

Nous vous proposons un petit tour d'horizon des nouveautés Talend.
Fin de vie des versions Talend / Remote Engines
Versions Talend
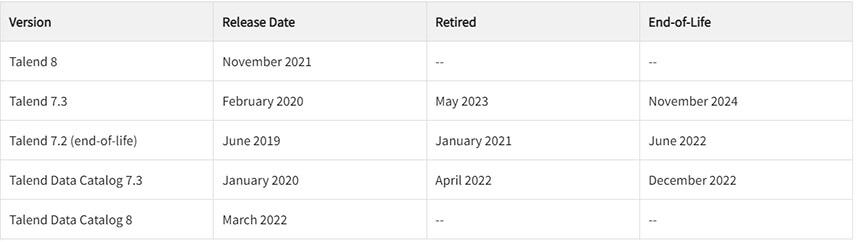
Attention, si vous êtes sur Talend 7.2, cette version n'est plus supportée depuis juin 2022.
Vous pouvez facilement connaître votre version de Talend dans votre Studio.
1) Cliquez sur Aide > À propos de Talend Studio
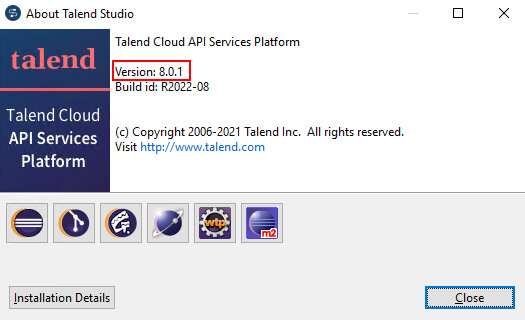
2) L'information est alors accessible ici :
N’hésitez pas à nous contacter en cas de question ou de besoin de migration.
Remote Engine
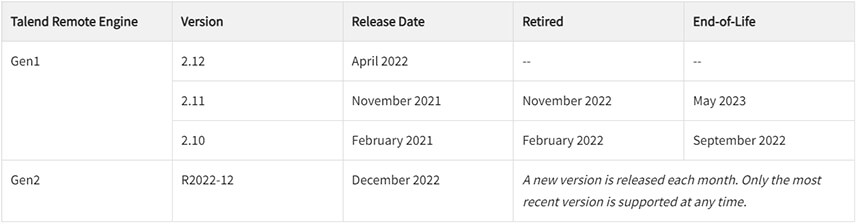
Compatibilité entre les moteurs d'exécution et le Talend Runtime
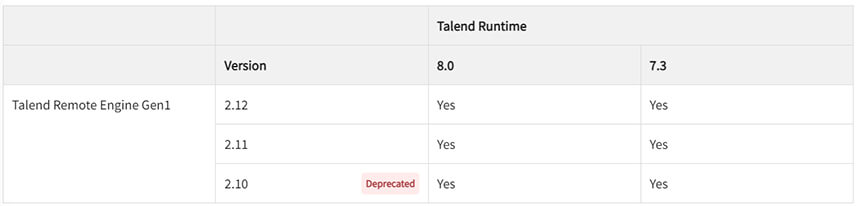
Attention, les Remote Engines en version 2.10 sont dépréciés et il est fortement conseillé de passer à la version 2.12.
Encore une fois, n’hésitez pas à nous contacter en cas de question ou de besoin de migration.
Toutes les informations de compatibilité sont disponibles sur le portail de support Talend.
Prérequis logiciels
Nouveautés
- Ajout du support de Rocky Linux 8
- Ajout du support de Windows Server 2022
Régressions
- Support déprécié de CentoOS Linux pour tous les modules Talend
Talend Studio 8.0
- Ajout du support d'Apple MacOS Monterey 12 et Ventura 13
Talend Data Integration
Nouveautés
Avec la version 8.0 de Talend, la connexion au studio se fera désormais via un jeton de sécurité, sans avoir besoin de saisir le nom de l’utilisateur.
- Nouveau composant tSAPADSOOutput, qui vous permet d'écrire des données dans un Advanced Data Store Object (ADSO) actif, via SAP Java Connector version 3
- Support de Microsoft SQL Server version 2019, ce qui permet d'utiliser l'authentification Azure Active Directory lors de la connexion à une base de données Microsoft SQL Server
- Amélioration des composants tFileOutputJSON et tWriteJSONField
- Support du type de données dynamique (dynamic datatype).
- Option évitant la notation scientifique pour les nombres
- Le mode de commit manuel Git est à présent activé par défaut dans le Studio Talend.
- Lorsque vous créez une branche, la nouvelle branche hérite du mode de commit Git de la branche source.
- Un nouveau mode de stockage Git a été ajouté. Il se base sur le stockage Git standard et améliore la manière dont les objets Git sont stockés, pour les dépôts et les projets. Cela permet d'économiser de l'espace disque et d'utiliser les commandes Git dans les outils Git pour gérer vos dépôts et vos projets.
- Lorsque vous générez la documentation pour un Job ou une Route, la documentation pour les Jobs, Joblets ou Routelets enfants est également générée.
- Ajout du support de Sybase 17
- Ajout des composants Azure Data Lake Storage Gen2 : tAzureAdlsGen2Delete, tAzureAdlsGen2Get et tAzureAdlsGen2Put
- Les composants Couchbase supportent à présent le protocole TLS et l'authentification Active Directory
- Si vous rencontrez des problèmes de réseau, vous pouvez désormais plus facilement modifier les paramètres de délai avant expiration de la connexion à la Talend Administration Center dans la fenêtre des Préférences.
- Les composants tSendMail et tPOP supportent l'authentification OAuth2
- Ajout de la connexion par authentification unique (SSO) au Studio Talend via Talend Cloud
- Le Studio Talend supporte les nouveaux composants suivants pour les connexions à Google Bigtable permettant de stocker ou récupérer des données :
- tBigtableInput
- tBigtableOutput
- tBigtableClose
- tBigtableConnection
- Ajout du support de Neo4j AuraDB
- Le Studio Talend supporte à présent Kafka 3.2.x
- Nouvelle option pour importer les dépendances directes lors de la modification de bibliothèques pour une routine, un bean, un JAR de routine personnalisée ou un JAR de bean personnalisé
- Ajout du composant tNeo4jv4ImportTool pour importer des données dans une base de données Neo4j 4.x
- Nouveaux composants de messaging pour établir des connexions aux systèmes Apache ActiveMQ et IBM WebSphere et effectuer des opérations de commit et de rollback :
- tMessagingClose
- tMessagingCommit
- tMessagingConnection
- tMessagingInput
- tMessagingOutput
- tMessagingRollback
- Le Studio Talend peut à présent lister les références invalides des projets dans la fenêtre des Preferences (Préférences), si vous vous êtes déjà connecté·e aux projets, ce qui vous permet d'identifier et de corriger les références invalides des projets avant d'activer le mode de stockage standard Git.
- Talend fournit un nouveau groupe de référentiels Nexus qui combine les bibliothèques et les référentiels centraux suivants en un seul groupe.
- Si vous utilisez un référentiel de proxy pour les bibliothèques dans le Studio Talend, vous devez utiliser l'URL de ce nouveau groupe de référentiels pour configurer le proxy.
- Ajout des composants SAP HANA dans tous les produits Talend avec souscription
- tSAPHanaClose
- tSAPHanaCommit
- tSAPHanaConnection
- tSAPHanaInput
- tSAPHanaOutput
- tSAPHanaRollback
- tSAPHanaRow
- Support de NetSuite v2021.x avec 3 nouveaux composants :
- tNetSuiteConnection
- tNetSuiteInput
- tNetSuiteOutput
- Ajout du support de PostgreSQL 15
Régressions
- Dépréciation de la version 3.* de SAP JCo de l'API SAP pour le tSAPConnection.
- Les composants Neo4j sont dépréciés dans le Studio Talend. Vous pouvez utiliser les composants Neo4jv4 à la place.
- Les versions Oracle 11, Oracle 12 et jusqu'à Oracle 17 sont dépréciées dans les composants Oracle.
- Les versions Oracle 8, Oracle 9 et Oracle 10 sont supprimées de la liste déroulante DB Version (Version de la BdD) dans les composants Oracle.
- Les versions 2011 et 2015 de la base de données CRM Microsoft on-premises sont dépréciées dans les composants MicrosoftCrm.
- Les versions 2007 et 2011 de la base de données CRM Microsoft online sont dépréciées dans les composants MicrosoftCrm.
- Les versions Oracle 11 et Oracle 12 sont dépréciées dans l'assistant de métadonnées Metadata pour Oracle.
- Les versions Oracle 8, Oracle 9 et Oracle 10 sont supprimées de l'assistant de métadonnées Metadata pour Oracle.
- L'intégration avec Talend Exchange dans le Studio Talend est dépréciée.
Talend Big Data
Nouveautés
- Support du pilote Redshift v2.x
- Vous pouvez à présent exécuter vos Jobs Spark sur Cloudera Data Engineering, à l'aide de Spark Universal avec Spark 3.1.x
- Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Databricks transitoire, à l'aide de Spark Universal avec Spark 3.1.x
- Vous pouvez à présent exécuter vos Jobs Spark à l'aide de Spark Universal avec Spark 3.2.x en mode Local
- Vous pouvez à présent exécuter vos Jobs Spark sur un cluster AWS EMR, à l'aide de Spark Universal avec Spark 3.1.x en mode Yarn cluster
- Vous pouvez à présent exécuter vos Jobs Spark en mode Standalone avec Spark Universal 3.2.x
- Support dans le Studio de l’API Delta Lake 1.0.0 pour Spark 3.1.x et Delta Lake 1.1.0 pour Spark 3.2.x
- Vous pouvez à présent exécuter vos Jobs Standard contenant des composants Hive sur un cluster Google Dataproc, à l'aide de Spark Universal avec Spark 3.1.x
- Vous avez à présent la possibilité d'ouvrir d'autres versions de vos Jobs et Joblets Spark Batch et Streaming dans le Studio Talend.
- Vous pouvez à présent exécuter vos Jobs Spark et Streaming à l'aide de Spark Universal avec Spark 3.2.x en mode Local et Standalone.
- Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur Cloudera Data Engineering, sur AWS et Azure, à l'aide de Spark Universal avec Spark 3.2.x.
- Support du pilote Redshift v2.0x pour les composants tRedshiftConfiguration, tRedshiftInput et tRedshiftOutput
- Avec la migration du composant API de Resilient Distributed Dataset (RDD) à Dataset (DS), vous pouvez à présent effectuer un mapping simple avec DS ainsi qu'avec RDD lorsque vous utilisez le tMap dans vos Jobs Spark Batch.
- Support de IDBroker avec Cloudera CDP Public Cloud
- Support du Principal de service Azure Active Directory (AD) pour les pools Azure Synapse Spark dans les Jobs Spark
- Le Studio Talend supporte à présent MongoDB v4+ avec Spark 3.1 et versions supérieures pour les composants suivants dans vos Jobs Spark Batch utilisant Dataset :
- tMongoDBInput
- tMongoDBOutput
- tMongoDBConfiguration
- Le Studio Talend supporte à présent MongoDB v4+ avec Spark 3.1 et versions supérieures pour les composants suivants dans vos Jobs Spark Batch utilisant Dataset
- Vous pouvez à présent exécuter vos Jobs Spark et Streaming à l'aide de Spark Universal avec Spark 3.3.x en mode Local.
- Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Amazon EMR, à l'aide de Spark Universal avec Spark 3.2.x en mode Yarn cluster.
- Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur des clusters Databricks transitoires et interactifs, sur Google Cloud Platform, AWS et Azure à l'aide de Spark Universal avec Spark 3.3.x.
- Vous pouvez à présent utiliser S3 Select avec le tFileInputDelimited et le tFileInputJSON lorsque vous utilisez le composant tS3Configuration comme composant de stockage dans vos Jobs Spark s'exécutant avec Spark Universal en mode YARN cluster (avec un cluster Amazon EMR) ou en mode Databricks. S3 Select vous permet de réduire le volume de données récupérées de S3 à l'aide de requêtes Spark SQL.
- Nouveau composant tManagePartitions permettant de gérer des partitions de jeux de données Spark dans des Jobs Spark Batch. Ce nouveau composant remplace tPartition qui est déprécié.
- Nouveau composant tCacheClear permettant de vider le cache Spark dans des Jobs Spark Batch
- Nouveau composant tHBaseDeleteRow permettant de supprimer des lignes depuis une table HBase
Régressions
- Les versions 11.5, 11.6 et 12.7 d'Oracle sont dépréciées dans le Studio Talend. Cette modification s'applique pour les composants suivants dans vos Jobs Spark :
- tOracleInput
- tOracleOutput
- tOracleConfiguration
- tOracleLookupInput (uniquement pour Spark Streaming)
- Les versions 8, 9 et 10 d'Oracle ne sont plus supportées dans le Studio Talend. La version minimale d'Oracle par défaut est la version 18.
- Cette modification s'applique pour les composants suivants dans vos Jobs Spark :
- tOracleInput
- tOracleOutput
- tOracleConfiguration
- tOracleLookupInput (uniquement pour Spark Streaming)
Talend Data Quality
Nouveautés
- Les composants de qualité de données peuvent s'exécuter sur Databricks avec Apache Spark 3.1, sauf le tDataEncrypt et le tDataDecrypt.
- Le composant tDataQualityRules supporte désormais Apache Spark 3.0 et supérieure en mode local ainsi que Cloudera Data Engineering service avec Apache Spark 3.1 et 3.2.
- Vous pouvez à présent utiliser une clé de 256 bits pour chiffrer ou masquer vos données. Cette fonctionnalité est disponible dans les composants :
- tDataEncrypt/tDataDecrypt
- tDataMasking/tDataUnmasking
- tPatternMasking/tPatternUnmasking
- La même clé est requise pour déchiffrer ou révéler les données.
- Les Routes sont à présent supportées dans la vue "Cloud Artifact" (Artefact Cloud)
- Vous pouvez à présent exécuter vos composants DQ avec Apache Spark 3.2 en mode local et dans Databricks.
- Vous pouvez à présent exécuter des composants Batch et Streaming de qualité de données avec Apache Spark 3.3 en mode local.
Régressions
- Les versions d’Oracle 11 et 12 sont dépréciées à partir de la version 8.0 R2023-01.
- Les versions d’Oracle 8, 9 et 10 ne sont plus supportées à partir de la version 8.0 R2023-01.
Talend Data Mapper
Talend Data Mapper est un outil capable de gérer des structures de données complexes tel que les formats JSON, XML, EDIFACT ou autre. C’est un outil qui s’améliore régulièrement. N’hésitez pas à venir vers nous si vous avez besoin d’aide pour manipuler ce type de donnée.
Nouveautés
- Ajout d’un nouveau type de map qui vous permet de créer une structure hiérarchique à partir d'une structure plate et de les mapper.
- Ajout d’une nouvelle fonction qui vous permet de créer une chaîne de caractères à partir d'une valeur numérique et de la formater à l'aide d'un modèle spécifique.
- Plusieurs nouvelles fonctionnalités sont disponibles dans Talend Data Mapper :
- StringInList : vérifie qu'une chaîne de caractères existe dans une liste de chaînes de caractères.
- SubstringBefore : retourne la partie d'une chaîne de caractères précédant une valeur donnée.
- SubstringAfter : retourne la partie d'une chaîne de caractères suivant une valeur donnée.
- AgConcatLastPresentValue : agrège des itérations de boucles et retourne la dernière valeur présente.
- ConcatLastPresentValue : retourne le dernier argument ayant une valeur.
Suppressions
- L'option de création d'une structure par import d'un fichier de classe Java ou d'un fichier JAR a été supprimée.
- L'option d'export d'une structure en tant que fichier de classe Java a été supprimée.
- Deux types de maps ont été supprimés dans cette version :
- Les maps de rapport XSLT
- Les maps inversées
Ces maps ne peuvent plus être créées. Cependant, les maps existantes créées avec ces types peuvent toujours être utilisées et modifiées.
- L'option Extract a New Inherited Map (Extraire la nouvelle map héritée) a été supprimée. Vous ne pouvez plus créer de map par héritage d'une map existante.
Intégration d'applications
Nouveautés
- Ajout de nouveaux composants de médiation pour faciliter les opérations sur les schémas et les bases de données :
- cSQL : Ce composant lit toute base de données via une connexion SQL et en extrait des champs à l'aide de requêtes.
- cSQLConnection : Ce composant ouvre une connexion à la base de données spécifiée afin de pouvoir la réutiliser dans la sous-Route suivante.
- cJsonParser : Ce composant extrait des données à partir d'un format JSON.
- cJsonWriter : Ce composant transforme les données entrantes en format JSON.
- cXmlParser : Ce composant extrait des données à partir d'un format XML.
- cXmlWriter : Ce composant transforme les données entrantes en format XML.
- cJsonValidator : Ce composant valide des données en se basant sur le schéma JSON.
- cXmlValidator : Ce composant valide des données en se basant sur le schéma XML.
Talend Cloud Management Console
Nouveautés
- Vous pouvez à présent planifier l'exécution de vos tâches et plans de Jobs de manière régulière sur une période de temps donnée, grâce aux déclenchements Cron.
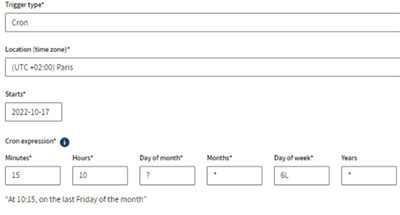
- Vous pouvez exécuter les mêmes tâches en parallèle sur un moteur distant unique v2.12.0 ou supérieure
- Dans le nouvel onglet Metrics (Métriques) de la page Run overview (Vue d'ensemble de l'exécution), vous pouvez voir les informations relatives aux composants des Jobs, comme le nombre d'enregistrements, ou encore le type des composants source et cible. Les Jobs doivent avoir été publiés ou republiés avec le Studio Talend en version 8.0.1 ou 7.3.1, avec la dernière mise à jour.
- La nouvelle colonne Error (Erreur) est disponible dans l'onglet Metrics (Métriques) dans la page Run overview (Vue d'ensemble des exécutions).
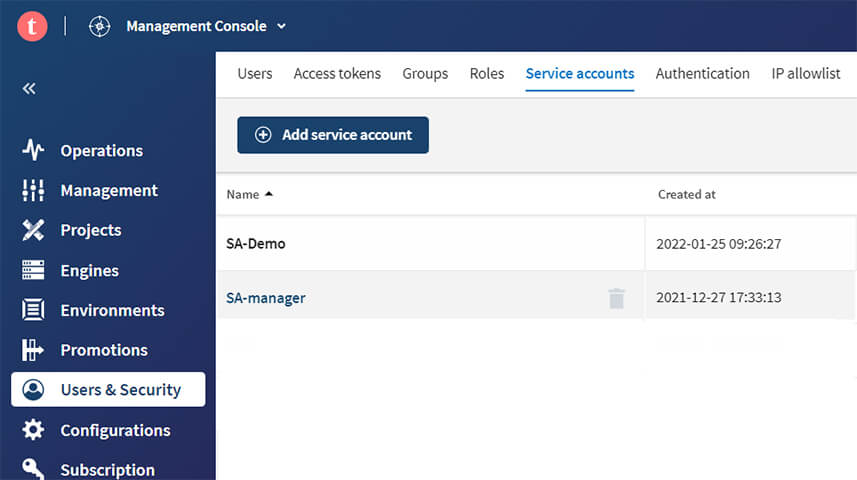
- Un nouvel onglet « Service account » est disponible. Il vous permet de créer facilement les comptes de service. Vous pourrez donner accès à vos jetons d’accès à ces comptes de service dans l’onglet « Access token ». Les comptes de service sont utilisables à travers l’API Talend Cloud Management.
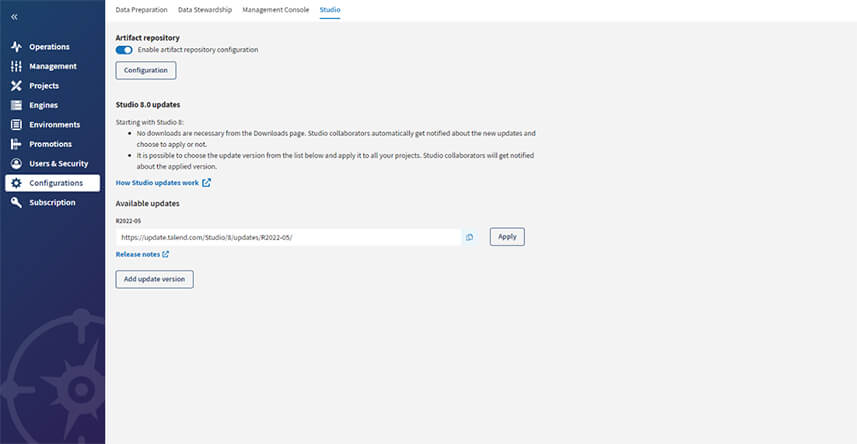
- Gestion des mises à jour du Studio directement dans la Talend Cloud Management Console. Votre Studio doit au moins être en version R2022-05 pour avoir accès à cette fonctionnalité. Attention, il est fortement conseillé de tester une mise à jour avant de la déployer et d’adopter une stratégie commune pour la gestion des versions.
- Il est désormais possible d’exporter les logs au format .txt ou JSON (uniquement via l’API Talend)
- Diverses améliorations de la Talend Cloud Migration Platform (TCMP).
La TCMP est un outil aidant les entreprises à préparer la transition de Talend On-Premise vers Talend Cloud.
Si vous souhaitez passer à Talend Cloud, contactez-nous pour que nous organisions votre migration dans les meilleures conditions.
- Vous pouvez définir plusieurs déclencheurs temporels pour chaque tâche ou plan.
- En plus des niveaux de configuration et d'exécution, vous pouvez à présent configurer un paramètre « timeout » (délai avant expiration) dans le niveau du déclencheur d'une tâche de Job.
Un délai avant expiration configuré sur un déclencheur s'applique uniquement à l'exécution de tâche démarrée par ce déclencheur. Il écrase le délai de suspension de la configuration de la tâche, si la tâche en a un.
Vous pouvez à présent définir le délai avant expiration de l'exécution des tâches. - Configurez la valeur du délai avant expiration dans l'étape Engine (Moteur) lors de l'ajout ou de la modification d'une tâche.
- Vous pouvez à présent définir le délai avant expiration d'exécution pour les déclenchements des tâches.
- Le délai avant expiration du déclenchement écrase le délai avant expiration de la tâche.
- Configurez la valeur du délai avant expiration dans l'étape Schedule (Planifier) lors de l'ajout ou de la modification d'une tâche.
- Vous pouvez à présent mettre en pause ou reprendre les exécutions de tâches et de plans, par exemple lorsque vous corrigez une erreur dans une tâche ou un plan ayant échoué ou au cours d'une période de maintenance, pour vous assurer qu'aucune exécution ne démarre pendant ces événements.
- Lorsque des tâches et des plans ciblant des moteurs Cloud sont en pause, le moteur Cloud n'est pas démarré et les jetons ne sont pas consommés.
- Provisioning SCIM (Gestion d'identité à travers inter-domaine) et mapping de rôles SSO
- Délai intelligent avant expiration des tâches
Vous pouvez à présent utiliser un délai intelligent avant expiration pour définir automatiquement une valeur de délai avant expiration pour vos tâches de Jobs.
Le délai intelligent avant expiration vous permet de terminer l'exécution d'une tâche automatiquement lorsqu'elle prend trop de temps, au lieu d'arrêter cette exécution manuellement.
Le seuil est calculé en se basant sur les exécutions précédentes réussies de la tâche. Pour pouvoir calculer le seuil, il faut qu'au moins 10 exécutions réussies soient terminées. - Ajout de la fonction copier/déplacer des tâches et plans
Régressions
- Fin de vie des sauvegardes des logs d'exécution dans un bucket Amazon S3
Talend Remote Engine
Nouveautés
- Dans les versions précédentes, les logs des sous-jobs ne remontaient pas (ou pas tout le temps) dans la TMC. Il est désormais possible de les afficher (pour les jobs publiés avec la version 8) via le paramètre « job.log.subjobs.logs = true » dans le fichier " RemoteEngineInstallationDirectory>/etc/org.talend.ipaas.rt.jobserver.client.cfg »
- Mise à niveau effectuée pour l’utilisation de Log4J 2.17.1.
- Un Talend Remote Engine a toujours été capable d'exécuter des tâches différentes en parallèle. Depuis la version v2.12.0, il supporte également l'exécution parallèle de tâches identiques.
- Vous pouvez ajouter les logs stdout et stderr des exécutions de vos Jobs aux logs Log4j pour en afficher les informations dans Talend Cloud Management Console.
- Monitoring de la consommation des ressources. La consommation des ressources de la machine de votre moteur est enregistrée dans RE_installation/data/log/statistics.csv.
- Vous pouvez à présent exécuter des tâches de services de données ou de Routes en tant qu'autres utilisateurs lorsque vous déployez un microservice sur un moteur distant ou un cluster.
- Vous pouvez à présent définir un profil d'exécution (personnalisation de la mémoire JAVA) pour les services de données ou les Routes lorsque vous déployez un microservice sur un moteur distant ou un cluster. Cela permet d’avoir une gestion plus fine des ressources machines consommées. (Cette fonctionnalité est supportée à partir de la version 2.12.4 du moteur distant en l’activant dans le fichier de configuration etc/org.talend.ipaas.rt.dsrunner.cfg)
- À partir de la version 2.12.8 du Remote Engine, vous pouvez chiffrer les paramètres de type mot de passe contenus dans le contexte d'une tâche de Job.
Talend Data Preparation
Nouveautés
- L'expérience utilisateur de la fonction de lookup disponible dans les préparations a été améliorée pour une utilisation plus intuitive. Vous pouvez l'utiliser pour mélanger des jeux de données et ajouter des données dans votre préparation courante.
- Les types sémantiques créés ou modifiés dans Talend Data Preparation et Talend Data Stewardship hybrides sont à présent automatiquement synchronisés avec les services de Talend Cloud
- Les types sémantiques créés ou modifiés dans les services Talend Cloud sont également synchronisés avec Talend Data Preparation et Talend Data Stewardship hybrides
- Le connecteur Box vous permet d'établir une connexion à la console de développement Box afin de récupérer ou publier des données depuis ou vers des fichiers Box.
- Les nouvelles possibilités d'exécution vous permettent de terminer le scénario complet de remédiation en libre-service. Nettoyez vos données via une préparation et mettez à jour le jeu de données sources pour améliorer sa qualité.
- Vous n'avez plus besoin d'exporter votre préparation en tant que fichier ou de l'importer manuellement dans Talend Cloud Data Inventory. À partir de maintenant, vous pouvez exécuter votre préparation pour envoyer les résultats directement dans votre inventaire de jeux de données.
Talend Cloud Pipeline Designer
Nouveautés
- Ajout du processeur « Field remover » qui permet de supprimer les champs indésirables dans les enregistrements d’entrée.
- Le connecteur Box vous permet d'établir une connexion à la console de développement Box afin de récupérer ou publier des données depuis ou vers des fichiers Box.
- Les types sémantiques appliqués à vos champs dans Talend Data Inventory dans un jeu de données sources ne sont plus réinitialisés à chaque étape du pipeline. Tout type sémantique appliqué à un champ dans votre jeu de données sources ou lors d'une étape, à l'aide du processeur de conversion de types est à présent propagé au reste du pipeline.
- Ajout du processeur Data Mapping (Mapping de données) qui permet de mapper graphiquement vos champs de pipelines avant d'écrire dans un jeu de données de destination structuré.
- Le processeur de jointure Join est amélioré pour afficher de manière graphique la branche de vos jeux de données de lookup sur l'espace de travail du pipeline. Vous avez à présent la possibilité d'effectuer des transformations sur plusieurs sources en ajoutant des processeurs sur chaque branche de lookup.
Régressions
À partir de décembre 2022, Talend Data Inventory nécessite une version 2022-02 ou supérieure du moteur distant (Remote Engine) Gen2.
Talend Data Stewardship
Nouveautés
- Les types sémantiques créés ou modifiés dans les services Talend Cloud sont également synchronisés avec Talend Data Preparation et Talend Data Stewardship hybrides
- Amélioration de l'expérience utilisateur pour les vues Tasks (Tâches) et Campaigns (Campagnes).
Et voilà, vous savez tout sur les nouveautés apportées par Talend ! Vous souhaitez une assistance ? Contactez-nous !
N'hésitez pas à faire appel à nos consultants experts certifiés Talend, ils sont là pour vous accompagner, Contactez-nous !