

À l’heure où les POC autour de l’IA (et plus particulièrement du Machine Learning) se démocratisent, il est temps d’adopter une démarche pragmatique pour encadrer ces projets. Pour cela, quoi de mieux qu’adopter dès le début une démarche de type DevOps ? On entend parfois parler de MLOps (Machine Learning OPS). Il s’agit des méthodes projet de type DevOps adaptées pour du Machine Learning.
En effet, cette démarche apporte plusieurs avantages et ce, dès le début du projet :
- En DevOps, on souhaite un déploiement régulier des applications. Il faut donc mettre en production le plus régulièrement possible, tout en fiabilisant ce processus au fur et à mesure des itérations
- Les tests sont menés le plus tôt possible pour garantir des applications plus fiables
- Le processus de livraison peut être automatisé
- Enfin, on supervise le projet en production : on souhaite s’assurer que ce qui a été livré en production continue de répondre aux exigences exprimées
En IA, c’est exactement ce qu’il faut faire :
- Entraîner un ou plusieurs algorithmes et tester leurs performances
- Exporter un ou plusieurs modèles suite aux entraînements précédents
- Intégrer ces modèles en production
- Surveiller la performance du modèle en production et envisager un nouveau cycle d’entraînement;lorsque la performance des modèles en production tend à baisser
Pourtant, ce type de réalisation n’est pas toujours simple à faire et il est possible de se heurter aux principes même qui se cachent derrière les projets de Machine Learning.
Présentation du projet
Un projet de Machine Learning devrait donc suivre les étapes suivantes :

Parmi l’ensemble des étapes, nous allons faire un zoom sur une étape particulière : le Feature Engineering.
Pour l’exemple, nous nous appuyons sur un cas d’usage autour de la détection de maladie cardiaque.Voici un aperçu du jeu de données en entrée :
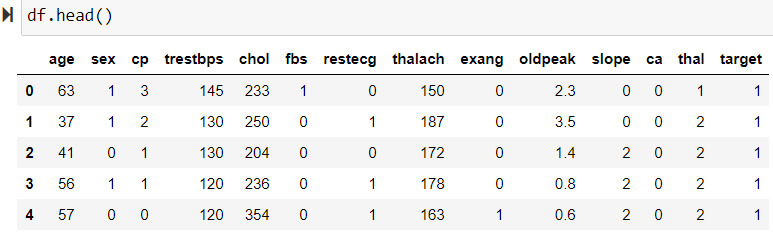
Dans ce jeu de données, nous constatons que certaines colonnes, malgré leur format numérique, sont clairement des catégories. Par exemple :
- SEX : prend les valeurs 1 ou 0
- CP (Type de douleur thoracique) : prend les valeurs de 0 à 3
- etc.
Pour gérer ce type de donnée, il est d’usage d’utiliser le principe de l’encodage one-hot. L’enjeu va être de transformer ces valeurs catégorielles en colonnes binaires (autant de colonnes qu’il y a de valeurs possibles).
En Python, il est relativement facile de réaliser un tel encodage :
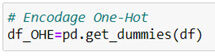
Ici, nous constatons que l’encodage s’est bien réalisé : il y a autant de colonnes CP et SEX qu’il y a de valeurs possibles dans les lignes.

Il est alors possible de continuer l’entraînement, de sélectionner un ou plusieurs algorithmes pour pouvoir prédire qu’un patient est atteint d’une maladie cardiaque.
Problématiques soulevées
Tout cela semble prometteur mais cela soulève plusieurs questions :
- Que se passe t-il si mon patient décrit une nouvelle douleur thoracique (CP) qui n’avait pas été répertoriée jusque là ?
- D’un point de vue plus technique, comment est-il possible de préparer de la donnée de production pour coller à cette donnée vu ci-avant ?
Commençons par la première problématique. Si un patient décrit un type de douleur thoracique (CP) qui n’avait pas été répertoriée jusque là, il y a fort à parier que, malheureusement, ce cas n’ait pas été pris en compte dans l’entraînement du modèle. Cela remet donc sérieusement en cause le projet et l’une des seules possibilités restantes va consister à :
- Collecter à nouveau de la donnée sur des patients avec cette nouvelle valeur de CP
- Entraîner de nouveaux algorithmes pour ces données collectées
- Mettre en production ce ou ces nouveaux modèles
La seconde problématique est davantage technique. Supposons que le jeu de données réelles soit le suivant :

Nous avons ici plusieurs patients qui ont différents critères. Le but va être de prédire pour chaque patient, la suspicion d'une maladie cardiaque (avec une probabilité qui va dépendre de la performance de l’algorithme utilisé). Le nombre de critères que nous avons en entrée est de 13 (toutes les colonnes sauf le numéro du patient, qui n’est pas pertinent dans le calcul de la maladie).
Cependant, suite à l’entraînement de notre algorithme sur un jeu de données ayant subi de l’encodage one-hot, le nombre de critères est bien plus important. En effet, notre modèle n’attend pas moins de 25 critères en entrée, et non 13.
Comment mettre en production ?
Dans le cas présent, pour chaque ligne du jeu de données, plusieurs opérations doivent être réalisées :
- Réaliser une transcodification du critère “SEX”. Dans le jeu de données réelles il y a des hommes et des femmes. Cependant, le modèle ne prend en entrée que des données numériques. Il faut donc penser à faire une transcodification :

- Faire en sorte qu’il y ait 25 critères en entrée du modèle et non pas 13. Pour cela, il est possible de s’appuyer sur une fonction Python “maison” qui s’occupe de faire le travail pour nous de manière automatisée :

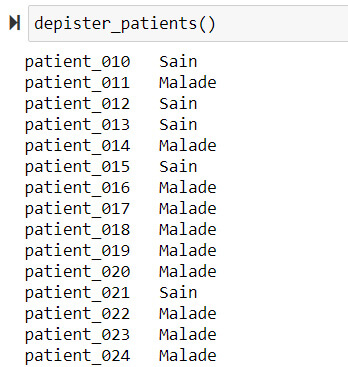
- Il ne reste donc plus qu’à prédire de manière automatisée, le risque que notre patient soit malade :
Comment mesurer la performance en continu ?
Maintenant que votre modèle est en production, il faut penser à mesurer sa performance de manière régulière pour voir, à l’aide de nouvelles données d’entraînement, s’il reste aussi fiable que par le passé.
Si la précision du modèle baisse avec le temps, c’est peut être le signe qu’il faut changer d’algorithme.
N’oublions pas qu’un projet de Machine Learning ne s’arrête jamais : il faut sans cesse vérifier la qualité du modèle et l’entraîner de nouveau si besoin.
Comment expliquer un résultat obtenu ?
Parfois, l’algorithme vous donne une prédiction mais vous ne savez pas dans quelle mesure vous pouvez lui accorder votre confiance. En Python, une librairie (ELI5) vous permet d’expliquer quelles sont les variables qui font pencher la balance d’un côté ou de l’autre.
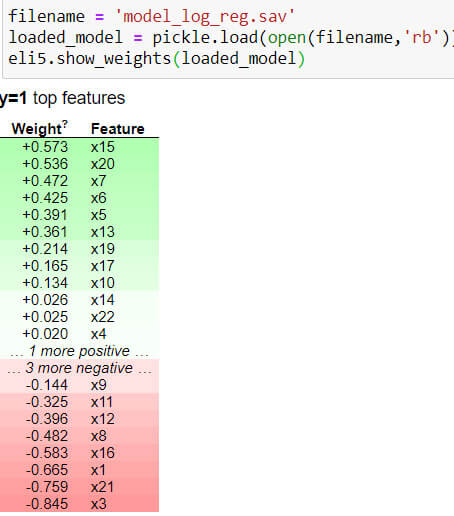
La librairie ELI5 offre également, pour chaque prédiction réalisée, la possibilité de comprendre précisément pourquoi un patient a été classifié comme sain ou malade.
… et avec un autre outil ?
Si le code vous fait peur et que vous souhaitez aller plus vite pour mettre en valeur vos données, il est toujours possible de faire appel à des outils tels qu’Alteryx et son Intelligence Suite. Cette option vous donne accès à un assistant très facile d’accès (pas de code, le tout en moins de 5 minutes), pour obtenir le résultat suivant :
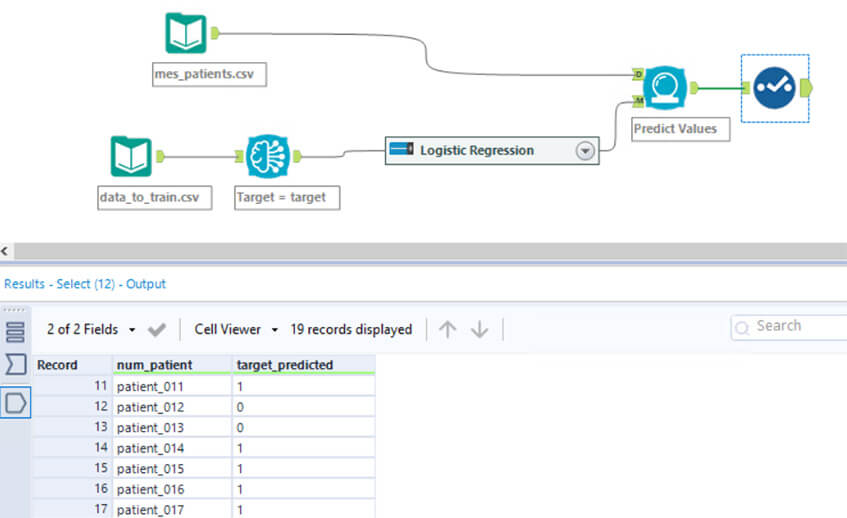
Le composant Logistic Regression a été créé automatiquement par l’outil à l’aide de l’assistant en mode clic boutons.
Si vous souhaitez une démonstration du produit, contactez-nous !
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une démonstration ? Rendez-vous sur la page Contact