


Type de produit et caractéristiques d'Hadoop Big Data
La technologie Hadoop est un framework JAVA, projet open source, prédisposé à faciliter la réalisation d’applications distribuées et le stockage de données sous un mode colonne. Il permet, entre autres, de travailler, déployer des traitements sur l’ensemble des nœuds d'un cluster. Apache est le précurseur de cette technologie innovatrice qui sera la source ou plutôt l'inspiration de nombreuses solutions big data.
Présentation et concept d'Hadoop
Les SGBD traditionnels ne peuvent pas traiter des volumes de teraoctets de données. Seul l’usage de technologies telles Hadoop permet d'affronter des masses de données dont certaines sont parfois des données non-structurées. Hadoop, solution Big Data, par nature même, est un entrepôt de données disponible pour des énormes volumes de données. L'entrepôt peut être interrogé par query dans des langages propres ou en SQL. Aussi, les frameworks Open-source Hadoop sont nommés NoSQL pour Not Only SQL.
Fonctionnalités principales d'Hadoop
Hadoop n’est pas un seul et unique projet. Tout un ensemble de sous-projets est mis à disposition du grand public. On peut noter 3 «principaux» composants :
- Hadoop Common : composants communs permettant de gérer les systèmes de fichiers distribués. Beaucoup de modules se basent sur ce projet.
- HDFS (Hadoop Distributed File System) : Un système de fichiers distribués conçu pour gérer de grosses volumétries. l'HDFS pratique la réplication des données massives.
- MapReduce : un framework logiciel qui facilite la réalisation d’applications capables de fonctionner dans un environnement clustérisé.
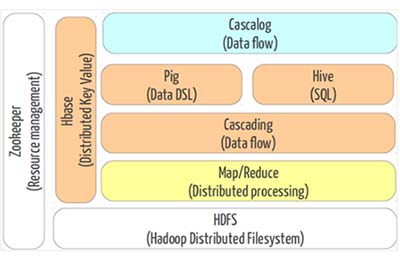
D’autres projets sont basés sur Hadoop à savoir :
- HBase : base de données vectorielle et distribuée (et donc résiliant aux pannes), orientée colonne créé pour gérer des Téraoctets de données brutes.
- Hive : logiciel permettant la requête, analyse des données contenues dans un datawarehouse Hadoop. L’exécution des requêtes s’effectuent via MapReduce afin de réduire le temps de traitement. Cet outil permet d’interroger aisément les données grâce à son langage HiveQL proche de la syntaxe SQL.
- Impala : interface de gestion des données qui permet d'interroger la base en SQL.
- Pig : outil d’analyse, traitement des données stockées par le biais de scripts.
- Zookeeper : permet la coordination des différents services au sein de l'application Hadoop.
- Ambari : monitore, gère le cluster Hadoop via une interface web.
- Et bien d’autres outils liés à la suite Hadoop et présentes dans le projet Apache.
Dans quels cas utiliser Hadoop ?
Next Decision préconise l’écosystème Hadoop comme système de stockage dès lors qu’une entreprise souhaite :
- Traiter en temps réel ou non de nombreuses données, qui, de plus, sont non structurées.
- Une architecture évolutive en parfaite scalabilité au fil du temps.
- Affronter des projets de type Big Data particulier dans des projets décisionnels avec des données exogènes à la société.
- Il est aussi possible, pour certains cas d'application, de trouver des bases Hadoop disponibles dans le Cloud ou sur des infrastructures as a service (IAAS, PAAS et parfois SAAS). Cette option ne doit pas être négligée par les développeurs car elle permet d'accélérer massivement une implémentation d'un projet d'intégration de données. Next Decision peut préconiser dans ces cas des infrastructures Amazon, Google Cloud Platform (GCP), Microsoft Azure mais aussi les accélérateurs de la stratégie digitale comme SAAGIE.
Retour aux éditeurs "Plateforme de données"
Vous souhaitez rencontrer des experts sur Big Data, ou bénéficier d'une formation Big Data sur Hadoop ? Rendez vous sur la page Contact
Conseil en stockage sur Hadoop à Brest, Nantes, Toulouse, Paris, Rennes, La Roche Sur Yon, Angers, Le Mans, Niort, Laval, Lyon, Grenoble, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Agen, Bayonne, Montpellier, Nîmes, Marseille, Aix-en-provence...
Next Decision pratique Hadoop - Big Data en Bretagne, Pays de Loire, Région Parisienne, Ile de France, Occitanie, Grande Aquitaine, Poitou-Charentes, Aquitaine, Midi-Pyrénées, Rhône, Ain, Isère, Loire, Languedoc-Roussillon et Provence-Alpes-Côte d'Azur.