

Elasticsearch est un moteur d’indexation de données basé sur la bibliothèque Lucene fourni par Apache. Celui-ci fournit des interfaces pour l’ajout de données et la récupération (moteur de recherche) sous forme d’API Rest. Les données en question sont au format JSON.
Elasticsearch est généralement accompagné de deux autres produits : Kibana et Logstash. (Voir la suite ELK)
Kibana permet la visualisation des données grâce à la mise en place de graphiques et autres dashboards. Logstash est un ETL.
Pour cet article, nous allons imaginer le besoin suivant : Nous sommes une ESN qui souhaite mettre en place un moteur de recherche des CVs des collaborateurs.
L’objectif : Pouvoir rechercher facilement parmi les compétences disponibles, le tout basé sur des critères de qualifications du niveau de compétence.
Pour cela, l’entreprise dispose du CV de chacun des consultants au format DOCX. Nous ferons abstraction du principe d'extraction des données de ces documents. Cependant les données extraites sont constituées ainsi :
- Nom du consultant
- Prénom du consultant
- L’agence du consultant
- La liste des outils que maîtrise le consultant
- La liste des missions du consultant
- Date de début de la mission
- Date de fin de la mission
- Libellé de la mission
- Liste des outils utilisés pour la mission
À noter tout de même, que selon le besoin, Elastic peut être en mesure d’analyser directement le contenu textuel de chaque document. Ici, nous souhaitons avoir un système de recherche plus fin, d'où un découpage champs par champs nécessaire, notamment avec l’exploitation des dates.
Elasticsearch est un outil extrêmement complet et complexe, mais nous allons parler ici de seulement quelques éléments que nous avons eu l’occasion de tester et qui nous semblent pertinents.
Mise en place de l’index dans Elastic
Un index dans Elastic est plus ou moins l’équivalent d’une base de données dans un SGBDR plus commun (MsSQL, PostgreSQL, MySQL, etc). Il s’agit d’un “mapping” qui peut contenir plusieurs “types”.
Pour notre exemple, nous allons créer l’index suivant :

Vous devriez rapidement repérer l’ensemble des propriétés qui correspondent à notre schéma défini plus haut.
Cependant, la partie “settings” n’est peut-être pas aussi explicite. Une première rubrique concerne les “analyser” : il s’agit de méthodes définies pour l'analyse du texte. Ici l’analyser “default” permet de gérer les mots des propriétés texte de notre objet JSON en ignorant la casse et les accents. On le retrouve positionné sous chaque propriété texte du mapping.
Nous reviendrons par la suite sur la partie filter et l’analyser “synonym”.
Recherche dans plusieurs champs
Une fois l’index créé et celui-ci rempli de données, il devient possible d’écrire nos premières requêtes :
- Je souhaite récupérer les consultants ayant pour prénom Michel :
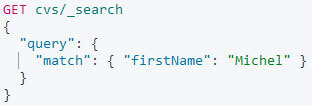
- Je souhaite récupérer les consultants ayant déjà fait du NodeJs OU du ReactJs (dans les outils du consultant ou des missions) :

Ainsi, “must” traduit le mot “et” et “should” traduit le mot “ou”.
Arrivés jusqu’ici, nous pourrions nous dire : Je souhaiterais faire une recherche approximative et que lorsque j’écris “NoteJs”, cela me retourne bien ce qui correspond à “NodeJS”.
C’est ici que les requêtes approximatives ou floues (“Fuzzy” en anglais) vont intervenir.
La recherche approximative
Les requêtes “Fuzzy” permettent de faire des recherches par similarité d’un mot. On peut imaginer un cas où un utilisateur recherche “talent” alors qu’il voulait écrire “talend”.
Dans le cas d’une telle requête, les éléments correspondant à la recherche exacte remontent en premier, et ceux qui en sont le plus éloignés, en dernier.

Il est également possible de paramétrer le niveau de proximité du mot afin d’avoir une qualité de résultat au goût des utilisateurs.
Synonyme de mots ou expressions
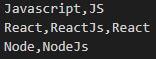
Un autre cas intéressant à gérer dans la mise en place d’un moteur de recherche, est la gestion des synonymes. Ainsi, lors d’une recherche, des mots différents, mais faisant référence au même outil, peuvent ressortir ensemble. Par exemple, faire une recherche sur “Javascript” pourrait faire ressortir “JS” grâce aux synonymes mis en place.
Ainsi, si nous reprenons le mapping créé au début de l’article, nous pouvons observer que le deuxième “analyser” fait référence à un “filter” nommé “synonym”. Ce filtre se trouve initialisé quelques lignes en dessous.
La propriété “synonyms_path” indique le chemin du fichier qui devra contenir les synonymes.
Ce fichier est un simple document texte, où chaque ligne représente un groupe de synonymes, et où chaque mot est séparé par une virgule.
Si vous utilisez également les DevContainer de Visual Studio Code (ou même tout simple Docker), vous pouvez mettre en place un volume pour partager le fichier des synonymes.

Optimisation de l’ordre des résultats
Jusqu’ici, nous avons donc un moteur de recherche capable de trouver des consultants ayant déjà pratiqué un outil (NodeJs, etc.).
L’idée est maintenant de gérer un peu mieux l’ordre des consultants retourné par notre recherche, et ce, en cherchant à qualifier leurs niveaux d’expertise.
Nous pouvons imaginer une logique qui voudrait que des consultants ayant travaillé sur une mission récente et sur un outil précis, auraient plus d’importance que d'autres ayant travaillé sur ce même outil, mais il y a des années.
Pour cela, nous pouvons manipuler le score des résultats :

Ici, en fonction de la date de fin de la mission, et ce, par intervalles d’un an, son poids est multiplié par une valeur donnée.
Ainsi, les expériences les plus récentes auront plus de poids que les plus anciennes.
A noter tout même que donner du poids à certaines propriétés peut amener à des résultats parfois absurdes. Par exemple, faire une recherche avec les nom et prénom d'une personne, mais où ceux-ci auraient moins de poids que d’autre champ, peut conduire à un résultat où cette personne n'apparaîtrait pas en première position. Il y a donc un travail d’équilibrage pour ce genre de requête.
Highlight
Un dernier élément intéressant à mettre en place est le surlignage des mots clés de la recherche ayant trouvé une correspondance dans les résultats :

Ainsi, une nouvelle propriété est ajoutée aux résultats reprenant la portion de texte et la balise où les mots ont été trouvés :

Elasticsearch est un formidable outil pour mettre en place un moteur de recherche. Les possibilités sont nombreuses et complètes. Chez Next Decision, forts de notre expérience, nous sommes en mesure de vous accompagner dans vos projets Elasticsearch.
Un projet Elasticsearch ? Un besoin de formation Elasticsearch ? Nous sommes à votre écoute ! Contactez-nous !