


Type de produit et caractéristiques de Snowflake
Snowflake est une plateforme d’entrepôt de données de type Big Data hébergée entièrement dans les data centers Cloud (AWS / Amazon Cloud, Azure ou Google) selon un modèle SaaS (Software as a Service) ou si on considère le fournisseur de cloud public comme une PAAS (Platform as a Service).
Snowflake s’apparente à une base de données relationnelle (SGBD) mais qui a été pensée et créée spécialement pour une plateforme Cloud ou pour un hébergement data center en prenant les meilleures parties des architectures SQL (ANSI SQL) & NoSQL (MPP, Massively Parallel Processing). Snowflake peut stocker et traiter des gros volumes de données.
Snowflake, solution puissante, souple, et scalable, permet de collecter, d'ingérer, d'analyser et de publier des rapports vers les collaborateurs, et ce de manière rapide et en toute sécurité.
Snowflake est un outil PAAS, Platform As A Service en cloud, qui se manage par usage d'une interface ergonomique et intuitive. Snowflake est capable d'encaisser un nombre quasi illimité de tâches en parallèle.
Toutes ces qualités font de Snowflake est une solution idéale pour construire un Data Lake, pour gérer le DATA OPS et donc toute l'expertise autour des données, la data science, ainsi que le développement de Business Apps. Super base de données dans le Cloud, Snowflake allie à la fois la simplicité d'un SQL SERVER à la puissance de feu que l'on pourrait retrouver dans une base Big data comme Elastic ou Hadoop.
Snowflake est conçu pour être indépendant des plateformes cloud et fournir des données de réplication, de synchronisation et de basculement des solutions, et ceci indépendamment de la plateforme utilisée. Cela permet aux organisations d'avoir accès aux mêmes données à travers les clouds et les régions.
Présentation et concept de Snowflake
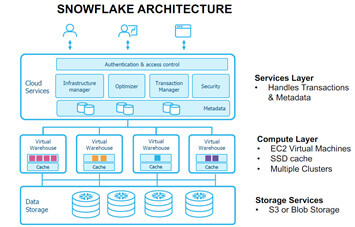
Contrairement aux entrepôts de données traditionnels, Snowflake propose une architecture big data à plusieurs groupes et à disque partagé, et séparé en trois composants : le stockage de données dans la database, le calcul et les services. En séparant ces composants, Snowflake permet de simplifier la maintenance et d'améliorer les performances.
La couche des services est constituée d’un ensemble de services qui coordonnent les activités dans Snowflake
Elle gère notamment les sessions client, les métadonnées, les transactions, la planification des requêtes, la sécurité/la gouvernance. Il est donc possible de suivre l’exécution d’une requête et d’analyser son profil, d’avoir accès à l’historique des transactions passés et les consolider pour en constituer des rapports d’utilisation et de coûts, de gérer les accès fins par rôles et utilisateurs.
La couche calcul de Snowflake s’occupe du traitement des requêtes / Query
Une extraction des données de l’entreprise stockées dans Snowflake s’effectue par l’exécution de query/requêtes. L’exécution de la requête s’effectue dans la couche de traitement. Snowflake traite les requêtes à l’aide « d’entrepôts virtuels ». Chaque entrepôt virtuel permet le calcul de traitement massivement parallèle (MPP). On parle de grappe car elle est composée de plusieurs nœuds de calcul alloués par Snowflake à partir d’un fournisseur Cloud. Par conséquent, chaque entrepôt virtuel n’a aucune conséquence sur les performances des autres entrepôts virtuels. Chaque entrepôt virtuel peut être configuré à la volée pour augmenter ces capacités de calcul unitaire et/ou concurrent sous forme de taille (XS à 4XL). Chaque entrepôt virtuel peut être mis en pause ou arrêté sans compromettre le stockage ni l’accès aux données par d’autres entrepôts. Le coût d’un entrepôt virtuel est calculé par crédit en fonction de la taille qui lui est allouée. Quand un entrepôt démarre ou redémarre, la première minute est entièrement comptabilisée et ensuite le calcul du crédit est à la seconde jusqu’à l’arrêt de celui-ci. Une propriété permet de suspendre un entrepôt virtuel au bout d’un certain temps d’inutilisation (plus de requêtes actives) mais celui-ci redémarrera automatiquement à la première requête.
La couche stockage Snowflake s’occupe du stockage des bases de données
Snowflake utilise un mode de stockage des données optimisé compressé et en colonnes. Snowflake stocke ces données optimisées dans le stockage Cloud. Le gestionnaire de Snowflake administre tous les paramètres traditionnels d'une base de données. Aussi la structuration, le volume des données, la structure d'entreposage, les métadonnées des tables et les statistiques de la base sont automatiquement gérés. Tous ces éléments sont des objets non visibles de l'utilisateur ni par l'interface ni en SQL. Cette gestion automatique nécessite un savoir-faire mais détermine la puissance infinie de l'outil que ce soit pour de la donnée structurée ou semi-structurée.
Snowflake permet le chargement en batch de fichiers via Snowsql ou la diffusion en continu via Snowpipe connecté sur le Cloud.
Snowflake offre à la DSI une protection continue des données et des structures. Le Time Travel vous permet de revenir immédiatement à un état antérieur de toute table (UNDROP), base de données ou schéma. Il est activé automatiquement et stocke les données au fur et à mesure de leur transformation pendant 24 heures, ou 90 jours dans les versions d'entreprise.
La plupart des entrepôts de données vous obligent à copier des données pour les cloner, ce qui nécessite un effort manuel important et un investissement en temps considérable. L'architecture de données partagées de Snowflake vous permet de ne jamais avoir besoin de copier des données, car tout entrepôt ou base de données fait automatiquement référence au même magasin de données centralisé.
Le coût de Snowflake est calculé en cumulant les coûts des accès aux services, du stockage et du calcul (compute) via les "entrepôts virtuels".
Fonctionnalités principales de Snowflake
- Nombre et taille "illimités" de base de données et de schémas
- Table, vue, vue matérialisée, séquence
- Fonction et procédure (JavaScript)
- Vue sécurisée et fonction sécurisée
- Stream et tâche ordonnancée
- Clonage au niveau base, schéma et table
- Gestion fine des rôles et utilisateurs
- Gestion optimisée des caches de requêtes
- Time Travel pour accéder à l'historique des données à une période définie pour des tâches de restauration d’objets supprimés, clonage à un point du passé ou à fin d'analyse des données passées
- La licence Snowflake permet de ne payer que lorsqu'on utilise le cloud computing.
- Secure Data Sharing pour partager ces données avec d'autres comptes Snowflake
- Data Market Place pour acheter ou vendre des données externes
Avantages de Snowflake
- Snowflake est extrêmement performant pour répondre à des requêtes complexes sur des volumes très larges.
- Les outils décisionnels et solutions de business intelligence peuvent se brancher sur Snowflake pour effectuer des analyses de type prédictive
- Snowflake est un outil simple à appréhender pour les gens connaissant bien le SQL et ce autant pour créer des requêtes sur les données structurées que sur les données brutes semi-structurées (Json, XML, Avro, Parquet), quel que soit la qualité des données.
- Le support des équipes Snowflake pour les entreprises est très efficace
- Possibilité de connecter Snowflake à un outil de Data Integration de type Talend, Stambia, Oracle Data Integrator ou autre pour collecter les données
- Ne nécessite pas d’installation hardware et la création des bases de données est extrêmement simple
- Avec le zero cost cloning, la duplication d’environnement est extrêmement rapide et sans surcoût.
- Snowflake dispose d’une grande communauté d’échange et d’une documentation complète.
Dans quel cas utiliser Snowflake ?
- Sélectionner Snowflake lorsque vous êtes dans un environnement multicloud et que vous avez des charges de travail qui peuvent bénéficier de l'élasticité dynamique et de la mise à l'échelle automatique et instantanée des grappes.
- Éviter le Snowflake lorsqu'une solution d'entrepôt de données hybride est nécessaire - sur site et dans le nuage.
- Utiliser le Snowpipe de Snowflake (chargement de données par microbatch sans serveur) comme méthode optimale pour charger en continu des données structurées et semi-structurées et gérer la saisie des données de changement (CDC).
- Optimiser l'environnement Snowflake lors de la surveillance des entrepôts virtuels en analysant les requêtes, l'envoi de notifications ou la suspension d'entrepôts virtuels lorsque les limites critiques sont dépassées, afin de réduire les coûts et d'accroître les performances.
- Intégration avec des fournisseurs tiers pour un traitement ETL, une BI, une science des données et une IA/ML transparents.
- Il est important aussi de comprendre que Snowflake ne disposant pas de toutes les fonctionnalités existantes sur les bases traditionnelles, il faut donc apprendre à adapter la solution à certaines contraintes Snowflake et ce pour privilégier sa grande capacité à répondre à des requêtes qui ne sont plus supportées par les bases traditionnelles ou trop longues à répondre.
Retour aux éditeurs "Plateforme de données"
Vous souhaitez bénéficier de consultants experts, de développeurs sur Snowflake, un coup de main pour monter des solutions autour de Snowflake ? Rendez vous sur la page Contact
Expertise et conseil en Snowflake à Nantes, La Roche Sur Yon, Angers, Paris, Niort, Brest, Le Mans, Lyon, Grenoble, Saint-Etienne, Bordeaux, Angoulême, Toulouse, La Rochelle, Bayonne, Nîmes, Montpellier, Agen, Marseille, Aix-en-Provence...
Des experts en Snowflake en Bretagne, Région Pays de la Loire, région Parisienne, Île de France, Poitou-Charentes, Nouvelle-Aquitaine, Midi-Pyrénées, Provence-Alpes-Côte d'Azur et Languedoc-Roussillon...