

Dans un contexte où le volume de données circulant au sein de l’entreprise ne cessent d’augmenter et où les défis des entreprises sont de plus en plus nombreux, disposer d’un capital de données de qualité apparaît comme une nécessité. La maîtrise de la qualité des données devient donc un enjeu important.
Data Quality, Qualité des données, c'est quoi ?
La Data Quality renvoie à la capacité d’une entreprise à mettre en place des actions pour s’assurer que les données de son Système d’Information soient correctes et pérennes à travers le temps. La maîtrise de la qualité des données est dorénavant un enjeu important. Il s’agit de fournir des données correctes, complètes, à jour et cohérentes tout en mettant en place des indicateurs peu coûteux, compréhensibles et faciles à communiquer.
La notion de qualité des données est un terme générique décrivant à la fois les différentes caractéristiques des données mais aussi l’ensemble des processus permettant de garantir ces caractéristiques. Une donnée est dite de qualité dès lors qu’elle répond aux exigences de son utilisation.
Un projet de Data Quality est un processus permanent destiné à s’inscrire dans la durée et à évoluer avec elle : il intervient donc tout au long de la chaîne data. Il suppose un changement de culture de l’organisation en matière de gouvernance des données. C’est une véritable stratégie qui doit devenir l’affaire de tous, mobilisant l’entreprise et l’ensemble de ses habitudes de travail.
La démarche de Data Quality s’inscrit dans dans le concept de “garbage in - garbage out”, dans la mesure où tout ce qui est erroné à l’entrée d’un process le sera nécessaire à sa sortie. Ainsi, axer sa stratégie sur des données dont le niveau de qualité n’a pas été vérifié aboutira à des prises de décisions inefficaces avec des impacts directs sur le ROI.
Les enjeux de la Data Quality: Pourquoi la qualité de la donnée est-elle importante ?
Qui dit données de mauvaise qualité dit conséquences importantes pour l’entreprise : les problèmes de qualité des données, outre les dommages économiques, engendrent des dépenses supplémentaires liées aux analyses approximatives et à la désorganisation opérationnelle.
La mauvaise qualité des données est principalement due aux erreurs de saisie de l’information à la source : on recense des fautes d’orthographe, des codes incorrects, des abréviations erronées… De plus, des données exactes à un moment donné peuvent devenir erronées à la suite d’un changement de situation. De nombreuses entreprises négligent d’analyser la qualité de leurs données, ce qui conduit à une exploitation de données fausses et donc d’importants impacts sur la performance et le pilotage de l’entreprise.
Enjeux de performances
Une bonne qualité des données améliore la précision des applications analytiques, conduisant alors à prendre de meilleures décisions et améliorant les procédures internes afin de donner aux organisations un avantage concurrentiel.
Enjeux financiers
Maintenir un certain niveau de qualité des données permet aux organisations de dépenser moins dans l’identification et la correction de leurs propres données.
Enjeux stratégiques
La qualité des données comme élément fondamental de la stratégie de gestion de l’information: des erreurs sur les données peuvent engendrer des pertes d’opportunités commerciales ou souffrir d’un déficit d’image
La Data Quality, un levier de compétitivité
La qualité des données devient un impératif de compétitivité dans la mesure où la non-qualité engendre des coûts puisqu’elle renvoie à l’inaptitude à répondre aux attentes des entreprises, des consommateurs ou des usagers. Le coût financier direct est le coût le plus évident de la non-qualité : toute entreprise avec des engagements vis-à-vis de ses clients supporte ce type de coûts dès lors qu’elle ne répond pas aux attentes des clients.
D’autres coûts moins évidents à identifier sont pourtant bien réels, notamment les coûts sociaux induits par la surcharge de travail au sein des équipes suite à la non-qualité d’un processus ou d’un traitement informatique, ou encore les investissements improductifs lorsque le travail effectué par l’entreprise ne débouche pas sur du chiffre d’affaires.
La non-qualité engendre également des réclamations de la part des clients puisque l’entreprise n’est pas en mesure de garantir le degré de qualité attendue. Des données incorrectes engendrent donc des problèmes dans les processus se répercutant sur la satisfaction client et par conséquent sur l’entreprise elle-même. Cette insuffisance influe également sur les relations de l’entreprise avec ses partenaires.
La non-qualité influe également sur l’image de l’entreprise ce qui engendre de nombreux impacts chez les clients : une pression à la baisse sur les prix par le client, une nécessité de faire des gestes commerciaux ou encore la perte purement et simplement du client.
Les critères de la data Quality
La Data Quality désigne l’aptitude des caractéristiques intrinsèques des données à satisfaire des exigences internes (pilotage, prise de décision) et externes (réglementations) à l’organisation.
Ces critères sont nombreux et doivent dans tous les cas être mis en perspective de l’usage et l’exploitation qui en est fait. Par exemple, lors d’une opération promotionnelle à un client lors de son anniversaire, il sera indispensable de connaître sa date de naissance exacte alors que sa tranche d’âge suffira pour mener une étude marketing ou une panélisation. Ainsi, la qualité de la donnée est relative à son exploitation. La possibilité par le système d’information d’établir des métadonnées permettant de gérer un degré de précision permettra aux utilisateurs une meilleure adéquation à leurs besoins.
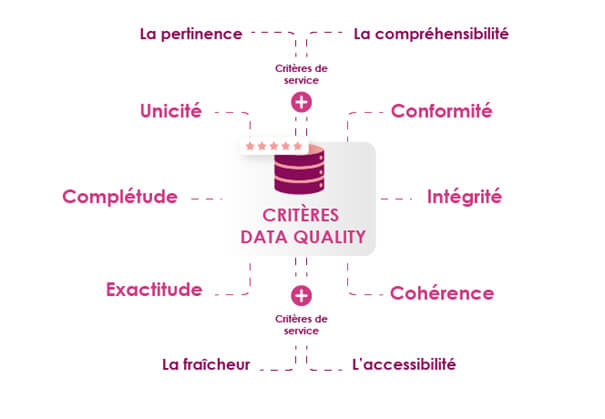
Les critères intrinsèques de qualité :
L’unicité
C’est certainement le critère de qualité le plus important. Il garantit que la donnée ne puisse pas être confondue et qu’elle réponde à un identifiant unique. Existe-t-il des doublons dans mes bases ?
L’exemple type est celui des bases de données clients pour lesquelles il y aurait un même Mr Durand dans différents outils informatiques du SI. Si notre client n’est pas dédoublonné, des erreurs d’adressage ou de valorisation de la fidélité pour le secteur du retail peuvent être préjudiciables dans la gestion de la relation avec l’entreprise.
Plusieurs solutions existent et notamment la mise en œuvre de méthodes de rapprochement simple sur des champs précis et discriminants (même nom, prénom, adresse, numéro de téléphone), ou encore des méthodes dites « probabilistes » reposant sur des algorithmes utilisant la première méthode mais aussi les fréquences et approximations compatibles. On parle dans ce cas de rapprochement flou souvent associé à la notion de scoring de confiance.
La complétude
Pour ce critère on va s’assurer de la présence de données significatives au niveau de l’objet en lui-même ou d’un attribut plus spécifique.
Si l’on reprend notre exemple client et particulièrement dans le cas d’un client entreprise, on va s’assurer que la fiche client comprend bien la complétude du Siret qui va constituer une clef d’identification forte et remplir aussi les exigences réglementaires comme l’obligation de cette information sur une facture.
L’exactitude
Ce critère peut se désarticuler en 2 sous critères : la précision et la validité.
Dans le cadre d’une adresse, le code postal doit être précis et correspondre à la réalité des données de référence postale. 44000 correspond bien au code postal de la ville de Nantes.
Par ailleurs, le critère de validité doit aussi pouvoir être contrôlé et en ce qui concerne les codes postaux les récentes fusion de communes ont fait évoluer les données de référence de La Poste rendant caduque certaines données dans le couple code postal/commune.
La conformité
La conformité est un sous-ensemble de l’exactitude et illustre le respect de la donnée à des contraintes réglementaires ou tout du moins à une convention interne. Les contrôles de conformité permettent les premiers contrôles de qualité afin d’éliminer les valeurs inexactes. Attention cependant la conformité à une convention qui serait interne ne garantit pas toujours de l’exactitude.
La cohérence
Ce critère représente l’absence d’informations en conflit. Dans le cas d’un référentiel produit, on constatera une incohérence lorsque le prix de vente effectif d’un produit sera supérieur à son prix maximum autorisé à la vente. On pourra aussi contrôler la cohérence entre différentes instances du système d’information et notamment lors d’une désynchronisation des données du SI. Dans le cas d’espèce, il suffira de mettre en œuvre des mécanismes de synchronisation par la propagation de la donnée maître vers les briques applicatives consommatrices de la donnée. Voir notre article sur la gouvernance de la donnée[LB1].
L’intégrité
L’intégrité représente les liens/les relations qu’une donnée ou un objet doit nécessairement avoir pour être exploitable. L’exemple type est celui d’une facture qui ne serait pas reliée à la commande correspondante. On parle parfois d’objet dit « orphelin ». Les outils de gestion des référentiels permettent aujourd’hui d’identifier ces problèmes d’intégrité en permettant au data steward de recréer les liaisons manquantes.
Les critères intrinsèques de qualité de la donnée peuvent aussi être complétés par des critères de service. Ces éléments plus subjectifs dans leur appréciation sont néanmoins capitaux pour la bonne exploitation de la donnée dans le SI.
La fraîcheur
Ce critère de qualité est le rapport entre les données et le temps. L’obsolescence traduit le fait qu’une donnée a pu être exacte à un temps t mais ne l’est plus à la suite d’un changement dans le monde réel. Dans le cadre d’un référentiel client, le déménagement participe à l’obsolescence des adresses chaque année statistiquement. Ces événements hors de la maîtrise directe des acteurs data mettent en évidence le besoin de mettre à jour les données suffisamment souvent avec une mise à disposition rapide de cette actualisation auprès des utilisateurs qui y sont particulièrement sensibles notamment pour répondre aux contraintes transactionnelles ou décisionnelles.
L’accessibilité
L’accessibilité concerne la facilité d’accès aux données. D’une part, il est nécessaire de savoir où se trouve réellement l’information et quel est le point de vérité de de la donnée au sein du SI. D’autre part, il faut adapter cette accessibilité en fonction de la volumétrie des bases et de l’usage qu’il est fait de la donnée par le calibrage d’un mode événement (à chaque mise à jour), d’un mode requête (à la demande de l’utilisateur) ou encore en mode batch pour les synchronisations en masse.
La pertinence
C’est le critère plébiscité par les équipes métier. Une donnée est de qualité que si elle est pertinente c’est-à-dire utile. Une donnée trop détaillée peut être inutile par les processus ou les briques applicatives qui la consomment. Afin d’être pertinente la donnée doit être adaptée et en adéquation avec son usage.
La compréhensibilité
La donnée doit en effet être compréhensible pour chaque utilisateur. Ce critère pré suppose un alignement dans la signification de l’attribut ou de l’objet. Afin d’atteindre ce niveau de compréhension partagé, il est préconisé que les univers, concepts et termes métier soient documentés par l’existence d’un glossaire métier, d’un dictionnaire de données, d’un inventaire des traitements et des usages de cette donnée.
Afin de faire progresser la qualité des données de nombreux outils existent et notamment ceux proposant l’élaboration de Data Catalogue.
Les outils de Data Quality
Pour couvrir une démarche de mise en qualité des données, un certain nombre de fonctionnalités doivent être présentes nativement dans les outils de Data Quality et notamment:
Le profilage
Il consiste à déterminer les critères et les objectifs de la qualité de données afin de dégager les domaines d’amélioration et le périmètre des actions.
Le monitoring
C’est l’analyse de la qualité par la mise en oeuvre du profilage
La standardisation
Il s’agit de disposer de conventions afin d’avoir une représentation adéquate des données pour l’ensemble des attributs.
Le nettoyage
C’est l’étape de la correction des données erronées. Ce nettoyage est la plupart du temps automatisé cependant une forte contribution des utilisateurs est conseillée a minima en validation et arbitrage de données conflictuelles.
Le Matching
Il fait référence à la recherche de records relatifs à une même entité afin de détecter les doublons et d’éviter les incohérences entre les bases de données.
L’enrichissement
Cette fonctionnalité fait appel à des sources externes ou l’application de règles ayant pour but la complétude des données. L’enrichissement via les appels API à des sources opendata (API Sirène pour récupération de Siret d’entreprises) en constitue un exemple type.
La surveillance
Le contrôle permet de suivre l’évolution des données dans le temps et de déterminer leur éventuelle détérioration. Cette étape identifie les tendances sur la qualité des données et alerte sur les violations de règles définies en réagissant immédiatement aux problèmes avant que la qualité ne se dégrade.
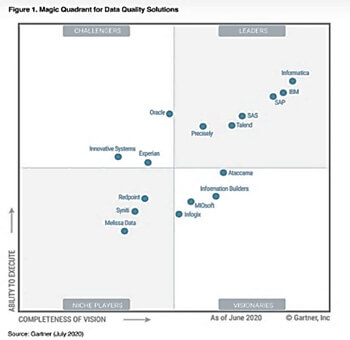
Les outils de traitement de la qualité des données sont multiples et varient selon le périmètre ou la spécificités des données prises en charge. Le Magic Quadrant de Gartner positionne annuellement les différents éditeurs et leurs solutions sur ce marché en fort développement en les classant en tant qu’acteurs de niche, challengers, visionnaires ou encore leaders.
La Data Quality en conclusion
L’amélioration de la qualité des données de l’entreprise passe par la mise en place d’une initiative continue et globale. L’aboutissement d’une démarche de qualité des données se trouve dans la mise en place d’une véritable gouvernance des données ou Data Governance. (Pour voir notre article sur la Data Governance, cliquez ici)
Une bonne gestion de la qualité des données est indispensable à la création de valeur pour l’entreprise. Il s’agit d’un problème métier, pas seulement informatique : plus elle sera incorporée aux habitudes, plus la démarche qualité progressera. La sensibilisation ainsi que la formation des utilisateurs et des opérationnels constituent des axes forts dans le succès et l’amélioration de la qualité de données.
Nos consultants experts de Next Decision sont à l'écoute de vos besoins et vous accompagnent dans vos projets de Data Quality ! Contactez-nous !