


Présentation et concept de Spark
Spark constitue la nouvelle brique In-Memory des distributions Hadoop. Grâce à la richesse de ses bibliothèques, Spark répond à vos besoins Big Data ou nécessitant des temps de réponse rapides ou encore de réaliser des calculs avancés. La solution Spark s'interface avec Yarn pour bénéficier des ressources allouées.
Type de produit et caractéristiques de Spark
Spark travaille en mémoire
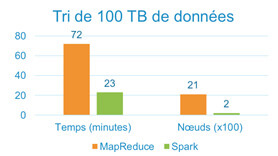
La méthode de traitement des données utilisée par Spark est beaucoup plus rapide que le MapReduce de Hadoop. Spark analyse toutes les données en mémoire presque en temps réel tandis que MapReduce va exécuter les opérations en plusieurs étapes. Spark est détenteur du record Daytona Graysort en 2014.
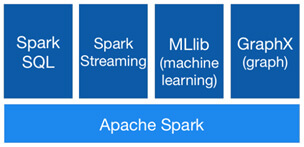
Spark intègre des outils d'analyse de données et de Data Science
Spark Streaming permet d'accéder à des données en temps réel via les outils suivants : Spark SQL pour interroger et modifier les données comme avec des requêtes classiques, Spark MLib pour des modèles de Machine Learning et GraphX pour le calcul et la création de graphes.
Spark s'intègre à de nombreux environnements
Spark peut être exécuté en mode standalone ou sur un cluster. Sur Hadoop, il est possible d’utiliser les ressources avec Yarn et de stocker des fichiers sous HDFS. Sur Apache Mesos ou Kubernetes. Il est également possible de l’utiliser dans le cloud.
Les principales sources de données utilisées sont Cassandra, HBase et Hive, mais il en existe des centaines d’autres.
Spark est basé sur un langage rapide, Scala
Scala est un langage objet et utilise la programmation fonctionnelle. Ce dernier étant régulièrement mis à jour, Spark bénéficie ainsi des améliorations et corrections apportées au langage.
Spark peut également être utilisé avec les langages Python, R et Java qui sont plus répandus.
Spark et le principe de "Lazy Evaluation"
Spark évalue les traitements si et seulement s'ils sont nécessaires lors de l'exécution. C'est le principe de Lazy Evaluation. Cela permet d'avoir un temps d'exécution plus rapide.
Fonctionnalités principales de Spark
Le cluster de Spark
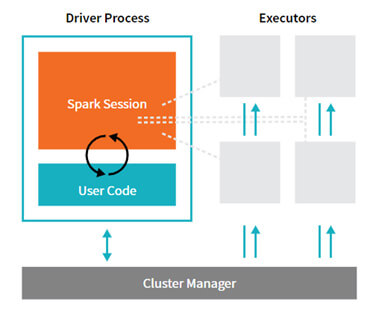
Le programme principal (driver) s’exécute sur l’un des nœuds du cluster. Il contient une Spark Session qui est le point d'entrée de l'application Spark créée. Le manager du cluster (par exemple Yarn, si Spark est déployé sur un cluster Hadoop) attribue les tâches aux workers qu’ils vont exécuter.
A noter : Avant la version 2.0 d'Apache Spark, seule la notion de Spark Context (SC) existait comme point de communication avec l'application. Depuis cette mise à jour, la Spark Session a été créée afin d'unifier l'accès aux RDD, Dataframes et Datasets, dont nous expliquons le fonctionnement dans le paragraphe suivant.

Spark et le concept des Resilient Distributed Datset (RDD)
Un RDD est une collection distribuée d’objets de même type (RDD d’entiers, de chaines de caractères, d’objets Scala/Java/Python) et est l’équivalent in-memory du stockage HDFS. Les donées stockées par un RDD peuvent être non structurée, sans schéma imposé, comme les flux de médias. On peut contrôler leur partitionnement et leur persistance.
Il existe trois méthodes pour créer un RDD :
=> Via une collection d’objets à partir du programme appelant à l’aide de la méthode "parallelize" :
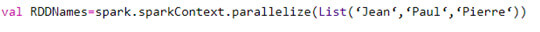
=> Par la création depuis la lecture d'un fichier :

=> Et enfin via la transformation d'un RDD existant :

À noter : Depuis Apache Spark 2.0, de grandes évolutions autour des RDD ont eu lieu. Les Dataframes et Datasets ont été mis en place, ne dépréciant pas l'usage des RDD mais les complétant.
Spark différencie deux ensembles de données :
- Non typé : Dataframe qui est une collection immutable et distribuable (comme un RDD) non typé où les données sont organisées en colonne. Il permet d’obtenir une vue personnalisée et structurée, de données semi-structurées.
- Fortement typé : Dataset, qui est une collection immutable et distribuable d’objets fortement typé, dicté par une classe que l’on définit en Java ou Scala. Il apporte une sécurité de types des saisies dès la compilation du code, permettant au développeur de gagner du temps et des réduire ses coûts.
Le niveau d’abstraction des Dataframes et Datasets est de haut niveau contrairement aux RDD, ce qui facilite leur utilisation.
Grâce à un optimisateur de code unique, les Dataframes et Datasets permettent de gagner en vitesse d’exécution et en optimisation d’espace en mémoire.
En Python et R, seuls les Dataframes sont accessibles parmi ces deux objets.
Propriétés des RDD
Les Transformations pointent vers le RDD dont elles sont issues. Spark enregistre l’enchaînement des transformations (DAG : Directed Acyclic Graph) mais n’exécute pas tout de suite les opérations.
Quelques exemples de transformations : map(func), filter(func), join(otherDataset, [numTasks]), reduceByKey(func), sortByKey([ascending],[numTasks])…
Les Actions déclenchent l’exécution des transformations, elles retournent une valeur ou écrivent dans un fichier. Par exemple words.first() va retourner le premier mot du RDD.
Il existe aussi un système de tolérance aux pannes, à savoir que si les données en mémoire sont perdues, le RDD est recréé à partir du Directed Acyclic Graph (DAG) ou Graphe Orienté Acyclique.
Bien que Spark privilégie la mémoire, il est possible de lui demander de stocker certains résultats intermédiaires sur disque afin d’avoir des données persistantes.
Autres utilisations de Spark
Spark et la persistance des RDD
On peut indiquer à Spark de stocker un RDD. L’intérêt est de ne pas avoir à recalculer plusieurs fois le même RDD (par exemple pendant une phase de prototypage).
On applique la fonction persist() à un RDD en indiquant le niveau de stockage. On peut également utiliser la fonction cache() qui stocke le RDD en mémoire.

Les variables distribuées : Broadcast
Si l’on a besoin d’une variable sur tous les nœuds, il est nécessaire de la passer en paramètre de notre fonction. On peut dans certains cas la distribuer avec la fonction broadcast. La distribution de données est très utile par exemple dans le cadre de jointure. On va ainsi distribuer la plus petite variable sur tous les nœuds, ce qui va permettre de faire des jointures « locales » avec la variable principale.

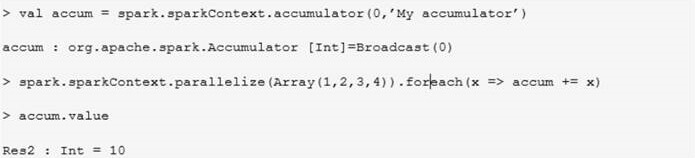
Les variables partagées : Accumulator
Un accumulator est une variable partagée sur plusieurs nœuds qui supporte uniquement des opérations associatives. On peut l'utiliser par exemple pour créer un compteur dans les algorithmes.
Shuffle operations
Certaines opérations comme "ReduceByKey" entraînent une réorganisation des données : c'est le "Shuffling". Ceci a un impact sur les performances, comme pour MapReduce, les données doivent être lues avant d'être regroupées par clé. Si les données ne tiennent pas en mémoire, elles seront écrites sur disque, ce qui va faire chuter les performances.
Ces opérations génèrent de nombreux fichiers temporaires, beaucoup d'espace disque peut ainsi être rempli si les traitements sont longs.
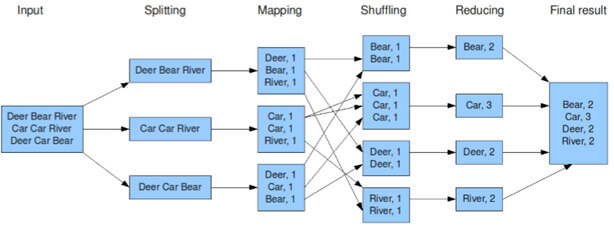
Le schéma ci-dessus représente le processus de MapReduce.
Comme avec le MapReduce, il faut que les traitements Spark se basent sur les données locales. C'est pourquoi, dans le cas de Hadoop par exemple, on déploie le service Spark sur l'ensemble des datanodes du cluster.
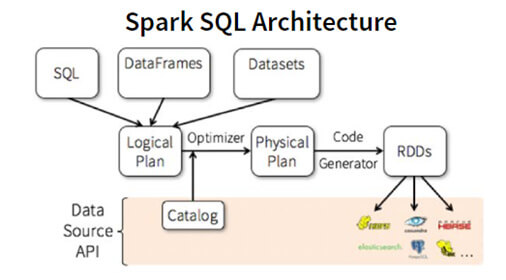
Spark SQL
Présentation de Spark SQL
Spark SQL permet le traitement et l’exploitation de données structurées.
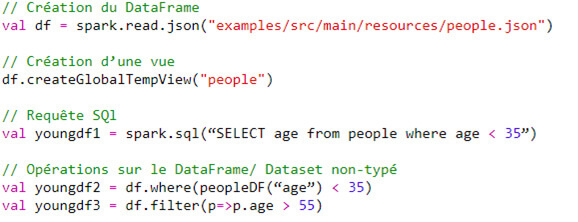
On peut y accéder via les Dataframes ou Datasets comme détaillés précédemment ou par des requêtes SQL :
Spark Streaming
Présentation de Spark Streaming
Spark Streaming permet de traiter des flux de données en provenance de différentes sources. On parle ici de micro-batch car les données sont traitées dans une fenêtre de temps à paramétrer dans notre programme.
Exemples de cas d'usages : analyse de logs, analyse de tweets…
Après avoir récupéré les données, il est possible d'effectuer des traitements plus classiques.

Les données sont capturées dans des "blocs" de RDD, les DStream (Discretized Stream).

Les transformations sont ensuite effectuées sur chaque DStream.
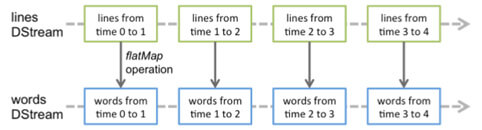
Certaines opérations ne sont pas permises sur les DStream. Il n'est pas possible par exemple de faire une jointure entre un DStream et un RDD. Pour réaliser cette opération, il faut passer par la fonction transform() :

Par défaut, les transformations opèrent sur les données récoltées sur la période du micro-batch, mais il est possible de traiter de manière globale plusieurs périodes de micro-batchs :
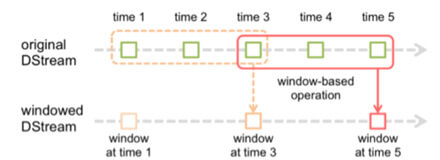
Opérations sur une fenêtre Batch
Spark MLLIB (Machine Learning Library)
MLlib est une bibliothèque de Machine Learning distribuée et implémentée par Apache Spark. Elle propose tous les algorithmes communs d’apprentissage automatique comme la classification, la régression, le clustering, … de la préparation des données, l’entrainement du modèle à ses prédictions et son évaluation.
Cette bibliothèque est ainsi accessible pour tout développeur créant déjà des modèles avec scikit-learn ou keras.
Le modèle de Machine Learning peut supporter des données très variées grâce aux Dataframes : vecteurs, images, texte, données structurées.
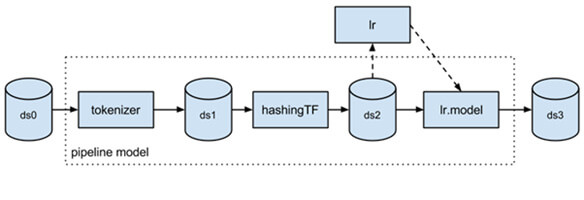
Il est aussi possible de réaliser des ML Pipeline, un enchaînement d’algorithmes de traitement de données et d’apprentissage, exécutés dans un ordre spécifique. Il est constitué de :
- Transformateurs : converti un Dataframe en un nouveau, en de le transformant. Par exemple, cela peut être par l’ajout de colonne
- Estimateurs : permet d’entrainer les données
Ils ont un identifiant unique, leur permettant de spécifier les paramètres plus facilement.

GraphX - GraphFrames
Ce module de Spark s’appuie sur la théorie des graphes. Un graphe est défini par un modèle de réseaux reliant des objets avec un sens spécifique. Il composé de sommets portant l’information et d’arrêtes entre ces derniers. Cette théorie est très utilisée dès qu’il s’agit de traiter une question liée à un réseau d’informations comme lors de la réalisation d’un moteur de recommandation.
GraphFrames s’appuie sur les Dataframes, conservant ses avantages notamment sur les questions d’optimisation de la mémoire et de la vitesse d’exécution. Il est accessible depuis Java, Scala et Python.
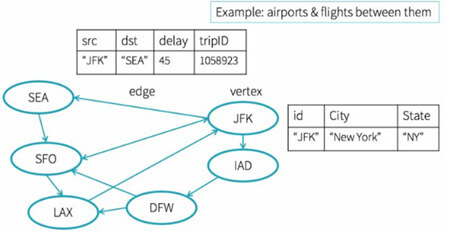

A noter : GraphFrames est une bibliothèque analogue à GraphX (disponible uniquement en Scala) mais s'appuyant sur une abstraction de plus haut niveau.
Retour aux éditeurs du Big Data
Vous souhaitez bénéficier d'experts, de développeurs ou d'une formation sur Spark ? Rendez vous sur la page Contact
Expertise, conseil, et formation sur Nantes, Angers, Paris, Niort, Brest, La Roche Sur Yon, Le Mans, Lyon, Grenoble, Saint-Etienne, Bordeaux, Angoulême, Toulouse, La Rochelle, Agen, Bayonne, Nîmes, Montpellier, Marseille, Aix-en-¨Provence…
Des experts en Spark en Région Pays de la Loire, région Parisienne, Ile de France, Bretagne, Normandie, Nouvelle-Aquitaine, Occitanie, Provence-Alpes-Côte d'Azur...