


IBM Watson Studio, c'est ainsi qu'est baptisée la plateforme IBM pour le Big Data et l'intelligence artificielle, proposée en self-service sur le cloud. Rencontre avec Lisa Neddam, en charge du développement commercial de la plateforme chez IBM pour l’Europe, qui nous en présente les fonctionnalités.
Qu'est-ce qui a amené IBM à créer la plateforme Watson Studio ?
De nos jours, l'innovation est un sport d'équipe. Innover dans les domaines de la donnée et de l'AI (intelligence artificielle) nécessite des méthodes et des outillages permettant aux différents acteurs impliqués dans le processus d'innovation de travailler ensemble de manière agile, effective et sécurisée. C'est tout l'enjeu de la plateforme IBM Watson Studio.
Quelques mots pour nous présenter la plateforme IBM Watson Studio ?
La plateforme Watson Studio propose un ensemble d'outillages qui va permettre d'adresser le développement de cas d'usage autour de la donnée et de l'AI. Comment ? En offrant aux différents protagonistes du processus d'innovation la possibilité d'une part, de collaborer en travaillant en mode self-service mais avec de la gouvernance et, d'autre part, d'adresser aussi bien les phases d'expérimentation que les phases de mise en production des projets d'innovation.
Quelles sont pour vous les principales différences entre la BI et le Big Data ?
Une des principales différences entre BI et Big Data réside dans le type de données traitées. La BI s’intéresse à de la donnée structurée, de la donnée froide. On peut parler de "démarche rétroviseur" : on regarde ce qui s'est produit dans le passé et on construit des KPI. Le Big Data permet quant à lui de sortir de ce type de données, d'avoir de la donnée en mouvement, de la donnée en contexte. On va au-delà de la démarche BI, on s'oriente vers du prédictif, la data science, le deep learning, voire l'intelligence artificielle.
A qui s'adresse la plateforme IBM Watson Studio ?
La plateforme IBM Watson Studio s'adresse aux différents professionnels de la donnée :
L’ingénieur données dont le rôle consiste à avoir accès à la donnée, à la préparer et à la mettre en forme de manière à ce qu'elle puisse être utilisée dans les analyses de data science.
Le data scientist qui va s’intéresser au fond des données préalablement mises en forme. Son approche souvent très mathématique vise à en extraire du sens et à construire des modèles complexes.
Deux types de profils métiers :
- Le business analyst travaille avec les données en mode Excel ou en mode BI. Ce n'est pas quelqu'un de technique type codeur, mais il apporte la compréhension business.
- L'expert domaine a la compréhension de certains des processus métiers qu'on cherche à modéliser. C'est lui qui dans le cadre d'une application qui fait de la reconnaissance d'images, entraînera la machine à distinguer, par exemple, une image d'une voiture en bon état, d'une image d'une voiture en mauvais état.
Le développeur prend les résultats des analyses de data science pour développer des applications (application mobile, application web, API utilisée dans le cadre d'un processus, etc.)
Le data steward définit les règles de gouvernance : il décide de qui au sein de l'entreprise, a accès à certaines données, qui peut voir les données, qui peut les transformer, les utiliser... Il va aussi éventuellement mettre en place et maintenir les dictionnaires, les vocabulaires qu'on utilise dans le cadre de ces processus d'indexation de la donnée.
Quelles sont les principales fonctionnalités de la plateforme IBM Watson Studio ?
Les principales fonctionnalités sont les suivantes :
Outillage de préparation de préparation des données
La préparation de données se fait via un ETL self-service.
Outillage de création de modèles de data science et de deep learning
Cet outillage se compose d'une part, d'un ensemble d'outils open source et d'autre part, d'un ensemble d'outils propriétaires d'IBM. Dans les outils open source, assez orientés "code", on retrouve notamment des notebooks tels que que Jupyter, avec des librairies et du code (possibilité de coder en Python) Les outils propriétaires d'IBM, moins orientés "code, fonctionnent plutôt en mode "drag and drop" (spss modeler par exemple). Certains sont spécifiquement dédiés au deep learning : des librairies comme TensorFlow avec des modèles d'exécution adaptés au deep learning (exécution gpu notamment).
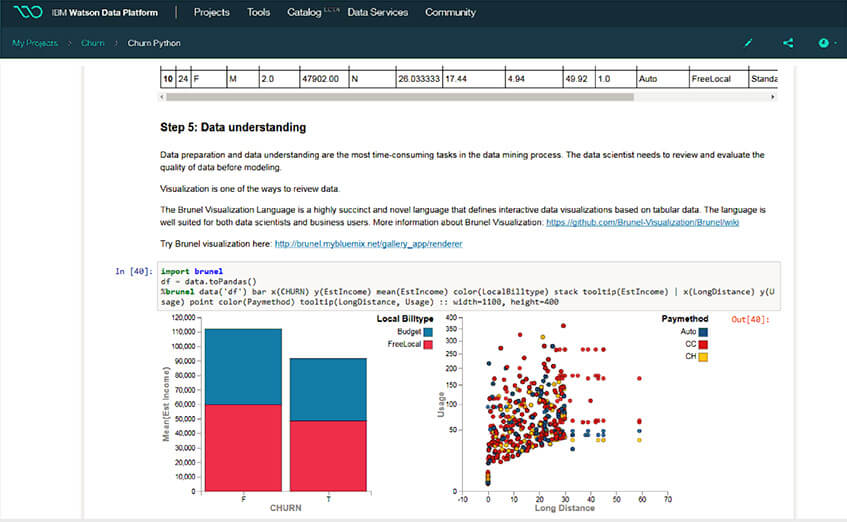
Notebooks – Source IBM Watson Studio
Un catalogue de métadonnées avec son outillage de gouvernance
La plateforme IBM Watson Studio offre la possibilité de créer un catalogue d'indexation de l’ensemble des datas assets disponibles au sein de l'entreprise, de l'organisation ou d'une équipe. Il permet de rechercher les assets en langage naturel, peu importe qu'ils soient stockés sur un cloud IBM ou sur un autre cloud.
La plateforme permet également la création de règles de gouvernance pour définir qui a accès aux data assets, qui peut les transformer, etc.
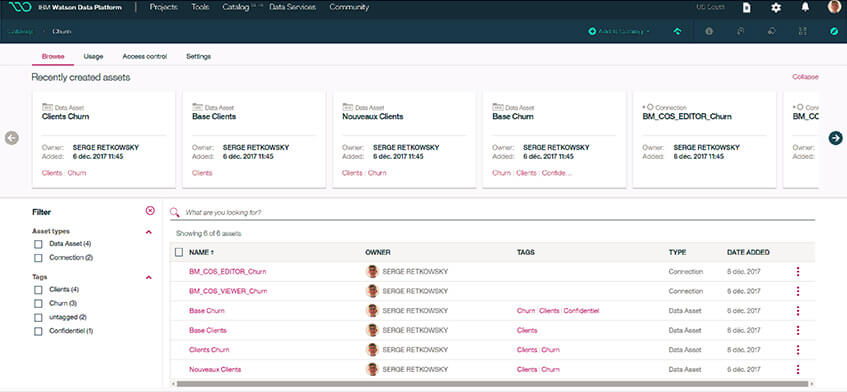
Catalogue – Source IBM Watson Studio
Outillage de dashboarding et de visualisation des données
La plateforme IBM Watson Studio met à votre disposition des outils pour créer des visualisations et des dashboards.
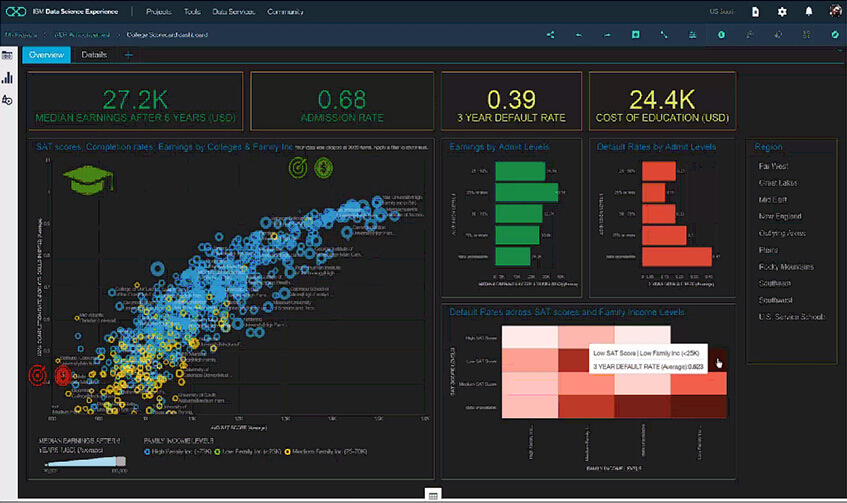
Dashboard – Source IBM Watson Studio
Outillage d'intelligence artificielle
La plateforme IBM Watson Studio donne accès aux API Watson, les API d'intelligence artificielle développés par IBM : API de reconnaissance d'image, API de traduction des langues (speech to text ou text to speech), API reconnaissant le sentiment et l'intention dans le langage, etc.
Il est possible d'utiliser ces API comme elles existent déjà, en mode pré-entraîné, ou bien de les ré-entraîner pour son propre cas d'usage en fonction de son métier.
Tous ces outillages disposent d'un outil commun : la couche de projet. Elle permet de créer des espaces de collaboration au sein desquels l'ensemble des professionnels peut travailler ensemble sur un même projet et y retrouver tous les data assets créés ou utilisés, tous les dashboards, etc.
Quid du stockage dans la plateforme IBM Watson Studio ?
IBM Watson Studio inclut un stockage de base de type Object Storage. La plateforme offre en outre la possibilité de connecter tous types de stockage, que ce soit du stockage au sein de la plateforme IBM (base de donnée relationnelle, base de données SQL, base de données Hadoop), ou bien des data stores déjà présents en externe sur le cloud Azure, sur le cloud AWS, etc. En créant des connecteurs, on peut soit récupérer la donnée là où elle se trouve soit la laisser où elle est et ne récupérer que les métadonnées si on veut indexer les data assets dans son catalogue.
Retour aux éditeurs "Plateforme de données"
Vous souhaitez bénéficier d'experts sur IBM Watson Studio et d'experts Big Data? Rendez vous sur la page Contact
Des spécialistes et intégrateurs de IBM Watson Studio à Nantes, Angers, Niort, Rouen, Paris, Brest, Lyon, Bordeaux, Toulouse, Grenoble, Saint-Etienne, La Rochelle, Agen, Bayonne, Montpellier, Marseille, Nîmes, Aix-en-provence...
Des experts en analyse et traitement Big Data sur IBM Watson Studio en Région parisienne, Région Normandie, Bretagne, Ile de France, Pays de la Loire, Centre Val de Loire, Auvergne Rhône Alpes, Midi-Pyrénées, Nouvelle-Aquitaine, Occitanie, Rhône, Ain, Isère, Loire, et Provence-Alpes-Côte d'Azur.