

A l’heure où la mise en œuvre et l’utilisation de bases NoSQL s’intensifient, il peut être utile de se demander dans quelle proportion il sera possible d’intégrer de telles bases de données avec un système d’information préexistant.
La question de l’interconnectivité de ces bases avec les outils du SI est parfois primordiale pour la réussite de ces projets. Malheureusement, le standard, en termes d’interrogation de base de données, reste encore aujourd’hui le langage SQL. Et ce dernier n’est évidemment pas supporté par la plupart des bases de données NoSQL. Elasticsearch s’interroge avec le langage DSL, Apache Cassandra avec CQL, etc.
Nous allons donc voir comment il serait possible d’interroger quand même ces bases avec le langage SQL. Pour cela, nous allons utiliser Trino.
Histoire de Trino
Au début il y avait PrestoDB. Ce moteur SQL distribué (MPP) a été créé par Martin Traverso, David Philipps et Dain Sundstorm, quand ils travaillaient pour Facebook. L’enjeu était de permettre l’interrogation en SQL de bases de données Hive (sur des bases très volumineuses : 300 Péta-octets). PrestoDB est devenu par la suite Presto.
Les 3 fondateurs historiques de PrestoDB sont ensuite partis de Facebook (en 2018) pour continuer le développement de leur application, qu’ils avaient renommé PrestoSQL. Finalement, en décembre 2020, PrestoSQL est devenu Trino.
Quand Presto (Facebook) a été imaginé pour les besoins des géants d’Internet, Trino a été conçu pour répondre à davantage de besoins et de cas d’usages.
Mise en place de la stack technique pour connecter Trino à Cassandra
Le but de cet exemple est de montrer comment connecter Trino à Apache Cassandra, afin d’être capable d’interroger Cassandra en SQL.
Pour les besoins de la démonstration, tout a été imaginé en Docker, à l’aide de la stack suivante :
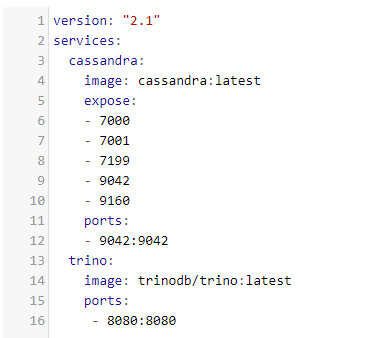
Cette stack, très simple, n’est évidemment pas à mettre en production :
- Les aspects de sécurisation des briques Cassandra et Trino ne sont pas abordés.
- Également, les clusters sont mono-nœud, là il conviendrait bien évidemment de distribuer les deux briques pour augmenter les performances.
Côté Cassandra, un Keyspace tpcassandra a d’abord été créé :
CREATE KEYSPACE tpcassandra WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
Ensuite, une table Persons a été créée dans ce Keyspace :
CREATE TABLE tpcassandra.Persons (
familyName varchar,
firstName varchar,
age int,
address varchar,
phone varchar,
PRIMARY KEY(familyName));
Enfin, une ligne a été insérée dans cette table :
INSERT INTO Persons (familyName, firstName, age, address,phone)
VALUES ('BARON', 'Mickael', 36, 'Poitiers', '+33549498073');
Configuration de Trino
Dans le conteneur Trino, il faut d’abord ajouter la connexion vers Cassandra. Pour cela, il faut se rendre dans le répertoire /etc/trino/catalog et y créer un fichier cassandra.properties avec les lignes suivantes :
connector.name=cassandra
connector.contact-points=[cassandra]
Une fois le fichier créé, il faut redémarrer le conteneur Trino pour que les modifications soient correctement prises en compte.
Il est maintenant possible de tester l’exécution de requêtes SQL via Trino, avec la commande suivante :
trino --execute 'select * from cassandra.tpcassandra.Persons;'

Avec Trino, il est également possible d’utiliser la console d’administration pour voir les requêtes passer sur Trino. Pour cela, il faut se rendre sur l’URL : http://localhost:8080/ui
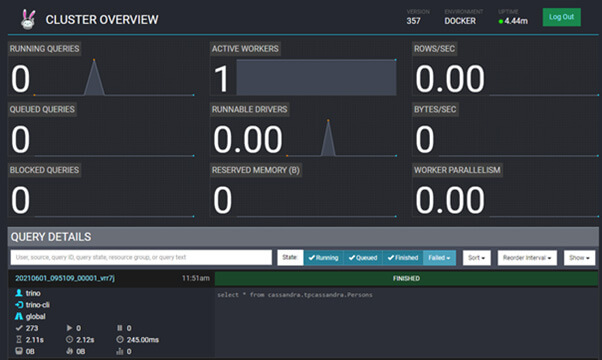
Cette interface permet d’avoir beaucoup de statistiques sur l’envoi d’une requête SQL :
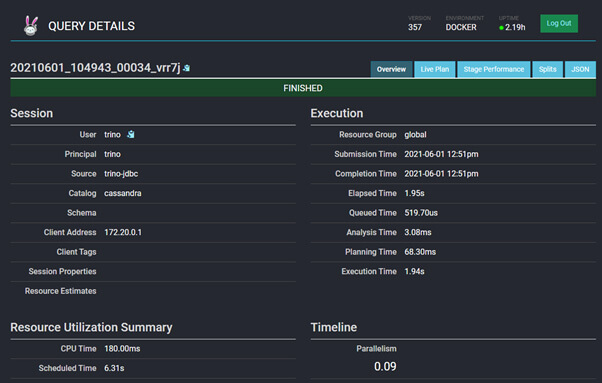
Interroger Apache Cassandra en SQL
Maintenant que Trino est prêt, il ne reste plus qu’à configurer un outil SQL, comme SQuirreL SQL, afin d’interroger Cassandra en SQL. En effet, Trino propose un connecteur JDBC.
Voici comment configurer le pilote JDBC :
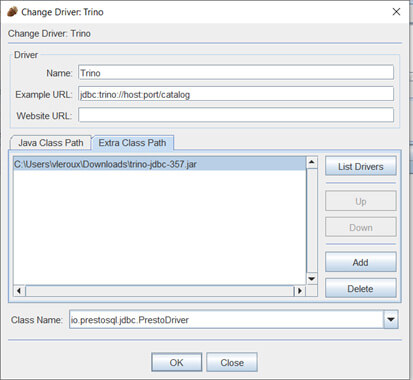
Il ne reste plus qu’à se connecter à l’aide du compte Trino (sans mot de passe) :
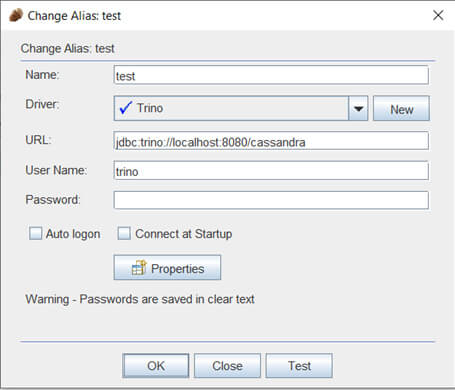
Puis à lancer une requête SQL :
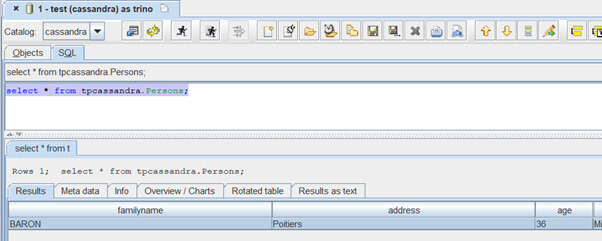
Il serait donc maintenant même possible d’interconnecter un autre outil à Cassandra en passant par Trino, comme SAP BI, Power BI, Tibco Spotfire, etc.
Trino pour d'autres usages
Dans cet exemple, nous avons vu rapidement qu’il était possible de connecter Trino à Cassandra mais ce n’est pas la seule possibilité. En effet, Trino propose d’autres connecteurs pour des bases SQL et NoSQL : https://trino.io/docs/current/connector.html
Quelques exemples intéressants de connecteurs à suivre :
- Elasticsearch
- Google Sheets
- Kafka
- Kinesis (AWS)
- MongoDB
- Prometheus
- Redis
- etc.
Ainsi s'achève notre tuto pour connecter Trino à Apache Cassandra, retrouvez tous nos trucs et astuces ainsi que les nouveautés des éditeurs dans notre Wiki !
Nos consultants experts de Next Decision sont à votre écoute pour vous accompagner dans vos projets ! Contactez-nous !