

Contexte général
Semarchy xDI est un outil d’intégration des données. Il se présente sous la forme d’un ELT (Extract-Load-Transform) qui permet de traiter des flux de données de bases à bases, mais aussi depuis et vers des fichiers, des Datalakes, etc. Outre une large palette de technologies de stockage et de flux des données intégrés, Semarchy xDI est aussi capable de consommer et de développer des web-services, une fonctionnalité très utile dans un contexte d’APIsation, sujet très en vogue ces dernières années.
Dans cet article, nous allons voir comment créer un flux API REST (méthode GET) via Semarchy xDI, et comment la déployer sur l’outil Analytics. L’API ainsi développée exposera nos données en temps réel. Nous évoquerons aussi les limites techniques et comment les dépasser grâce à des choix judicieux d’architecture.
Nous ne verrons pas comment l’exposer au grand public, cette tâche étant plutôt réservée à un outil de type API Manager, que Semarchy ne souhaite pas intégrer dans sa solution.
Étape 1 : Analyse des spécifications
Pour faire une bonne API, il faut d’abord analyser les besoins et récolter les informations suivantes :
- La/les table(s) sources
- Une structure JSON en cible qui devra être reverse
- Les codes et message de retour d'erreur / de succès. Dans notre cas :
- Code 200 + JSON pour un retour avec succès
- Code 400 + message d’erreur quand la requête est mal formatée
- Code 404 + message d’erreur quand aucune valeur n’est trouvée
- Les paramètres d'entrée, dont ceux obligatoires. Dans notre cas :
- Id_user : l’identifiant de l’utilisateur (obligatoire)
- NIG (Numéro d’Identification Général) : un champ technique (obligatoire)
- Les contraintes/filtres, limites (TOP n), ou ordre de tri des données à retourner
Dépendant du contexte, il est intéressant de définir à l’avance une requête optimisée pour limiter le temps de traitement de l’API. Cela permettra de diminuer la charge du runtime, chargé de répondre à chaque appel.
Étape 2 : Création des métadata
Avant de commencer à développer une API, nous allons avoir besoin d'un JSON et d'une table source. Le JSON va être notre retour de données en cas de succès de l'API.
Reverse du JSON
Pour "reverse" le JSON, il y a plusieurs moyens. Nous allons l'isoler dans un fichier en local et le corriger si son format n'est pas bon (présence de commentaires, de "...", etc.). Ensuite, dans le designer de Semarchy xDI, il faut créer une métadata au type "JSON SCHEMA".
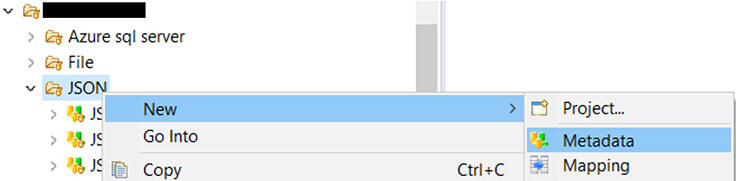
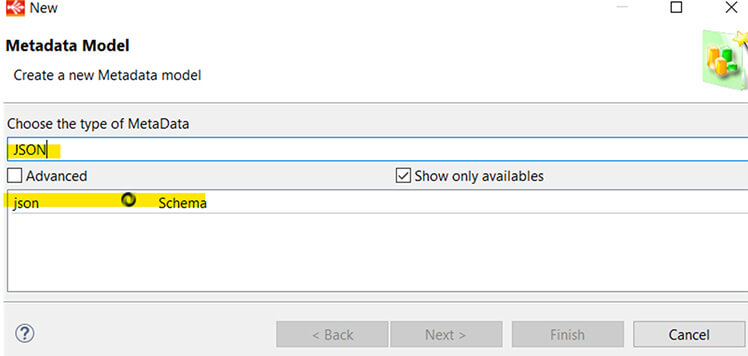
Une fois la métadata type JSON créée, le wizard de reverse engineering va s'afficher automatiquement. Ici, vous allez pouvoir charger le fichier qui contient l'exemple de JSON pris dans les spécifications (avec « Browse »), puis cliquer sur le "Reverse" à côté pour pouvoir accéder à l'étape suivante.
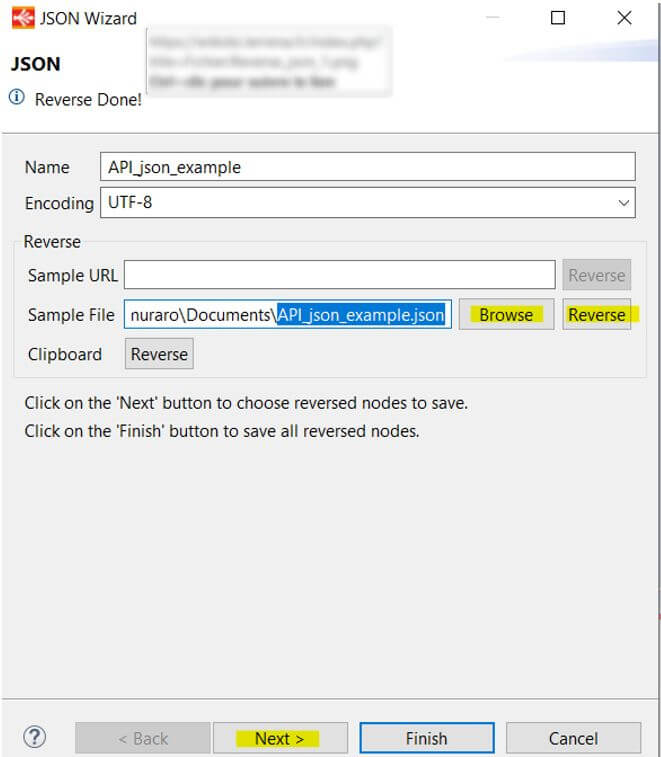
L'étape suivante consiste à prendre les champs que nous voulons garder dans notre métadata finale. Vous pouvez simplifier l'action en cliquant sur "check all" en haut à droite.
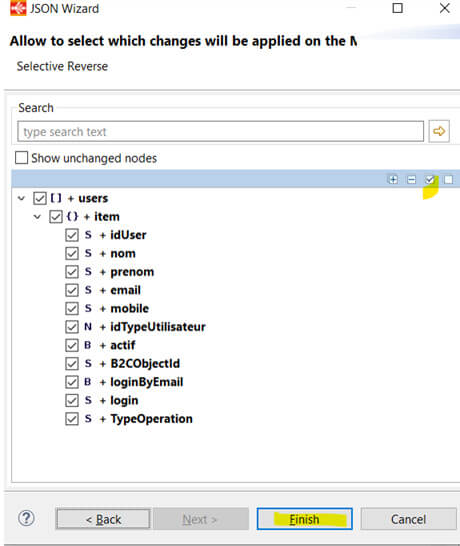
N'oubliez pas de sauvegarder votre métadata.
Notez bien qu'il est possible de "reverse" le presse-papier. Cela peut être intéressant pour gagner du temps quand l'exemple est déjà bien formaté.
Reverse de la/des table(s) à exposer
Pour que la requête de l'API ne soit pas influencée par l'utilisation de la base de données en termes de temps d'exécution, nous avons mis en place une base de réplica de notre datahub. Cette base de réplica est en lecture seule.
Pour "reverse" une table dans une métadata Semarchy concernée, allez dans la métadata, puis, au niveau du schéma, faites clic droit > action > launch data schema wizard.
Sur l'étape suivante, vous pouvez confirmer ou changer la base et le schéma que vous voulez utiliser. Ici, nous n'avons pas besoin de modifier : il faut aller à l'étape suivante.
Sur l'étape suivante, vous allez devoir choisir la table à reverse. Vous pouvez la filtrer par nom (syntaxe du "like" SQL, les wildcards sont en "%"). Enfin, vous pouvez finir. Votre table devrait s'afficher dans la métadata.
N'oubliez pas de sauvegarder.
Nos métadata sont bien précisées, nous pouvons donc commencer avec la création du process de l'API.
Étape 3 : Création du Process
Une fois le process créé, nous allons voir ce que l'on met dedans. Voici le process finalisé. Les détails seront développés sur les points suivants.
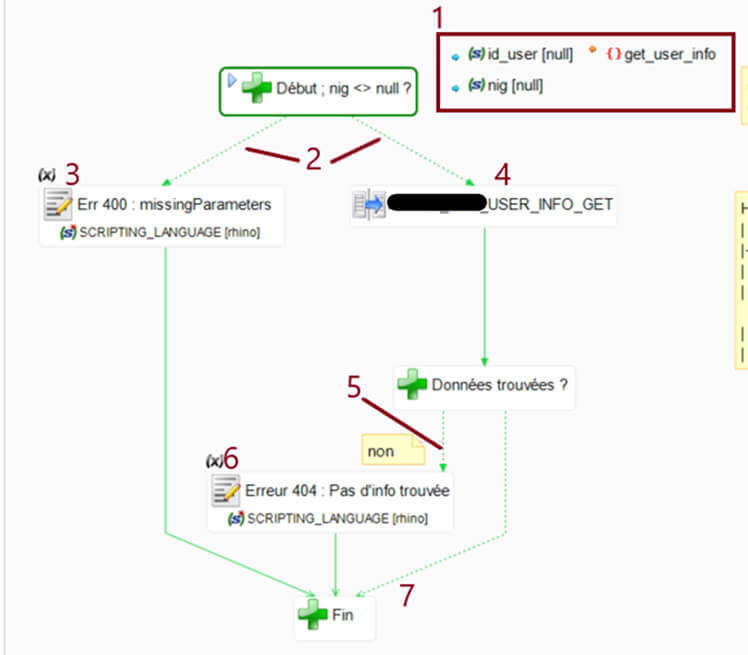
Développement du process
Dans ce process, nous pouvons voir les points suivants :
- Les paramètres d'entrée/sortie
- Les conditions sur les paramètres d'entrée
- La génération d'erreur 400 par un script rhino
- Le mapping de récupération des données et de génération du JSON
- Les conditions sur le nombre de données renvoyées par le mapping
- La génération d'erreur 404 par script rhino
- La fin de l'API avec les flèches "non mandatory"
Paramètrer le process pour qu'il réponde comme un webservice
Avant d'aller plus loin dans le développement, il nous faut paramétrer notre process pour qu'il soit considéré comme un web service. Pour cela, il faut aller dans les paramètres du process (onglet "Properties" du designer), dans le sous-onglet "Meta-inf", puis ajouter le bout de code suivant dans la zone de texte :
<httpRestWebServiceProperties extractRequestInfo="true">
<responseCodeMapper parameterName="ResponseCode" />
<responseBodyMapper parameterName="ResponseBody" charset="UTF-8"/>
</httpRestWebServiceProperties>
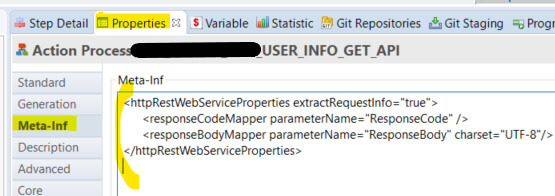
Ces lignes signifient que l’on va donner à notre process un code et un corps de réponse. Le code va correspondre au statut de retour (200, 404, 500, etc.) et le corps est le contenu de la réponse (en l’occurrence notre JSON de sortie).
Paramètres d'entrée/sortie
Paramètres d'entrée
Les paramètres d'entrée/sortie permettent à notre API d'être paramétrée par le texte de la requête. Les paramètres d'entrée sont symbolisés par la petite flèche bleue et sont à préciser dans l'URL de la requête. Par exemple :
{url}/GET_USER_INFO_API?nig=123456&id_user=ID123456)
Ils sont accessibles dans la palette de composant du designer, dans le premier bloc "Component".
Pour préciser si un paramètre est une entrée, il faut sélectionner le paramètre, puis aller dans l'onglet "Properties", dans le sous-onglet "Publication" et le définir comme "input"
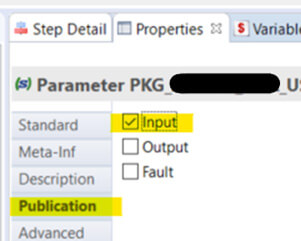
Les paramètres obligatoires auront la valeur par défaut "null". Il est intéressant de mettre une valeur par défaut à tous les paramètres d'entrée, car cela les rendra plus facilement testables.
Paramètre de sortie
Le paramètre de sortie est le nœud principal de la métadata JSON que l'on a glissé-déposé dans le process.

Pour préciser que ce paramètre est une sortie, il faut aller dans l'onglet "Properties", dans le sous-onglet "Publication" et le définir comme "output" de la même manière que les paramètres d'entrée.
Utilisation de paramètre dans le package
Pour utiliser un paramètre dans le package, nous devons utiliser la syntaxe suivante :
${~/nom_du_parametre}$.
C'est une syntaxe XPath qui nous donnera la valeur du paramètre. Dans cette syntaxe :
- ${}$ : signifie que nous accédons à une méta-information (information liée au process)
- ~ : signifie que nous accédons à un élément à la racine absolue du process et pas un sous-élément (si nous avions un autre sous-process par exemple)
- nom_du_parametre : le nom du paramètre de process auquel on veut accéder.
NB : les paramètres sont générés avant l'exécution du code. Aussi, il est généré de manière brute. Imaginons utiliser ce paramètre dans une requête SQL en ayant un paramètre id_user=ID123456. Si l'on écrit cela dans un package :
SELECT ${~/id_user}$
Cela nous donnera la requête exécutable suivante :
SELECT ID123456
Qui sera considérée comme faute de syntaxe, car le paramètre (de type string) n'est pas encapsulé par des simples guillemets. Voici donc la bonne syntaxe :
SELECT '${~/id_user}$'
-- qui donnera la syntaxe
SELECT 'ID123456'
Conditions de paramètre d'entrée
Les conditions portant sur les paramètres d'entrée, nous permettent d'éviter une requête si un des paramètres obligatoires n'est pas précisé. Pour cela, nous utilisons une condition sur les flèches. Pour déterminer une condition, il faut cliquer sur la flèche et aller dans l'onglet "Expression Editor" du designer.
Dans notre exemple, voici le code qui est utilisé :
- Pour activer la flèche vers l'erreur 400, il faudra tester avec un "OU" booléen si chaque paramètre est null:
'${~/nig}$' == 'null' || '${~/id_user}$' == 'null'
- Pour activer la flèche vers la suite de l’API, il faudra tester avec un "ET" booléen si chaque paramètre n'est pas null:
'${~/nig}$' != 'null' && '${~/id_user}$' != 'null'
Maintenant que nos conditions sont bonnes, il nous faut générer cette erreur.
Génération de l'erreur 400 : Bad request
Dans la documentation des API REST, l'erreur 400 est levée quand la requête à l'API n'est pas bonne (syntaxe, manque de paramètres obligatoires, paramètre incohérent). Ici, nous nous sommes concentrés sur les erreurs liées aux paramètres obligatoires manquants.
Pour générer l'erreur 400, deux variables inhérentes aux web services sont à publier pour générer l'erreur. Nous allons scripter l'affectation du code et du message de retour à la main.
Le composant "script" se trouve dans le bloc "scripting" de la palette de composants. Il faut bien vérifier que le langage est le rhino (une espèce de Javascript interprétable par une machine virtuelle Java).
Voici le code que nous allons insérer dans l'éditeur d'expression :
__ctx__.publishVariable("../ResponseCode","400");
__ctx__.publishVariable("../ResponseBody",'{"Code":"${~/ResponseCode}$", "Message":"One or more parameter is missing"}');
__ctx__.publishVariable est une fonction d’xDI qui permet de publier une variable dans le process. Ici nous publions ResponseCode et ResponseBody, accessibles ensuite par la requête xPath ${../ResponseCode}$.
Ces variables sont ensuite automatiquement utilisées par le process comme code et message de retour.
Récupération des Données
Dans la documentation des API REST, le code de retour 200 signifie que tout s'est bien passé et que l'API est en succès.
Maintenant que l'on sait que tous les paramètres obligatoires sont bons, nous pouvons aller dans le mapping. Il faut d'abord avoir créé le mapping comme décrit dans l'étape 4, puis le
glisser-déposer sur le process. Nous verrons comment remplir le mapping dans un prochain point.
Condition de génération de l'erreur 404
Dans la documentation des API REST, le code d'erreur 404 signifie que l'entité cherchée n'a pas été trouvée. Dans notre cas, en back-end, elle est déclenchée quand le mapping n'a renvoyé aucune donnée.
Pour détecter le nombre de données rendues, nous allons utiliser une condition de lien (ou flèche). Cette condition s'appuie sur la statistique "SQL_NB_ROWS", une statistique inhérente à xDI, qui permet de récupérer le nombre d'enregistrements générés par le mapping (en sélection, insertion, mise à jour ou suppression).
- Dans l'éditeur d'expression du lien vers le scripting de l'erreur 404, il faut mettre le code suivant :
__ctx__.sumVariable("SQL_NB_ROWS","~/map_USER_INFO_GET") == "0"
- Dans l'autre lien (qui pointe directement vers la fin), il faut mettre la condition antagoniste :
__ctx__.sumVariable("SQL_NB_ROWS","~/map_USER_INFO_GET") != "0"
Explication sur ce bout de code :
- La fonction __ctx__.sumVariable(param1, param2) : permet de faire le cumul des variables portant le nom précisé dans le paramètre 1 qui sont remontés dans l'objet en paramètre 2 (ici notre mapping)
- "SQL_NB_ROWS" : la statistique à agréger
- "~/map_USER_INFO_GET" : le nom du mapping dans lequel on veut récupérer la/les variables
- == "0" : "est égale à 0"
Pour une API utilisant un autre mapping, on précisera un nom de mapping différent.
Génération de l'erreur 404 par scripting
Tout comme pour l'étape de génération de l'erreur 400, nous allons utiliser un script Rhino pour marquer à la main les codes et messages de retour.
Le code est sensiblement le même, seuls les messages sont différents :
__ctx__.publishVariable("../ResponseCode","404");
__ctx__.publishVariable("../ResponseBody",'{"Code":"${~/ResponseCode}$", "Message":"data not found for nig = ${~/nig}$ and id_user=${~/id_user}$"}');
Liens non mandatoires
Par défaut les liens sont précisés comme "Mandatory". Cela signifie que l'ensemble des liens qui pointent un champ doivent être activés pour que l'étape pointée puisse s'activer. Cela ne va pas avec notre API. Nous voulons que l'étape "Fin" soit exécutée dès qu'un lien est activé (que ce soit pour une erreur ou un succès). Pour cela, il faut aller dans l'onglet des propriétés des liens, et les préciser comme "Not Mandatory".
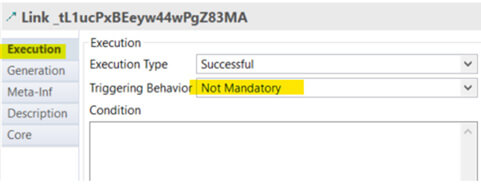
Étape 4 : Création du Mapping
Les mappings sont assez classiques si vous avez l’habitude du designer xDI avec une ou plusieurs tables en source et un JSON en cible. Soyez tout de même vigilants sur l’optimisation de vos requêtes.
Si une requête est trop complexe à mettre en œuvre de manière optimisée, ou qu'elle utilise des spécificités impossibles à implémenter avec les mappings xDI (« SELECT TOP n » par exemple), il faudra penser à utiliser une requête métadata. Nous allons voir tout cela dans les points suivants.
Requête métadata
Attention, pour une question de maintenabilité, les requêtes métadata ne sont pas favorisées. Elles nécessitent une véritable amélioration par rapport aux mappings "classiques", ou l'utilisation de termes SQL spécifiques (tels que "TOP") pour pouvoir être utilisées. Si le mapping est simple, il faut TOUJOURS le privilégier par rapport à une requête métadata.
Pour créer une requête métadata, il faut aller dans la métadata (ici MCL_Replica), dans le dossier "Queries" et faire clic droit > new > query

Saisissez un nom et une requête SQL exécutable. Sauvegardez puis faites clic droit > reverse. Les colonnes vont donc être automatiquement générées avec un nom et un type. Vous pouvez ensuite ajouter vos variables dans la requête ('${~/nig}$' par exemple).
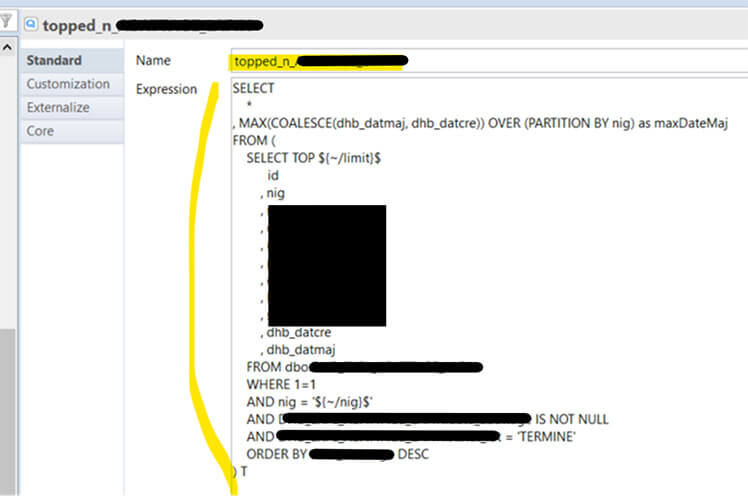
Sauvegardez bien et vous pourrez ensuite glisser-déposer votre requête de métadata comme une table dans un mapping.
Mapping vers un JSON
Ce que vous pouvez voir dans ce mapping :
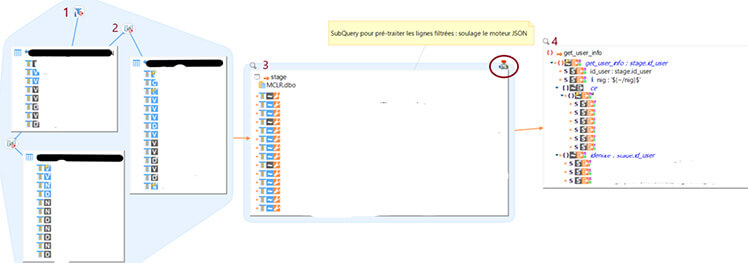
- Source - Filtre
- Source - Jointure
- Stage. Encerclé en rouge, le template de stage est à changer en mode "subquery"
- Cible
Nous n’allons pas aller dans les détails des éléments de la source. Si vous êtes habitués à l’utilisation du designer, vous ne serez pas perdus. Si non, n’hésitez pas à vous référer au guide du développeur de la solution.
Ajouter et remplir la Cible JSON
Pour remplir le JSON cible, c'est assez simple, en glissant-déposant un champ, choisissez Map dans le menu contextuel.
Ce qu'il faut comprendre est le système de génération par clef. Dans notre exemple, les champs notés sous forme de {} sont des items. Ces items seront générés une fois pour chaque clef qu'on lui donne. Il faudra donc bien faire attention à la « maille » utilisée pour générer ces éléments.
Si on ne précise pas que l'on veut une liste de valeurs (avec des []) et que l'on a plusieurs valeurs en tant que clef, le moteur JSON de xDI risque de générer une erreur.
Les clefs d’items et de listes ({}, []) n'apparaissent pas dans le JSON retourné. Une fois ce mécanisme compris, vous êtes presque prêts.
Utiliser les TAGS pour ordonner des enregistrements dans le JSON
Il est possible de communiquer directement avec le compilateur et de lui dire dans quel sens ordonner des enregistrements en fonction de clefs dans le JSON.
Si vous zoomez assez sur la cible dans l'image, vous pourrez voir un petit carré noir avec un "T" sur un des champs. Ce petit carré noir signifie que nous avons précisé un TAG.
Pour ajouter un TAG, il faut cliquer sur le champ que vous voulez utiliser pour le tri, puis, dans l'onglet "Properties" du designer (dans le sous-onglet standard) vous trouverez le bloc "Tags". Pour ajouter un tag, il faut préciser son nom et appuyer sur le "+".
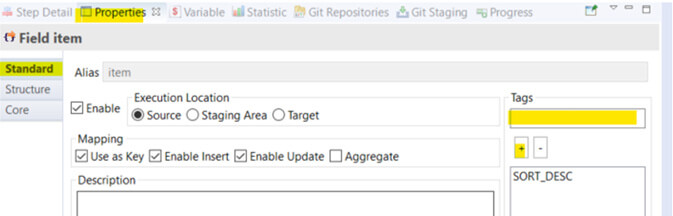
Le nom du tag est important et n'est pas facile à trouver. Il faut, le plus souvent, aller fouiller dans les process des templates de génération du code (qui peuvent se trouver en faisant un clic droit > prepare et en explorant les templates via l’onglet « Step Details »).
Pour notre cas, il en existe quatre utilisables dans un template "SQL to JSON/XML" :
- SORT_DESC : permet de ranger les éléments dans l'ordre décroissant dans le JSON Final
- SORT_ASC : permet de ranger les éléments dans l'ordre croissant dans le JSON Final
- IS_NILLABLE (par défaut) : permet à un champ null d'être affiché dans le JSON Final
- IS_NOT_NILLABLE : permet la non-génération d’un champ à l'affichage s'il est explicité à "NULL"
Étape 5 : Tests et Déploiements dans Analytics
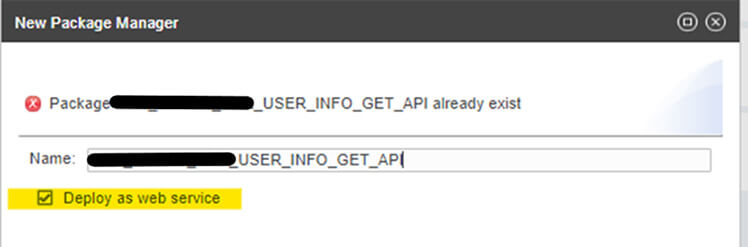
Déployer
Pour déployer une API, c'est le même principe que pour le déploiement d'un package de flux. Il faut cependant bien penser à créer le package manager comme contenant un web service.
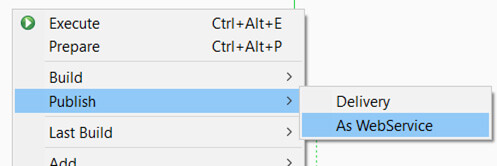
Tester
Pour tester votre API en local, vous pouvez faire un clic droit > publish > as Web service.
Ensuite, vous pouvez utiliser un navigateur ou un utilitaire type Postman en précisant l'url du runtime + le nom du package + les paramètres obligatoires.
Par exemple :
http://{url du runtime}:42200/rest/StambiaDeliveryService/3/default/{nom_du_package}?parametre_1=123 456¶metre_2=ID456789
Pour avoir une bonne batterie de tests, il vous faudra tester les erreurs 400 et 404, puis les codes de retours 200 ainsi que chaque paramètre unitairement. Il est possible d’industrialiser les tests de ces APIs via des scripts Python, Powershell, etc. Ces tests unitaires sont importants pour vérifier les non-régressions en cas d’ajout de fonctionnalités dans vos APIs.
À Propos du Garbage Collector du Runtime
Le quoi ?
Pas de panique, nous allons voir cela ensemble !
Le Garbage Collector est un utilitaire inhérent aux JVM (Java Virtual Machines) sur lesquelles tournent nos runtime Semarchy xDI. Pour simplifier, il permet de recycler de la mémoire allouée à la JVM en libérant physiquement des objets inutilisés ou déjà « supprimés » logiquement par l’application JAVA qui tourne dessus. Dans notre cas, cela évite au runtime de saturer en termes de mémoire vive et de se bloquer au bout de 100 exécutions de package (c’est donc une bonne chose !).
Cependant, si vous expérimentez les APIs développées avec Semarchy, vous serez sans doute face à un souci d’emballement du runtime (les requêtes d’APIs mettront de plus en plus de temps à répondre, jusqu’à « casser » le runtime). Ce souci est lié au Garbage Collector, qui, quand une charge devient trop importante, est obligé de prendre plus de mémoire vive allouée à la JVM pour pouvoir libérer tous les objets. Et ce, jusqu’à prendre une trop grosse place dans l’équilibre des mémoires allouées pour chaque utilitaires de la JVM.
Pas de panique, j’ai dit ! Il existe un moyen de corriger, compenser ou du moins lisser ce souci !
Choix architecturaux à envisager
Dans un premier temps, utiliser une version récente de Java est conseillé (la version 11 montre de meilleurs résultats que la version 8).
Ensuite, l’utilisation d’un API Manager puissant permettra de rendre transparent ce souci.
Voici quelques idées de services auxquels penser :
- Health check et Auto-Heal : l’API Manager va interroger une API particulière et définira l’état de santé de votre runtime en observant le temps de réponse. Lorsque le temps de réponse sera trop grand, l’Auto-Heal va redémarrer l’instance du runtime.
- Utilisation de conteneurs Docker multi instances : les conteneurs docker permettent d’encapsuler facilement les éléments applicatifs d’un SI. Ici, nous voudrons conteneuriser notre runtime, pour faciliter son redémarrage et « l’allumage » de plusieurs instances de ce même runtime.
- Load Balancer (répartisseur de charges) : ce service équilibrera de lui-même la charge des requêtes sur les différentes instances de notre runtime. En combinaison avec le système d’Auto-Heal, il permettra de rediriger les charges de notre instance « malade » vers une instance en bonne santé.
Conclusion
Nous avons vu comment exposer des données à des tiers en créant rapidement une API REST (méthode GET) via Semarchy xDI, depuis ses spécifications jusqu’à son déploiement. Les APIs ainsi créées peuvent répondre aux problématiques de temps réel.
Nous avons aussi vu que Semarchy ne proposait pas de service d’API Management, indispensable quand il s’agit de développer et exposer des APIs. L’API Manager vous permettra de lisser, voire gommer les phénomènes d’emballement des runtimes via des services spécifiques à vos besoins, et proposera une plateforme sécurisée pour partager vos APIs.
Nous n’avons qu’effleuré le domaine du possible, mais sachez que le principe reste équivalent pour développer des APIs avec les méthodes POST, PUT, DELETE, etc. Semarchy xDI propose une expérience à ses utilisateurs, cohérente et orientée métiers. Cela permet de se concentrer sur les besoins métiers, et d’avoir un workflow similaire, qu’importe les technologies en jeu.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Semarchy xDI ? Rendez vous sur la page Contact