


Type de produit et caractéristiques de Qlik Replicate
Qlik Replicate, auparavant Attunity Replicate, est un module de la solution d’intégration Qlik Data Integration. Il facilite la mise en place de réplication temps réel depuis de multiples sources de données hétérogènes (MongoDB, MySQL, Microsoft Azure SQL Managed Instance, ODBC, etc.) afin d’améliorer l’intégration des données dans le système décisionnel ou d’accélérer la mise à disposition des données, voire le streaming de données à destination des structures type Data Lake.
Pleinement intégrée à la console d’administration Qlik Enterprise Manager, Qlik Replicate peut également se deployer en standalone.
Présentation et concept de Qlik Replicate
Qlik Replicate a un objectif : mettre en place une réplication de données. En ce sens, l’interface est très épurée et centrée autour de cet objectif.
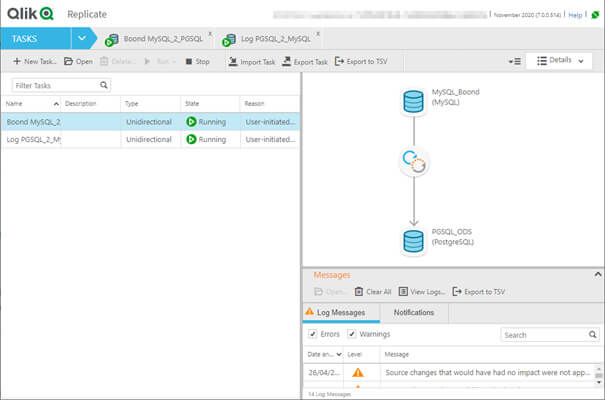
La simplicité d’usage de Qlik Replicate permet de déployer rapidement une réplication de données. Cette réplication peut être unidirectionnelle, bidirectionnelle ou une tâche de flux :
Le traitement unidirectionnel permet par exemple de couvrir les besoins décisionnels comme la mise en place d’un ODS (Operational Data Storage - Stockage de Données Opérationnelles) afin de fournir une zone d’exploration de données et une source de données à jour en temps réel pour l’alimentation d’un entrepôt de données.
Le traitement bidirectionnel peut couvrir un besoin technique de type migration des données d’une application métier et ainsi propager les modifications des données locales vers le cloud de Microsoft Azure, celui d’Amazon (AWS) ou encore Google Cloud. La réplication assure dans ce cas la phase « double run » de la migration, permettant d’avoir certains utilisateurs sur la version « locale » de l’application et d’autres sur la version « cloud ».
La tâche de flux de données (log stream) permet de stocker les modifications faites sur la source pour les propager vers plusieurs cibles. Cela peut faciliter la propagation d’une modification faite dans un MDM à destination d’un ERP et d’un CRM par exemple en mode échange inter-application.
La tâche de réplication peut fonctionner en chargement complet (initialisation des tables répliquées) et/ou en application des changements (en se reposant sur les logs de la base de données sources). Ceci permet de mettre en place facilement une architecture de type CDC (Change Data Capture – framework de récupération des données qui ont changé) et ainsi de profiter de modification en temps réel et de limiter les traitements nocturnes utilisant un gros volume de données.
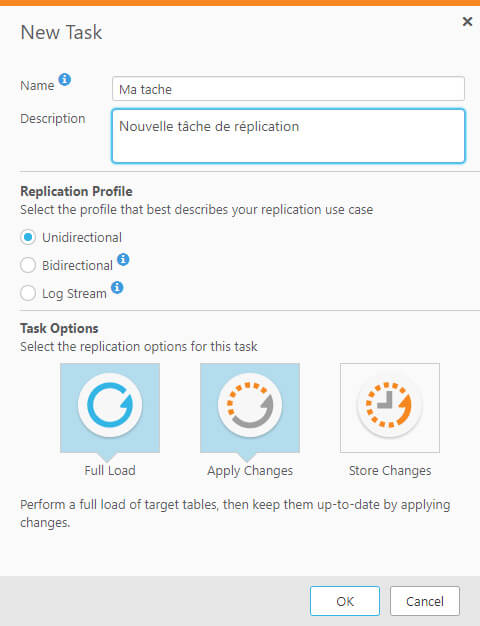
Une fois l’architecture mise en place, Qlik Replicate nécessite peu de compétences techniques. Il est possible de mettre en place des transformations simples telles que le renommage de la table, d’une colonne voire l’ajout ou la suppression d’une colonne.
Un assistant permet de le faire de manière très simple :
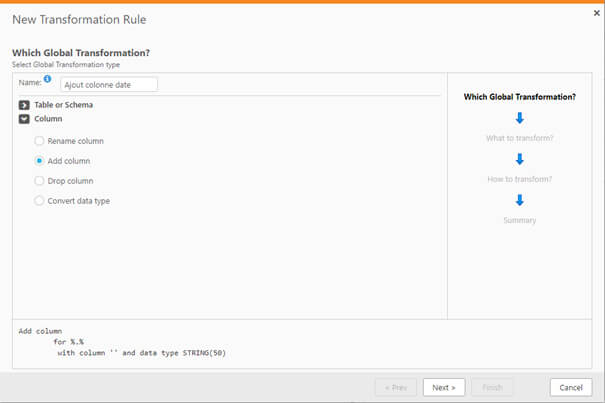
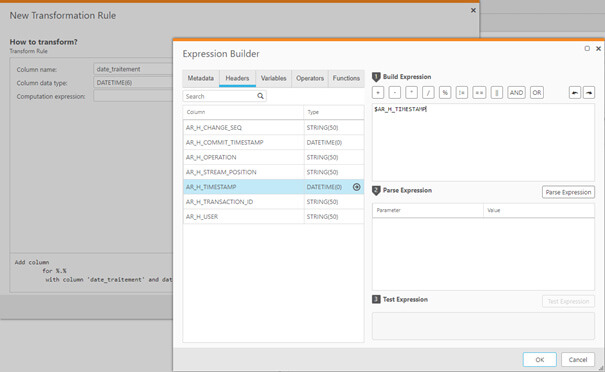
Ce qui peut permettre, en cas de besoin, d’améliorer la qualité des données entre la source et la cible de la réplication.
Le renommage de table ou de schéma facilite l’intégration de données disparates issues de bases de données d’environnements différents, sans risquer de conflit (nom de table, clef primaire, etc.)
Le monitoring des tâches se fait à travers différents écrans permettant d’identifier si une tâche s’exécute correctement ou non.
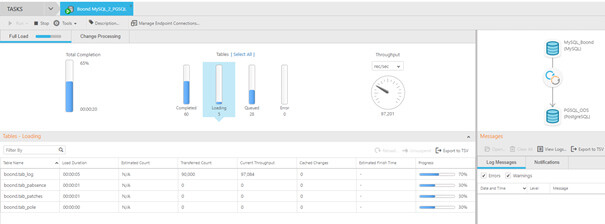
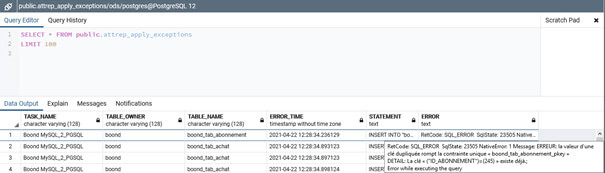
De plus, nativement, une table est créée dans la cible avec la liste des ordres SQL qui ne sont pas correctement passés avec le message d’erreur associé, afin d’en faciliter la ré-exécution si nécessaire :
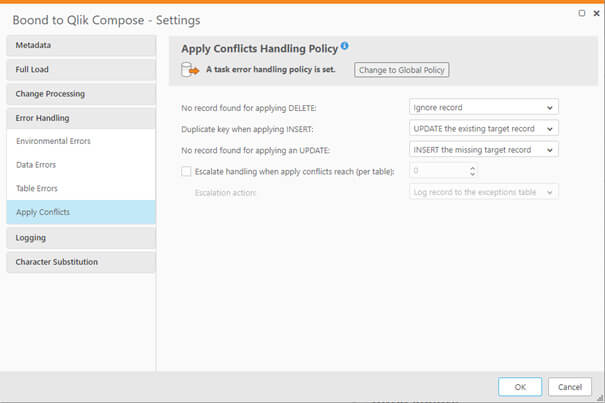
Il est possible d'automatiser la gestion des erreurs via une interface qui permet de déclencher des actions en fonction de l’erreur rencontrée :
Fonctionnalités principales de Qlik Replicate
- Réplication des données
- Temps réel ou batch
- Multiples technologies sources possibles (Oracle, PostgreSQL, MySQL, IBM, SQL-Server, cloud, SAP, Hadoop, Salesforce, etc.)
- Multiples technologies cibles possibles (Apache Kafka, Databricks, HDP, SGBD relationnels, Qlik Sense Saas, etc.)
- Intégration à Qlik Enterprise Manager
Avantages de Qlik Replicate
- Interface simple et parfaitement adaptée à l’objectif de réplication
- S’occupe de gérer les publications et souscriptions de la réplication des données
- Réplique tous les changements, dont les changements de structures des tables
- Gestion des alertes et des niveaux de logs simples
- Permet aisément de ne pas avoir des énormes volumes de données traitées par lot toutes les nuits
- Brique essentielle de la suite Qlik Data Integration
Dans quels cas utiliser Qlik Replicate ?
- Data ingestion : ingestion de données dans une zone d’exploration de données
- Réplication de données brutes unidirectionnel pour faciliter la construction d’un datawarehouse temps-réel ou alimenter une architecture Big Data
- Mettre en place une architecture unifiée d’échange de données à moindre coût
- Répliquer les données vers une technologie consommable par Qlik Compose
- Changement de technologie de stockage de données pour une application
Vous souhaitez bénéficier d'experts, de développeurs ou d'une formation sur Qlik Replicate ? Rendez vous sur la page Contact
Next Decision est revendeur et intégrateur Qlik Replicate à Nantes, Paris, Brest, Tours, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Montpellier, Lyon, Grenoble, Agen, Bayonne, Nîmes, Marseille, Aix-en-provence.
Des consultants Qlik Replicate en Pays de la Loire, Bretagne, la région Parisienne, Nouvelle-Aquitaine, Occitanie, île-de-France, Rhône Alpes et Provence-Alpes-Côte d'Azur, c'est Next Decision !