


Type de produit et caractéristiques d'Azure Databricks
Azure Databricks allie les performances du Cloud public de Microsoft Azure et d’une plateforme de traitement de données Big Data, Databricks, créée par les fondateurs de Spark.
Microsoft Azure propose un grand nombre de produits en PaaS (stockage Cloud, machines virtuelles, solutions Big Data, Machine Learning, …) que nous utilisons à la demande, simplifiant ainsi l’utilisation et la gestion de ces technologies pour toute entreprise. Il permet notamment de mettre en place des architectures en haute disponibilité et en garantissant évolutivité et flexibilité. Azure Databricks est l'une de ses APIs.
Aujourd’hui, à l’ère du Big Data, Apache Spark révolutionne le Système d’Information des entreprises. De par la montée en charge des données et l’exécution au dernier moment des traitements, ce framework open-source est fortement reconnu pour sa rapidité (jusqu’à 100 fois plus qu’Hadoop Map Reduce) mais cela demande en mode on-premise de gérer les serveurs, le cluster, leur scalabilité, hors ce n’est pas le cas avec du Cloud Services comme Amazon Web Services, Google Cloud Platform ou Windows Azure.
Databricks, plateforme d’analyse de données massives, s’intègre pleinement à la solution Azure. Cette dernière lui donne sa puissance de calcul via l’hébergement de son cluster et vous permet d’accéder facilement à toutes les solutions Microsoft Cloud comme l’entrepôt de données Azure Data Lake. Elle permet le pilotage de projets collaboratifs d’Intelligence Artificielle, mettant à disposition le framework de calcul distribué Apache Spark.
Le but de cette solution Big Data est de faciliter toute création de projet de Machine Learning, de Data Mining ou d’analyse d’énormes volumes de données, tant par l’optimisation du cluster que par la conception du modèle par une équipe et sa mise en production.
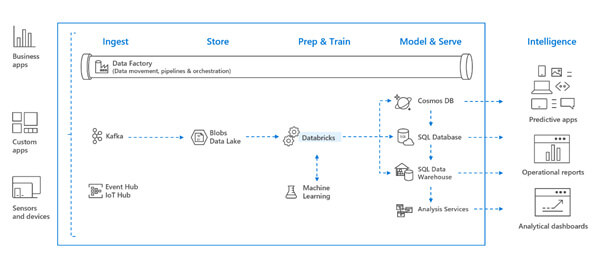 (Azure Databricks et son intégration dans Microsoft Azure - Source Azure)
(Azure Databricks et son intégration dans Microsoft Azure - Source Azure)
Azure Databricks permet de réaliser le traitement des données à l’aide de plusieurs langages dépendant des affinités et besoins de chacun et de l’équipe :
- Scala
- Python
- R
- SQL
Présentation et concept d'Azure Databricks
Azure Databricks, l'analyse de données Big data à portée de main
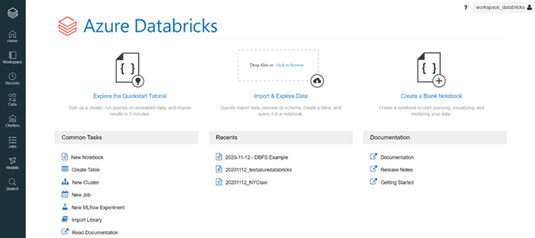 (Tableau de bord Azure Databricks)
(Tableau de bord Azure Databricks)
En utilisant Databricks, l’utilisateur crée très simplement un cluster ou un notebook pour traiter les données hétérogènes ou non à partir de son tableau de bord. Il peut aussi importer une table ou une bibliothèque, monitorer un modèle de Machine Learning sans écrire une ligne de code, directement à l’aide de l’interface.
Par exemple, un développeur peut importer des bibliothèques qui seront toujours disponibles avec Create Library, même après avoir éteint le cluster. Il les ajoute alors sous forme de jar, package Maven ou CRAN, ou fait appel à une bibliothèque Python.
 (Créer une bibliothèque)
(Créer une bibliothèque)
De même, les données sont disponibles aisément via l’onglet Data, afin de joindre de nouvelles sources d’informations. Elles peuvent provenir de multiples environnements, aussi bien un fichier csv ou xml, une table SQL que vous avez sauvegardée, votre Data Lake sur Azure, une base de données SGDBR comme MySQL ou PostgreSQL, une base NoSQL comme MongoDB, ElasticSearch, Redis, un flux de données en temps réel issu de Kafka, ou toute autre application via une connexion JDBC.
Databricks a créé également son format de fichier, Databricks File System (DBFS) qui est distribué et monté directement sur la plateforme. Vous optimiserez ainsi son exploitation, sans perdre les éléments lorsque vous éteignez le cluster ou sans avoir besoin de rappeler les justificatifs d’identité.
Vous pourrez aussi importer vos données provenant de partenaires d’Azure Databricks comme Qlik Sense Replicate.
 (Créer une table)
(Créer une table)
Par ailleurs, le notebook est l'outil fondamental de la réalisation de l’analyse de tout Machine Learning Engineer. Il est similaire à un markdown en R, il allie à la fois des cellules de code et de texte, permettant de le commenter facilement, d’afficher des images, des pages HTML, des équations mathématiques …
A l’aide des commandes Magics,vous pourrez appeler des fonctions en lignes de commande dans un terminal, changer de langage, exécuter des requêtes SQL et des cellules Python ou encore créer des cellules de texte.
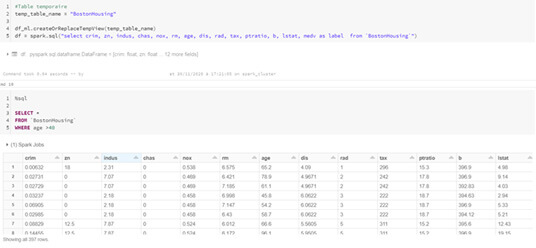 (Commandes Magics)
(Commandes Magics)
Visualiser les données est essentiel pour toute analyse mais cela n’est pas natif à Apache Spark. Databricks propose la fonction display() qui renvoie les informations sous forme de table que l’on peut manipuler et de graphiques interactifs (en utilisant une bibliothèque reconnue dans ce domaine, Plotly). Les développeurs voient alors cette table sous forme de nuages de points, de graphique en barres, de cartes et peuvent personnaliser les champs à afficher graphiquement.
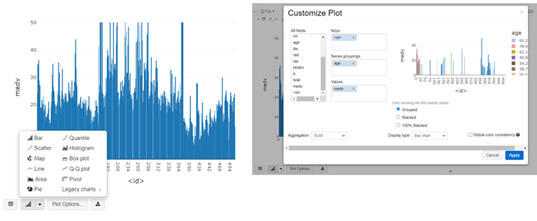 (Customisation de graphiques sous Databricks)
(Customisation de graphiques sous Databricks)
Azure Databricks, une solution unifiée avec Apache Spark natif
Azure Databricks, c’est aussi un service managé et unifié qui rend Apache Spark accessible à tous.
En effet, l’utilisateur peut créer une pipeline Big Data entièrement avec le portail Azure et Azure Databricks, comme une architecture lambda :
- Ingérer des données collectées depuis une solution de Data Integration comme Kafka
- Les stocker via un service de stockage comme le stockage Blob Azure, Azure SQL Data Warehouse ou Azure Data Lake Storage
- Les transformer et les préparer à l’aide d’Azure Databricks notamment pour concevoir un modèle de Machine Learning
- Déployer le modèle en production, conserver ses résultats dans Azure SQL Database ou Azure Cosmos DB et les visualiser via Azure Analysis Services et Power BI
Il peut également créer et manager son cluster Spark simplement via son gestionnaire de ressources. La plateforme permet également un redimensionnement du cluster automatique et optimisé s’adaptant au mieux aux ressources dont votre calcul a besoin, vous permettant des réduire les coûts.
Vous pourrez ainsi traiter des flux d’informations, analyser par exemple vos données non structurées, déployer des applications, automatiser la maintenance de vos modèles d’apprentissage, et matérialiser vos réseaux de données par des graphes, le tout de manière massive.
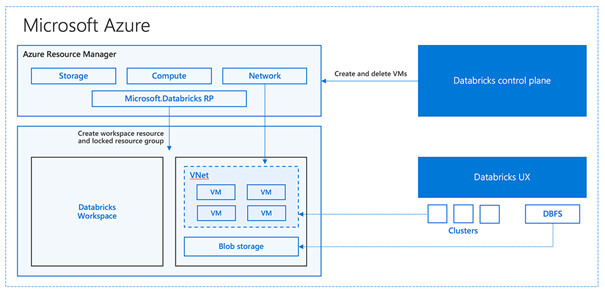 (Architecture Big Data d'Azure Databricks - Source Azure)
(Architecture Big Data d'Azure Databricks - Source Azure)
L’habitué d’Apache Spark pourra conserver ses réflexes, notamment grâce à l’interface web qui est toujours accessible. Il pourra donc monitorer un job Spark et voir son log et sa configuration.
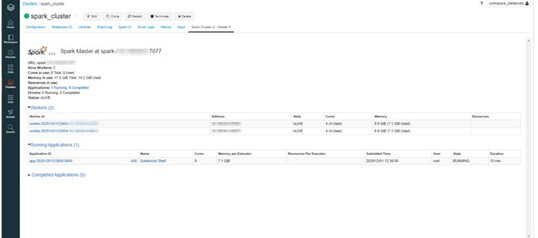 (Spark UI)
(Spark UI)
Azure Databricks, une analyse des données en équipe
Azure Databricks, c’est aussi construire des pipelines de manière collaborative : des notebooks comme des sources de données peuvent être partagés, chacun à son workspace, mais travailler ensemble et de manière sécurisée est facilité par cette plateforme Big Data.
Par exemple, pour mettre un modèle en pré-production via l’onglet modèle, un Data Scientist peut facilement demander l’accord de son équipe comme vous pouvez le voir sur l’image ci-dessous :
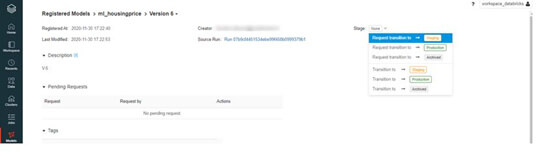 (Validation par l’équipe avant mise en pré-production du modèle de Machine Learning)
(Validation par l’équipe avant mise en pré-production du modèle de Machine Learning)
Par son versioning automatique, accéder à des backups, des sauvegardes de son code est simple et peut être relié à un Git Repository.
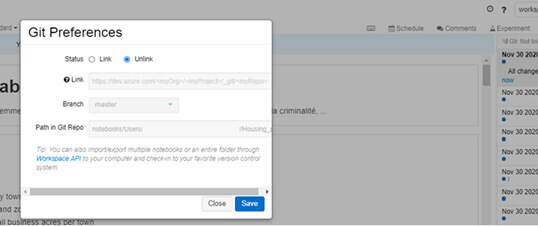 (Versionning sous Azure Databricks)
(Versionning sous Azure Databricks)
Azure Databricks propose aussi une interface spécifique pour l’administrateur afin de notamment gérer les droits d’accès au projet et de gérer sa sécurité.
 (Admin Console)
(Admin Console)
Travailler en équipe, signifie aussi rendre accessible l’information. Databricks propose également de réaliser des dasboards permettant de visualiser les données et de renvoyer les éléments stratégiques de l’analyse. L’analyste des données réalise alors un reporting partagé aux personnes définies.
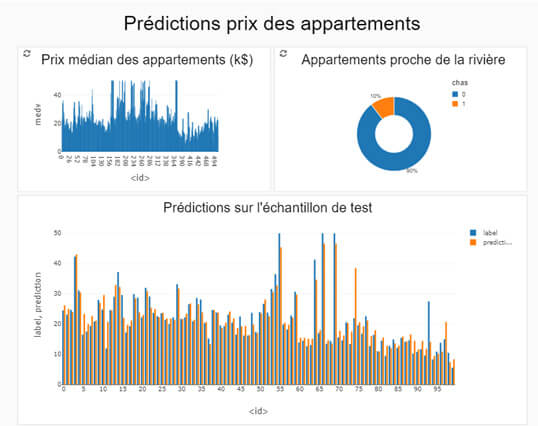 (Dashboard avec Azure Databricks)
(Dashboard avec Azure Databricks)
Azure Databricks, un outil à chaque étape de vie du modèle de Machine Learning
Azure Databricks se veut également un outil essentiel pour réaliser des prédictions sur un gros volume de données et pour tout projet de Data Science. Vous pourrez tout réaliser en lignes de code mais aussi à l’aide de l’interface de la plateforme. La solution propose du monitoring et du versioning de son modèle via MLflow Experiment.
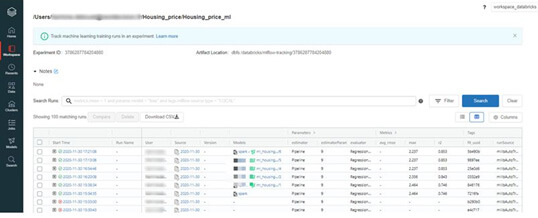 (Tableau de bord de MLflow Experiment)
(Tableau de bord de MLflow Experiment)
Tous les paramètres du modèle entrainé sont enregistrés, ainsi que les métriques d’évaluation, les tags et les graphiques ajoutés par le concepteur du modèle. Il peut alors enregistrer le modèle de son choix pour ensuite le mettre en production et orchestrer ses jobs.
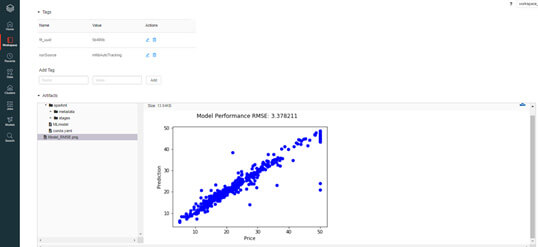 (Un run sur MLflow Experiment)
(Un run sur MLflow Experiment)
Pour déployer un modèle, le développeur fait appel à la REST API accessible à l’aide de l’onglet Serving du modèle choisi. Il peut alors réaliser des prédictions à l’aide du browser ou en Python.
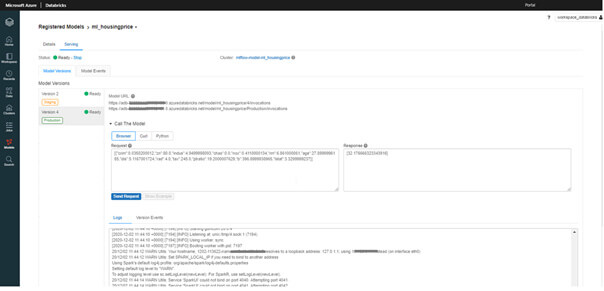 (API REST)
(API REST)
Fonctionnalités principales d'Azure Databricks
Azure Databricks permet :
- La mise en place d'un outil de traitement de l'analyse de données massives unifié et pleinement intégré à un environnement Azure
- La création de code collaboratif sûr pour un meilleur travail en équipe
- La réalisation de graphiques des informations personnalisées
- La fabrication aisée de tableaux de bord
- La conception de modèles de Machine Learning facilitée
- L'orchestration simplifiée de pipelines Big Data
- Une pluralité de langages possibles : Python, R, Scala, SQL...
Avantages d'Azure Databricks
- Facilite la réalisation d'un projet sécurisé en équipe
- Outil totalement incorporé au Cloud Microsoft
- Permet de travailler avec le même outil, de la création du Machine Learning à sa mise en production
- Facilite l'analyse des données Big Data avec Apache Spark
- Destiné aux Data Scientists / Machine Learning Engineers, mais aussi aux Data Engineers et Data Analysts
Retour aux éditeurs "Plateforme de données"
Vous souhaitez bénéficier d'experts Azure Databricks et d’experts Big Data? Rendez vous sur la page Contact
Des spécialistes et intégrateurs de Databricks à Nantes, Angers, Rouen, Paris, Niort, Brest, Lyon, Grenoble, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Agen, Marseille, Bayonne, Montpellier, Nîmes, Aix-en-provence...
Des experts en analyse et traitement Big Data sur Databricks en Région parisienne, Pays de la Loire, Normandie, Bretagne, Ile de France, Nouvelle-Aquitaine, Provence-Alpes-Côte d'Azur, Nouvelle-Aquitaine...