


Spark est un framework, qui permet le travail sur les données de manière distribuée. C’est l’une des principales solutions de traitement de l’écosystème Hadoop. En liant Spark à Hadoop, il devient possible de répartir la charge de travail de données sur plusieurs serveurs, pour le stockage et le traitement. Cette configuration est très appréciée pour l’analyse de grands volumes de données.
Spark est un projet Open Source créé en 2009. Il a initialement été développé à l'Université de Californie, par l’AMPLab de Berkeley. En 2010, le code source a été remis à l’Apache Software Foundation qui est actuellement en charge de la maintenance du projet.
Tous les grands éditeurs de distributions Hadoop proposent un support pour Spark : Cloudera, MapR, Hortonworks.
Les composants Spark
- Spark, pour travailler sur des données en Batch
- Spark Streaming, pour travailler sur des flux de données
- Spark MLlib, un ensemble d’algorithme pour faire du Machine Learning
- Spark SQL, permet de travailler les données avec du SQL
- Spark GraphX, permet de manipuler les données en mode graphe
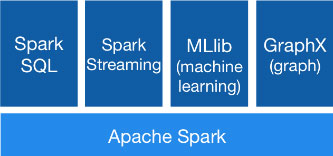
Chaque facette du framework Spark peut être complémentaire en fonction des différents cas d’usages. Il va vous permettre de tirer parti des données de votre entreprise, des données exogènes ou encore manipuler les données issues de l’internet des objets. Avec Hadoop, Spark permettra de construire un Datawarehouse ou un Data Lake. L’objectif étant de pouvoir restituer les données de manière efficace, sous forme de tableau de bord ou avec des systèmes d’analyses avancés.
Les avantages de Spark
- Permettre de travailler sur de grandes volumétries de données sans augmenter les temps de traitement.
- Faire évoluer le système en fonction des besoins.
- Travailler avec des données de différents formats.
- Implémentation des nouveaux types de traitements : Streaming, Machine Learning, Graphe.
Les avantages de Spark par rapport à MapReduce
Spark est rapide :
- 10x plus rapide sur disque
- 100x plus rapide en mémoire
Spark simplifie le développement :
- Ecriture simplifiée des programmes
- Plus de méthodes natives
- La possibilité de travailler avec un shell interactif
- Un code plus efficient
Plusieurs modes de déploiement sont disponibles dans Spark :
- Mesos
- Yarn
- Standalone
- Local
Spark possède plusieurs modes de stockage :
- HDFS
- Google Cloud Storage
- HBase
- Hive
Stack unifié permet de travailler sur différentes structures de données :
- Batch
- Streaming
- Analyses Interactives
Spark supporte plusieurs langages :
- Scala
- Python
- Java
- R
Les différents cas d'usage de Spark
Pour un opérateur télécom, Spark sert à mettre en place une solution d’alerte de sécurité à partir de différentes sources de données : les médias sociaux, les enregistrements DNS, les logs des serveurs. Il peut rassembler ces différentes informations pour générer les rapports de sécurité pour ses clients. L’utilisation de Spark permet d’analyser des millions d’événements et de gérer l’intégration de nouvelles données en temps réel.
Dans le domaine de la diffusion TV sur le câble, Spark peut analyser les audiences en fonction de la diffusion des programmes, et ce pour des chaînes retransmises sur différents continents. En analysant à la fois des données des programmes et des métadonnées des téléspectateurs, il permet au diffuseur d’adapter ses programmes et les campagnes publicitaires.
Spark est utilisé dans le médicale pour l’analyse du génome humain. Il a permis de réduire le traitement de plusieurs semaines à moins d’une heure.
Dans quels cas utiliser Spark ?
Next Decision préconise l’utilisation de Spark dans la majorité des projets Big Data. C’est le couteau suisse du traitement de données, à la fois multifonction et performant.
Vous souhaitez bénéficier d'experts, de développeurs ou d'une formation sur Apache Spark ? Rendez vous sur la page Contact
Analysez des millions de données avec Apache Spark à Paris, Brest, Rennes, Nantes, La Roche Sur Yon, Angers, Le Mans, Niort, Laval, Lyon, Grenoble, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Agen, Bayonne, Montpellier, Perpignan, Toulon, Avignon, Ales...
Réalisez vos projets Big Data avec Spark en Bretagne, Région Parisienne, Île de France, Pays de la Loire, Centre-Val de Loire, Nouvelle-Aquitaine, Occitanie, Auvergne-Rhône-Alpes et Provence-Alpes-Côte d'Azur.