

Les objectifs de cet article sont de vous partager les bonnes pratiques de développement dans la création d’une application Qlik Sense à la fois en termes de modélisation / alimentation et de restitution.
Il s’agit de recommandations qui peuvent être appliquées dans la mesure où le contexte technique et fonctionnel de l’application développée le permet.
Ces bonnes pratiques ont comme objectif principal l’optimisation des développements et des ressources.
Les fondamentaux de Qlik Sense
Dans un premier temps, nous allons rappeler les éléments fondamentaux d’une application et de l’architecture Qlik Sense afin de mettre en perspective et de contextualiser les recommandations qui seront données par la suite.
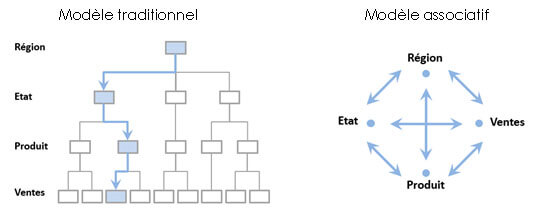
Modèle associatif Qlik Sense
La caractéristique clé dans le fonctionnement de Qlik Sense est son modèle associatif. Il s’agit d’une différence majeure avec d’autres outils décisionnels traditionnels qui fonctionnent avec des filtres propagés via des requêtes SQL basées sur des jointures prédéfinies par le développeur. Dans Qlik Sense, chaque action de l’utilisateur va filtrer automatiquement l’intégralité du modèle.
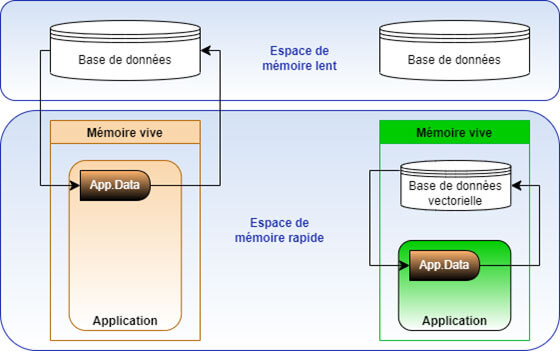
Le fonctionnement in-memory de Qlik Sense
Qlik Sense fonctionne avec le principe du chargement de données in-memory, ce qui signifie que les données sont directement stockées dans l’application Qlik Sense (*.qvf), d’où l’intérêt d’appliquer des normes de développements pour éviter des applications trop volumineuses et garantir les performances.
Qlik intègre une base de données vectorielle qui se trouve dans l’espace de mémoire rapide, ce qui accroit ses performances et nous amène à concevoir différemment la façon d’interroger et de stocker les données par rapport à un outil traditionnel.
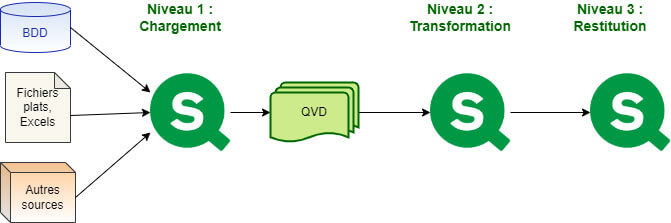
Architecture Qlik Sense
L’architecture recommandée dans le développement des applications Qlik Sense est l’architecture 3-Tiers. Elle consiste dans un premier temps à extraire des données depuis des sources multiples, puis à transformer ces données en appliquant les règles métiers et enfin à restituer l’information avec des visuels graphiques.
Entre chaque niveau, des fichiers. QVD servent à stocker les données (1 QVD = 1 table) de manière optimisée.
Extraction des données avec Qlik Sense
Qlik Sense permet de se connecter à des sources de données multiples telles que des bases de données (OLEDB, ODBC, Connecteurs natifs), des fichiers (Excel, plats), des APIs et bien d’autres encore.
Cette première couche est constituée d’applications Qlik Sense qui vont simplement extraire les données, sans faire de transformation, et les stocker dans des fichiers QVD.
Toutes les données doivent être vidées après la sauvegarde dans les QVD pour ne pas garder inutilement des données en mémoire.
Transformation des données avec Qlik Sense
Dans cette couche, des applications Qlik Sense sont dédiées exclusivement à transformer les données. Elles utilisent en source les QVDs de niveau 1 et servent à réaliser différentes opérations telles que :
- le renommage ou le formatage des champs
- la création de nouveaux champs
- des mappings sur les données
- des agrégations, des filtres, des calculs
- la création du modèle de données (en étoile de préférence)
Ces applications constituent des datamarts qui seront aspirés par les applications de restitution afin de récupérer le modèle de données sur lequel se baseront les graphiques.
Restitution des données avec Qlik Sense
La dernière couche est dédiée à la restitution des données. Elle chargera les données des datamarts du niveau 2 à l’aide d’une instruction « Binary » ou à partir des fichiers QVD selon la stratégie adoptée.
Les avantages de l'architecture 3-tiers
Cette architecture constitue la norme dans le développement des applications Qlik Sense. Elle peut être adaptée selon la taille de l’entité mais elle doit servir de référence. À ce titre, elle présente plusieurs avantages :
- Performance : les QVD sont des formats de fichiers optimisé pour la lecture des données dans Qlik ce qui permet de charger les données beaucoup plus rapidement.
- Flexibilité : les datamarts créés dans les applications de niveau 2 peuvent servir à plusieurs applications de restitutions.
- Maintenabilité : la séparation des niveaux et le stockage dans les QVDs permet d’identifier plus facilement les erreurs et de ne pas bloquer toute la chaine.
Nommage des applications dans Qlik Sense
Le nommage final de l’application est important car c’est ce nom qui apparaitra sur le hub Qlik Sense et doit donc être compréhensible des utilisateurs finaux.
Pour les applications de chargement et transformations de données, elles ne seront en général pas visibles des utilisateurs finaux et dans des flux dédiés. Elles pourront être préfixées de la manière suivante afin de les retrouver facilement :
- 1_XXX : pour les applications de chargement
- 2_XXX : pour les applications de transformation
Développement Qlik Sense
Modélisation Qlik Sense
La modélisation à privilégier dans Qlik Sense est la modélisation en étoile avec une table de fait unique. Une modélisation de type flocon peut pourra également être envisagée.
Le principe est de concaténer toutes les tables de faits dans une seule table qui regroupe l’ensemble des champs. Cela a pour but d’éviter de créer des boucles ou des clés synthétiques.
Une connaissance des Set Analysis sera nécessaire pour manipuler ce type de modèle. Il faudra également un champs « flag_origine » afin d’identifier la provenance de chaque ligne.
Script Qlik Sense
Le script Qlik Sense est la partie qui permet de réaliser l’alimentation des données et comme dans tous les outils, des règles peuvent être mise en place afin de faciliter la maintenance des applications et leur lisibilité.
- Le nommage des sections : il est conseillé d’avoir un onglet par axe d’analyse et un onglet pour les faits ainsi qu’un pour les tables de mapping (à placer en deuxième).
- Le nommage des tables : chaque chargement de table doit être précédé par le nom de la table en majuscule suivi.
- Le nommage des clés : les clés pourront être préfixé du caractère spécial « % » ou bien « _ » afin de les identifier facilement dans le modèle.
- Le nommage des champs métiers : il s’agit des noms qui apparaitront dans l’application au moment des sélections, ils doivent donc être compréhensible de l’utilisateur final.
- Le nommage des QVDs : le nom du QVD doit correspondre au nom de la table qu’il contient. Il pourra être préfixé par « D_ » ou « F_ » selon s’il s’agit d’une dimension et d’une table de faits.
- Le nommage des connexions : le nom des connexions pourront être préfixé en fonction du type.
- Dossier : Dir_
- Base de données : Oracle_ , SQLServer_
- ODBC : ODBC_
- RestConnector : REST_
- Etc…
Restitution Qlik Sense
Au niveau de la partie restitution des données, des règles peuvent aussi être mises en place pour améliorer l’expérience utilisateur et faciliter la maintenance pour le développeur.
- Les éléments principaux : il s’agit des objets (dimensions et mesures) qui seront mis à disposition de l’utilisateur afin qu’il puisse créer des restitutions par lui-même (principe de la BI self-service).
Ainsi, il sera important de créer l’ensemble des axes d’analyse en élément principaux de type dimension ainsi que pour les mesures pour qu’elles soient accessibles aux utilisateurs.
Le nommage de ces éléments ainsi que leur description et l’ajout des mots-clés sera important également pour faciliter la recherche de l’utilisateur. - Les variables : dans une application Qlik Sense, on peut rapidement se retrouver avec un grand nombre de variables d’où l’importance de définir des règles de nommage. Les variables pourront être préfixées par « v_ » avec une majuscule en début de chaque mot.
- La variabilisation des expressions : les expressions qui servent à calculer les mesures peuvent être externalisées dans un fichier Excel et charger dans des variables à l’aide du script. Cela permet de centraliser toutes les expressions au même endroit et de mutualiser les contextes utilisés dans ces expressions.
Nos consultants Next Decision sont experts certifiés Qlik et vous accompagnent dans votre projet Qlik. Nous pouvons également vous former ! Contactez-nous !