
Dans le cadre d’un projet, Next Decision a aidé un client à supprimer les doublons de trois systèmes d’information différents, retour sur la méthode.
Principe de la suppression des doublons via Talend
Le principe de notre réponse est de créer un programme : « la lessiveuse », qui va intégrer les 3 fichiers en parallèle et proposer des sorties.
La technologie retenue pour la lessiveuse est Talend.
La lessiveuse est un programme Talend, paramétrable et évolutif.
Son enjeu est de prendre les trois fichiers de les traiter et d’en ressortir un fichier prêt à l’import dans Salesforce et un listing des données à requalifier manuellement.

Schéma de suppression des doublons via Talend
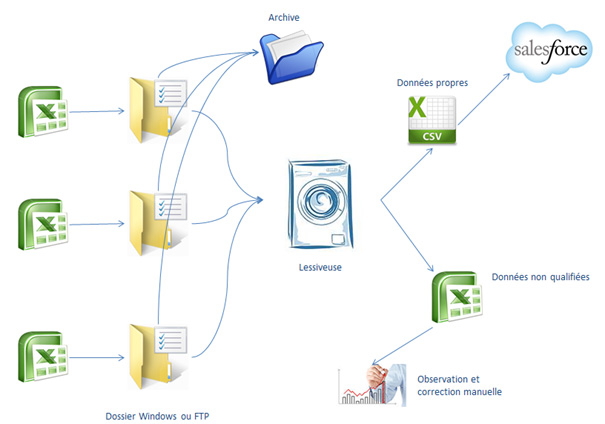
L’ensemble des flux bleus sont effectués via Talend.
Modalités de suppression des doublons via Talend
Aucune clef n’étant décrite dans les fichiers en entrées (cf document XXXX.docx), nous ne pouvons mettre en place une table de transcodification du type (Clef MDM, Clef SI1, Clef S2, Clef S3).
Aussi, l’ensemble des fichiers sont intégrés par Talend à chaque lessivage.
Fichiers
Les fichiers sont déposés par les applications sources dans un dossier windows ou FTP.
Une fois les trois fichiers présents, le flux Talend est exécuté. Ce dernier prend les fichiers et les met dans un dossier d’archive ensuite le lessivage commence.
La lessiveuse talend
La lessiveuse Talend part du principe que chaque fichier ne doit pas être dédoublonné sur lui-même. Si cette option est nécessaire, la lessiveuse pourra simplement passer un fichier sur lui-même.
Les clefs de réconciliation potentielles entre les trois systèmes semblent être :
- Le nom.
- L’adresse.
- Le code postal.
- La ville.
Il existe des clefs communes par paire de systèmes, à voir si elles pourraient être utiles.
Par expérience, nous savons que la réconciliation par nom est rarement performante. Les ratios traditionnels sont de 15 à 20% de réconciliation.
Comment réconcilier par nom via Talend ?
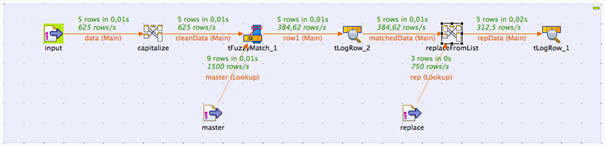
Le TFuzzyMatch est un composant Talend qui permet de réconcilier des chaines de caractères sur elles-mêmes via deux méthodes :
- La classification dites LEVENSHTEIN : mesure le nombre de lettres d’écarts entre deux mots (ex : TOTO vs TATA donne 2, TOTO vs TOTI donne 1).
- Le phonique ou métaphonique (par expérience, nous ne retenons pas cette méthode qui ne fonctionne peu pour des noms francophones).
Format ISO Lessiveuse
Pour mesurer le nombre de lettres d’écarts entre deux mots, il convient de se positionner sur un format de texte identique entre les différentes chaînes que nous souhaitons réconcilier. Nous nommerons ce format l’ISO-Lessiveuse.
Pour obtenir l’ISO lessiveuse nous vous préconisons de développer un unique job Talend qui :
- Supprime les caractères spéciaux suivants : {([-\_@)]}&.
- Elimine les blancs.
- Elimine les accents et ç.
- Met la chaîne de caractères en majuscule.
Ce job Talend est effectué de manière unique et appelé pour tous les entrants. Ainsi une modification est effectuée une unique fois pour être appliquée sur l’ensemble des entrants.
La lessiveuse
La lessiveuse est un job Talend qui effectue des réconciliations entre les noms et d’autres critères.
La réconciliation ne s’effectue pas uniquement sur l’idendicité exhaustive des noms mais sur deux règles paramétrables de l’extérieur du job Talend.
La première règle correspond à des seuils de ratio de lessivage (RL).
Le ratio de lessivage suit la formule mathématique suivante :
RL : nombre de lettre d’écarts / nombre de lettre de la plus petite chaîne.
Deux leviers de réconciliations sont paramétrables :
- Les seuils
- Seuil 1 : 5%
- Seuils 2 : 25%
La seconde règle correspond au nombre de lettres de la plus petite chaîne (par défaut 10)
Matrice de résultats :
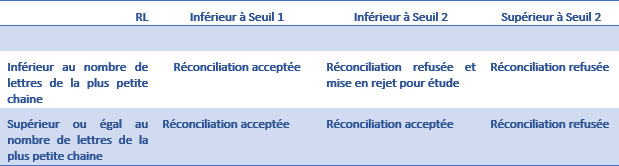
Cette matrice permettra d’avoir des leviers de réconciliation externe à l’application ne nécessitant pas de modification Talend pour faire des optimisations.
Par la suite les réconciliations rejetées seront vérifiées manuellement et une correction pourra être apportée dans le système d’information source.
Golden Record
A l’issue de la réconciliation/dédoublonnage, un Golden Record pourra être créé en prenant le plus grand nombre d’informations disponibles.
Des règles précisant quel système d’information source est prioritaire, au cas où les informations sont identiques dans deux fichiers, sont définies par le client.
Alertes
Cette méthode ne corrige pas la qualité de l’information dans les systèmes sources. Si une réconciliation ne s’opère pas en fonction des critères ci-dessus, il conviendra soit de modifier les règles Talend, soit de modifier les enregistrements dans les systèmes d’information sources.
Vous souhaitez être formé sur Talend ? Nous pouvons vous accompagner dans votre projet ! Découvrez notre formation Talend Studio.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Talend ? Rendez vous sur la page Contact
Besoin d'aide pour la suppression des doublons avec Talend à Nantes, Brest, Niort, Le Mans, La Roche-Sur-Yon, Angers, Paris, Laval, Rennes, Lyon, Grenoble, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Agen, Bayonne, Montpellier, Nice, Sophia Antipolis, Béziers...
Next Decision, votre expert Talend en Bretagne, Poitou-Charentes, Pays de la Loire, Centre- Val de Loire, Région Parisienne, Ile de France, Nouvelle-Aquitaine, Occitanie, Rhône, Ain, Isère, Loire, Languedoc-Roussillon et Provence-Alpes-Côte d'Azur.