tandis que Snowflake est utilisé pour le requêtage de ces mêmes données. Ce modèle évite la duplication physique des fichiers sur le stockage sous-jacent (S3, ADLS, GCS).
- Maintien du catalogue centralisé : Les transactions d'écriture initiées par les moteurs externes sont validées par Snowflake. Les métadonnées, le contrôle de concurrence (verrous) et l'application des règles de gouvernance sont maintenus par Snowflake Horizon.
- Protocole de connexion : L'interaction entre les moteurs externes et le catalogue Snowflake s'effectue via le standard REST Catalog API d'Iceberg et requiert la configuration d'une authentification OAuth.
3. Évaluation des agents Cortex (General Availability)
Depuis le 13 mars, la fonctionnalité d'évaluation des agents Cortex est en disponibilité générale (GA). Snowflake intègre nativement un framework d'évaluation ("LLM-as-a-judge") pour mesurer de manière automatisée et quantitative la fiabilité de vos agents IA en production.
Les capacités de l’outil :
- Exactitude (Answer correctness) : Vérifie la pertinence des réponses de l'agent en les comparant à un jeu de données de référence (ground truth).
- Cohérence logique (Logical consistency) : Audit autonome (sans données de référence) qui vérifie la cohérence entre les instructions de l'agent, sa planification et ses appels d'outils.
- Métriques personnalisées : Possibilité d'injecter vos propres règles métier et grilles de notation via un simple fichier de configuration YAML.
-
Intégration LLMOps : Le système restitue les scores, la justification du juge LLM, et la consommation de tokens. Exécutable via Snowsight ou SQL, le processus s'intègre naturellement dans vos chaînes CI/CD pour bloquer les régressions.
Les Actualités Mineures
- AI_COMPLETE pour l'analyse documentaire (Preview) : La fonction d'inférence
AI_COMPLETEprend désormais en charge les documents non structurés. Il est maintenant possible de traiter et d'extraire des informations de contrats ou de rapports directement via SQL. - Network Policy Advisor (GA) : Un outil d'administration stabilisé permettant d'analyser et de simuler l'impact de vos règles de sécurité réseau (IP allowlists) avant leur application, limitant ainsi le risque de blocage accidentel des utilisateurs.
- Granularité horaire des anomalies de coûts : L'interface d'investigation des anomalies de facturation intègre une vue horaire par type de service, facilitant l'identification rapide du traitement responsable d'un pic de consommation.
- Support d'Apache Iceberg™ v3 (Preview) : Prise en charge de la dernière spécification du format ouvert, incluant la gestion des types de données complexes (géographiques, horodatages en nanosecondes) et les deletion vectors pour optimiser les mises à jour.
- Connecteur Openflow pour Google BigQuery (Preview) : Ajout d'un connecteur natif simplifiant l'ingestion de données depuis l'écosystème GCP vers Snowflake.
- AI code suggestions (Preview) : L'assistance IA s'intègre directement dans les Workspaces pour accélérer la saisie de code SQL et Python.
Agenda : Les prochains rendez-vous
→ 16 Avril 2026 : Snowflake Connect : Analytics (Virtuel). Session technique dédiée à l'accélération des analyses et à l'intelligence décisionnelle.
→ 21 Avril 2026 : Snowflake AI Pulse (Virtuel)
→ 22 Avril 2026 : Snowflake Connect : Building Transformation Pipelines (Virtuel). Focus sur la création de pipelines de données prêts pour l'IA (Snowpark, Dynamic Tables).
→ 18 - 29 Mai 2026 : Accelerate Virtual Event Series (Virtuel). Une série de webinaires spécialisés par secteur d'activité (Finance, Retail, Santé, etc).
→ 1 - 4 Juin 2026 : Snowflake Data Cloud Summit '26 (San Francisco). Le rendez-vous mondial majeur.
→ 7 Octobre 2026 : Snowflake World Tour (Paris)
Documentations
Majeurs
DCM Projects :
Apache Iceberg écriture avec moteur externe :
- Mar 16, 2026: Apache Iceberg™ tables: Write support by using an external query engine (Preview)
- Access Apache Iceberg™ tables with an external engine through Snowflake Horizon Catalog
Cortex Agent évaluation :
- Getting Started with Cortex Agent Evaluations
- Cortex Agent evaluations
- Cortex Agent Evaluations: Monitor, Measure and Improve Your AI Agents on Snowflake
Mineurs
AI_COMPLETE :
Network Policy :
OpenFlow connecteur BigQuery :
AI Code suggestion :
Support Iceberg v3 :
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ? Rendez-vous sur la page Contact.