

Dans cet article, nous allons étudier un cas d’usage d’une API abstraite avec SnapLogic. La solution qui en résultera sera applicable, en théorie à toute base de données supportée par l’outil. Elle permettra en très peu de temps de configurer toute une API (Application Programming Interface ou Interface de Programmation) et ce, en ne touchant à quasiment à aucun code !
Scénario de référence : Utiliser SnapLogic pour construire son API
Nous possédons une base de données SQL Server stockée en Cloud sur Azure. Nous voudrions requêter cette base et exposer le résultat avec une API. Notre base de données d’exemple est la base de données “AdventureWorks”, trouvable sur internet. Nous voudrions récupérer les clients, les produits, et les commandes clients. Nous allons avoir besoin des tables “Customer”, “Product” et “SalesOrderHeader”.
À terme, notre solution devra pouvoir requêter le maximum de tables possible sans ajouter de Snaps(briques unitaires fonctionnelles de SnapLogic) ou de Pipeline(Scénario d'exécution) supplémentaire (centralisation du traitement). En outre, il devra être possible d’exporter la solution vers d’autres schémas de base de données (généricité de la solution). Il faudra aussi pouvoir ajouter des modifications facilement que ce soit dans le comportement de l’API, ou dans la structure des pipelines (maintenabilité, développabilité).
Nous allons développer cette solution sur SnapLogic et essayer d’utiliser ces fonctionnalités afin de rentrer dans une stratégie “DRY” (Don’t Repeat Yourself), en ajoutant un principe d’abstraction, qui rendra notre solution la plus générique possible, tout en limitant le temps de développement.
Lors d’une exécution, SnapLogic gère lui-même les modèles de données et les abstraits, permettant une grande souplesse aussi bien dans les développements que dans l’exécution. Le logiciel reposant exclusivement sur un principe de “boites” imbriqués, la quantité de code à fournir est minime, ce qui en fait une solution simple, compréhensible et reproductible par tout utilisateur (métiers ou techniques).
Pour tirer parti au maximum de cet article, un bon niveau d’abstraction sera un plus, ainsi qu’une compréhension des algorithmes récursifs et une connaissance basique du JSON.
Nous allons avoir recours à des snaps et des fonctionnalités de SnapLogic dont vous pourrez retrouver la documentation sur le site officiel de l'éditeur.
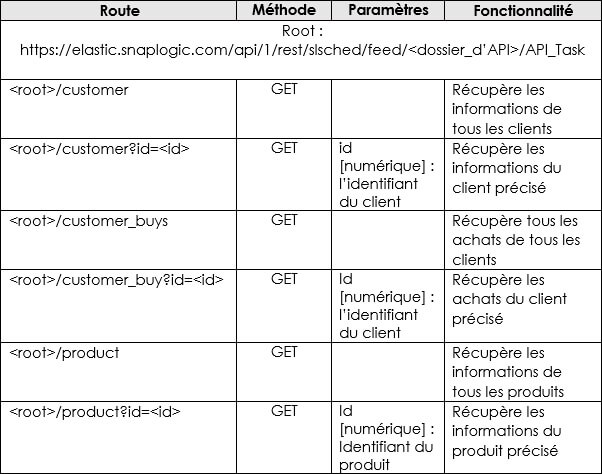
Route d'accès à l'API
Comme pour toute API, cherchons tout d’abord à définir les routes d’accès de notre API et leur comportement. Voici le tableau les regroupant :
Conception théorique de l'API
Nous allons concevoir une variable au format JSON qui détiendra des couples de clefs-valeurs qui détermineront le comportement de notre solution (quelle table requêter, sur quelle clef trier les données, etc.). Ce JSON est à la charge du développeur. Il va donc orienter l’exécution du pipeline en fonction de la demande de l’utilisateur.
Par exemple, l’utilisateur veut récupérer les clients, il appelle l’API avec l’url “<root>/Customer_buy”, la requête est récupérée par notre API, qui détermine que ce sont les tables “Customer”, “Product” et “SalesOrderHeader” qui doivent être utilisées pour faire la requête à la base de données (les noms des points d’entrées peuvent être différents des noms physiques des tables requêtées). La requête est construite, envoyée, les résultats sont récupérés et formatés au format JSON pour être renvoyés à l’utilisateur.
Création de l'API Partie 1 - Requêtes simples avec/sans filtre
Création d'un compte de connexion
Nous allons devoir utiliser une base de données SQL Server stockée sur un server Cloud Azure. Or, SnapLogic ne connait pas encore notre base de données, son serveur et les identifiants pour y accéder. Il nous faut donc créer un compte de connexion vers notre serveur et base de données SQL Server en amont avec SnapLogic.
Le système de comptes de connexion dans SnapLogic permet de simplifier les accès à différentes bases de données. Ici nous allons utiliser une connexion de type SQL Server, mais il en existe plein d’autre plus ou moins spécifique à certaines catégories de snaps (MySQL, MongoDB, HDFS, DataLake, etc.). Selon leur type, ces comptes de connexion sont réutilisables dans les snaps et pipelines d'un même projet.
Pour créer un compte de connexion depuis le designer, glissez déposez un snap “SQL Server” (n’importe lequel mais prenons un “SQL Server - Select”). Dans l’onglet “Account” du snap, créez un nouveau compte de connexion de type SQL Server (il n’y a qu’un type de connexion pour ce snap, mais il peut y en avoir plusieurs pour d’autres type de snaps comme les “File reader” par exemple). Remplissez ensuite les champs avec vos informations (nom de l’hôte, nom de la base de données, identifiant, mot de passe, etc.).
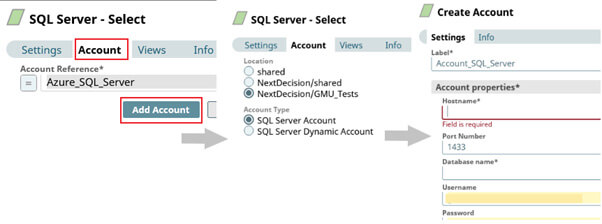
Avec un compte de connexion SQL Server créé, on peut maintenant accéder aux tables et données de notre base.
Mise en place d'une structure exécutable avec SnapLogic
Nous allons développer la solution en deux temps. D’abord, nous créerons un mécanisme de requête sur une seule table. Ce mécanisme abstraira le nom de la table, ainsi que l’utilisation ou non d’un filtre. Dans un deuxième temps, nous allons générer des requêtes utilisant des jointures. Ce mécanisme aussi devra être autonome, et donc, sera dans un pipeline dédié.
Définissons un premier pipeline comme point d’entrée de l’API. Pour cela, il faut créer le pipeline.
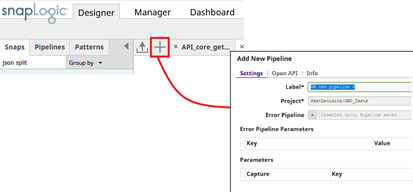
Puis, pour l’exposer vers l’extérieur, il faut créer une tâche (“Task”) qui référencera ce pipeline. C'est ensuite cette tâche qui sera appelée par l’utilisateur, et qui exécutera donc notre pipeline.
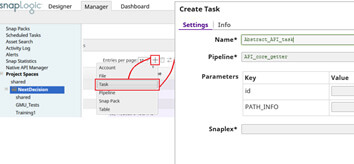
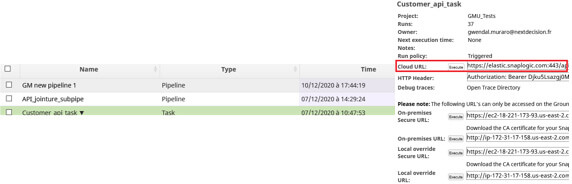
Pour accéder à votre API de l’extérieur, dans SnapLogic (onglet manager), cliquez sur la flèche à côté du nom de la tâche, puis sur détails. L’URL d’accès à votre API est alors affichée (Cloud URL), avec toutes les informations nécessaires pour utiliser cette API depuis un logiciel tierce (Postman, SoapUI, Firefox, par exemple).
Notre environnement d’exécution étant mis en place, nous pouvons maintenant développer nos pipelines.
Paramétrages du pipeline principal pour l'utilisateur
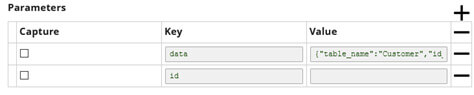
Pour pouvoir “abstraire” notre pipeline, il nous faut des variables et des paramètres. Nous voulons récupérer le nom de la table que nous voulons “attaquer”, et s’il faut la filtrer par son “id” ou non.
L’appel à l’API se fait via un seul point d’entrée qui se trouve dans “<root>” (le nom de notre tâche : API_Task). La table attaquée se trouve donc juste ensuite. Comment la récupérer ? Pour cela, il existe un paramètre préconçu dans SnapLogic : PATH_INFO.
Le paramètre PATH_INFO de SnapLogic
PATH_INFO est un paramètre qui récupère tout le contenu de la requête entre la racine de l’appel à l’API (ce que nous avons appelé <root>, et auxquels on ne donne pas de valeur) et le “?” (qui détermine le début des paramètres auxquels sont affecté des valeurs). Dans nos exemples d’URL (cf tableau des routes d'accès un peu plus haut dans l'article). Dans notre cas d’utilisation, PATH_INFO récupèrerait “customer”, “customer_buys” ou “product”.
Pour utiliser ce paramètre préconçu, il faut tout de même le préciser dans les paramètres de notre pipeline (cf. Image ci-dessous), puis le récupérer dans le pipeline (nous verrons comment faire dans le point suivant).
ID : La valeur du filtre
Ce paramètre permettra de filtrer les données sur leur clef de filtre (par exemple, pour la table “Customer”, nous définiront leur identifiant “CustomerID” comme clef de filtre).
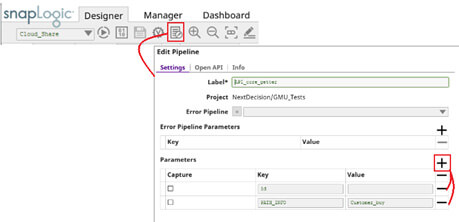
Récupération des paramètres du pipeline par un Snap "Mapper"
Maintenant que notre pipeline est paramétré, il nous faut récupérer ces paramètres pour pouvoir les utiliser dans les snaps. Pour cela il y a deux choses à retenir.
La première est d’utiliser un "Mapper"en début de processus, ce qui permet de définir les variables que nous allons utiliser et leurs valeurs.
La deuxième est d’utiliser le préfixe “_” devant un nom de paramètre de pipeline pour récupérer sa valeur (exemple : “_PATH_INFO”).

Configuration du pipeline en JSON
Dans le mapping table, nous allons ajouter une constante de JSON (associé à “$tables_info” comme vu sur l'image précédente. Cette constante permettra de paramétrer le comportement de notre pipeline en fonction des tables que l'utilisateur lui demande de traiter. Pour l’instant, voici sa structure et ses valeurs ci-dessous :
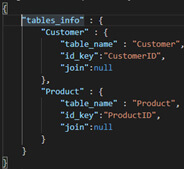
Pour faire simple, il est accordé à chaque point d’entrée de l’API ("Customer”, “Product”) une série de paramètres comme le nom de la table associée à la requête, ainsi que sa clef de filtrage (“id_key”). Nous verrons plus tard à quoi sert l’attribut “join”.
L’utilisation d'une constante JSON et toutes ces informations nous permettent de :
- Configurer l’API à partir d’un seul point (pratique pour les développements et la maintenance).
- Séparer les noms physiques (des objets traités) et les noms logique (comment ils sont appelés par l’utilisateur)
- Définir les tables qui pourront être requêtée (pas d’équivalence = pas de requête = sécurité supplémentaire).
Pour rappel : JSON.parse(‘<json>’) permet de transformer une chaine de caractère en objet JSON. La syntaxe d’accès à un élément dans cet objet serait par exemple :

Le routage de notre API
On remarque une redondance dans les traitements que nous voulons faire avec cette API. Dans le cas des trois points d’entrée, nous avons le choix d’utiliser ou non un filtre. Nous pouvons factoriser cela en définissant deux routes d’accès aux données. Une avec un filtre, l’autre non.
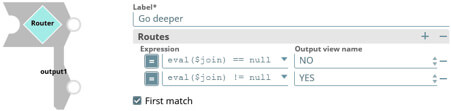
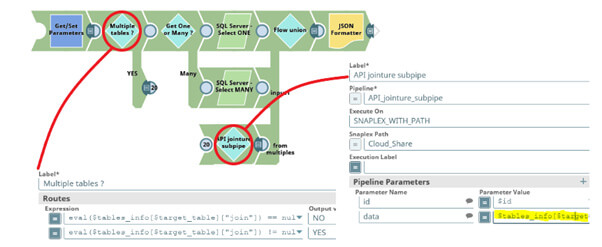
Pour définir de multiples chemins, nous allons utiliser le snap "Router" qui prend une entrée, effectue des évaluations, et selon certaines conditions, redirige le flux vers une ou plusieurs sorties possibles.
Ici le facteur discriminant est le paramètre utilisateur "id", donc s’il est initialisé, nous passerons par la voie “One”, sinon nous passerons par la voie « Many ». On utilise la fonction « eval() » qui nous permet de déterminer sa valeur dynamiquement.

N’oubliez pas de cocher la case “First match”, c’est une sécurité supplémentaire. Cela va automatiquement arrêter le traitement du snap “Router” à la première expression vraie.
Configuration du reste du pipeline - Requêtes de sélection et formatage en JSON
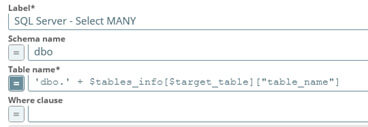
Pour le restant des snaps du pipeline, il nous faut récupérer les données depuis SQL Server. Pour ceci, rien de plus simple, il faut glisser-déposer un snap “SQL Server – Select" depuis la palette des snaps, relier le compte “SQL Server” que nous avions créé et mettre le nom de la table qui supporte la requête.
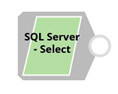
Nous avions précisé ce nom de table dans notre JSON. Nous allons créer deux types de sélections :
- Une sélection avec un filtre sur la "clef de filtre" associée au nom de la table

- Une sélection sans filtre
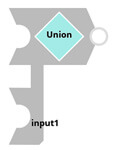
Les APIs de SnapLogic ne supportent qu’un seul point d’entrée et un seul point de sortie. Il faudra donc bien penser à relier tous les points d’entrées et sortie du pipeline. Ici, nous avons deux sorties (“select ONE” et “Select Many”) il faut donc relier ces deux sorties afin qu’elles n’en produisent qu’une seule. Pour cela, on peut utiliser le snap “Union”.
Il faut aussi formater les résultats qui seront produits. Nous allons exposer au format JSON les résultats des requêtes. Pour cela il faudra utiliser le snap “JSON Formatter”.

À la fin de ce point, notre pipeline devrait ressembler à ceci :
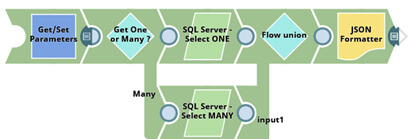
L’utilisateur peut maintenant requêter “Customer” et “Product” via la même tâche/Pipeline. Il peut aussi filtrer les données grâce à un identifiant s’il le souhaite. Si le développeur voulait ajouter la possibilité de sélectionner la table “Address”, il n’aurait qu’à rajouter les bonnes valeurs dans le JSON de configuration. Soulignons que tout ceci est géré en un seul pipeline.
Création de l'API Partie 2 - Mise en place de la stratégie de jointure
Dans les points précédents, nous avons réussi à requêter dynamiquement, et selon les demandes utilisateurs, n’importe quelle table de notre base de données (à condition que le développeur l’ait permis via le JSON). Cependant, si, par exemple, l'utilisateur voulait récupérer les achats des clients, il faudrait joindre la table “Customers” et la table “SalesOrderHeader” ainsi que la table “Product” pour avoir toutes les informations des clients, des produits et des conditions de vente. Notre système n’est actuellement pas capable de faire une jointure dynamique entre deux tables.
Dans le principe, il serait très intéressant de pouvoir utiliser le JSON pour définir les règles de jointures, et d’adapter notre pipeline afin qu’elle applique dynamiquement ces règles. Pour ceci, nous allons utiliser un algorithme récursif.
Principe de récursivité
En programmation, la récursivité est caractérisée par une fonction (dans notre cas, un pipeline) s’appelant elle-même. Avec un système de pile d’appel (dernier appelé, premier résolu), on vise à calculer le dernier élément, avant de résoudre la chaine d’appel . Pour que la chaine d’appel puisse s’arrêter, il faut donc une condition d’arrêt (gare à l’erreur “Stack overflow” dans le cas contraire).
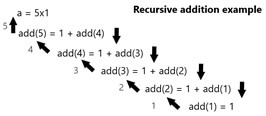
Suivant ce principe, dans notre cas, nous allons utiliser cette récursivité pour joindre à une table le résultat de l’exécution suivant (qui est donc une table). La condition d’arrêt est qu’il n’y ait plus de requête restante. Dans ce cas, on récupère une table unique.
Mise en place de la récursivité avec SnapLogic
Dans un premier temps, paramétrons notre JSON afin de déterminer les règles de jointures. Il nous faut le nom de deux tables et la clef qui permet de les relier. Nous allons utiliser l’attribut “join” pour préciser la table suivante à traiter, qui sera elle-même composé d’un élément “join”, etc. Ajoutons aussi une clef de jointure différente de la clef de filtrage (au cas où elle ne serait pas la clef primaire de la table). Pour notre exemple “Customer_buy”, il faudrait rajouter le JSON ci-dessous dans notre constante JSON (“tables_info”) :

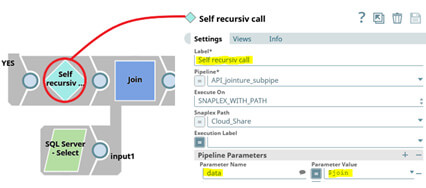
Attaquons-nous à la jointure récursive. Créons un pipeline “API_jointure_supipe” (pas besoin de créer une tâche, vu que ce pipeline ne sera pas requêtable par l’utilisateur). Nous lui donnerons le paramètre “data” qui contiendra une partie du JSON de “tables_info” (par défaut, ce qu’il y a entre les crochets associés à "Customer_buy") :
Créons maintenant un “Mapper” qui va définir les variables que nous allons utiliser en fonction de “data”:

Nous allons maintenant définir la condition d’arrêt ou de continuation de la récursivité. Le facteur discriminant est “join”, s’il est initialisé, nous devons aller plus profond. Sinon, nous pouvons commencer à résoudre la chaine d’appel. Dans un routeur, définissons les conditions suivantes (précisez le “first-match”, c’est une sécurité supplémentaire) :
Pour le traitement d’arrêt, utilisons dans un premier temps un snap “SQL Server – Select" qui va requêter la table “$table_name”.
Pour le traitement récursif nous allons joindre la table actuelle au résultat de l’exécution suivante, qui aura pour paramètre “data”, ce qu’il y a dans le “join” du paramètre “data” actuel (donc l’élément suivant) :
N’oublions pas de joindre les deux sorties avec une Union. Le pipeline “enfant” final devrait ressembler à cela (les points “57” indiquent que les deux snaps sont reliés entre eux) :
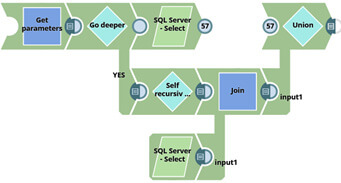
Revenons maintenant sur notre pipeline “Parent”. Il faut que nous déterminions un moyen d’accès à ce pipeline lorsque nous avons un comportement à jointure (donc quand “join” n’est pas “null”), ajoutons un routeur qui évalue la “nullité” de “join”, puis si “join” a été initialisé, la pipeline enfant est appelée avec les données de “$tables_info[$target_table]” :
Résultat et analyse de notre API
Nous avons une solution qui permet d’exposer n’importe quelle table d’une base de données, de générer des jointures à la volée et de les exposer sous le format JSON pour les utilisateurs.
Le comportement du pipeline est résumé dans une variable de configuration au format JSON (qui pourrait être un fichier pour être plus “propre”, ou même le résultat d’une autre API) dont le seul maître reste le développeur. La solution est maintenable, et peut être enrichie très facilement.
Si l’on veut ajouter des tables ou des requêtes, on peut les ajouter très facilement en quelques lignes de JSON. Idem si une nouvelle table vient d’être créée ou modifiée dans le Datastore.
Les avantages de cette API
- Agilité : Si une table est ajoutée dans la base de données lors de développements (par exemple), elle est facilement intégrable dans le système. Cela répond à des problématiques de développements avec des préceptes Agiles.
- Généricité : Cette solution est versatile et peut aussi être utilisé pour n’importe quelle base de données ou schéma, intégrable dans n’importe quel Système d’information.
- Flexibilité : Elle est aussi extrêmement flexible et pourra supporter un gros montant d’améliorations / développements.
- Maintenabilité : La maintenabilité est incroyablement simple SAUF si l’on touche au format du JSON d’entrée. Il faut donc faire attention à orienter son développement en priorité sur ce fichier de configuration.
Idées d'améliorations de notre solution
Cette solution est un début, une preuve de concept, qui a pour but de démontrer la puissance que l’on peut tirer d’un outil tel que SnapLogic avec de bonnes méthodes.
Ce noyau exécutif est bien-sûr améliorable et a été fait pour qu’on puisse ajouter des fonctionnalités comme récupérer le JSON depuis un fichier stocké, ou même depuis un logiciel tierce ayant pour objectif de l’automatiser, gérer les possibilités que les utilisateurs puissent eux même injecter le JSON, etc.
function manageBackwardButtonDisplaying() { var referrerHostname = !!document.referrer ? (new URL(document.referrer)).hostname : null; var hostname = (new URL(window.location.href)).hostname; var referrerIsNotNext = (hostname !== referrerHostname) var backwardButton = document.getElementById("backward_button"); if (!!backwardButton && !!referrerIsNotNext) { backwardButton.style.display = "none"; } } window.onload = manageBackwardButtonDisplaying;
Vous souhaitez en savoir plus sur SnapLogic ? Rendez vous sur la page Contact
Next Decision, des consultants SnapLogic à Nantes, Brest, Niort, Le Mans, Angers, Laval, Rennes, Paris, La Roche-Sur-Yon, Lyon, Grenoble, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Agen, Bayonne, Montpellier, Béziers…
Next Decision, votre référence pour un projet SnapLogic en Bretagne, Pays de la Loire, Nouvelle-Aquitaine, Région Parisienne, Ile de France, Auvergne-Rhône-Alpes, Occitanie, Provence-Alpes-Côte d'Azur…