

Nous allons dans cet article vous donner quelques bonnes pratiques et astuces pour optimiser l'utilisation d'Apache Spark.
Aujourd’hui, 1.7 megabyte de données est généré chaque seconde. Ainsi à l’ère de la transformation numérique, les entreprises collectent de plus en plus d’informations et de tout type : structurées ou non. Certains secteurs, dans le domaine financier par exemple, ont une demande accrue de traiter des flux de données en temps réel. La gestion des données se complexifie. Les infrastructures actuelles ne suffisent plus, des solutions Big Data s’imposent alors.
Apache Spark est un framework permettant la création d’applications distribuables sur un cluster. Il permet de mener des analyses d’informations Big Data, de mener des analyses d'informations massives et de traiter facilement de gros volumes de données. Vous pourrez interroger vos bases de données via des requêtes, gérer le streaming de données en continu, créer des graphes et concevoir des modèles de Machine Learning, le tout de manière distribuée, accélérant fortement vos calculs.
Bien qu’open source et s’appuyant sur le stockage de données sur Hadoop, Spark est accessible sur la majorité des plateformes Cloud (Microsoft Azure, Google Cloud Plateforme, AWS, Snowflake, …) comme service managé.
Spark est un des grands acteurs de l’architecture Big Data et à destination des Data Engineer, Data Scientist, développeur Big Data, notamment.
Dans cet article, tous les exemples seront présentés via PySpark. (Utilisation du framework avec le langage Python)
Bon à savoir sur Spark
Rapidité de traitement des données
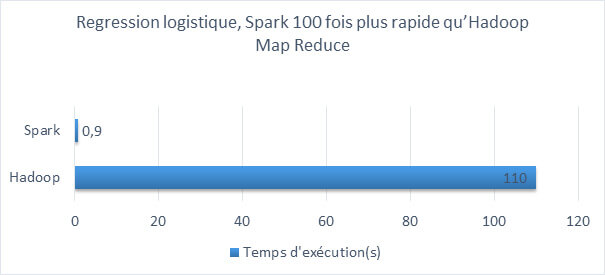
Spark est jusqu’à 100 fois plus rapide en mémoire et 10 fois plus rapide sur le disque :
- In-memory Processing : Les données sont stockées en mémoire, ce qui permet ainsi de réduire considérablement le nombre d’entrées et de sorties sur le disque. Le traitement en mémoire est donc fortement accéléré.
- Codé en Scala, ce langage orienté objet et de programmation fonctionnelle (par nature supporte le parallélisme).
- Lazy Evolution : Le calcul est exécuté au dernier moment.
- Data Locality : Les tâches sont optimisées en plaçant le code d’exécution au plus proche des données traitées, évitant ainsi les transferts de données.
Pérennité du système
Spark s’appuie sur des RDD (Resilient Distributed Datasets) qui sont tolérants aux pannes. En effet, de par l’enchainement de transformations et actions réalisées sur les RDD, un graphe acyclique orienté (DAG) est constitué. Grâce à ses nœuds parents, un nœud indisponible peut être reconstruit.
Une forte communauté Spark
Plus de 1000 contributeurs de plus de 250 organisations (dont Facebook, Netflix, Uber, IBM, Intel, LinkedIn, Google, Oracle, Databricks, etc) apportent fréquemment des améliorations au framework open source.
Spark s'intègre à une multitude d'APIs
Spark permet de traiter une grande variété de databases (fichiers plat, SGDBR, base NoSQL, flux de données, Open Data …), de gérer des flux et de traiter vos données en temps réel à l'aide d'outils comme Apache Kafka ou Apache Storm dans différents environnements comme Docker, Kubernetes et ce grâce à un seul framework. Nous pouvons aussi bien traiter des données structurées avec MySQL que non structurées avec MongoDB par exemple. Cette démarche simplifie grandement le travail des développeurs.
Spark est accessible par plusieurs langages
- Scala
- Java
- Python
- R
- SQL
Optimisation d'un code Spark
Privilégier les RDD ou les DataFrames / Datasets en fonction des données et de la facilité d'utilisation
En fonction de votre objectif, choisissez de travailler avec des RDD ou des DataFrames. Si votre problématique est liée à des données organisées, travaillez avec un DataFrame qui sera plus adéquat.
- RDD : pour des données non structurées, transformations avec un faible niveau d’abstraction
- DataFrame / Dataset : pour des données structurées, transformations avec un fort niveau d'abstraction
À noter : Avec Mlib et Spark SQL, nous travaillons nécessairement avec des DataFrames.
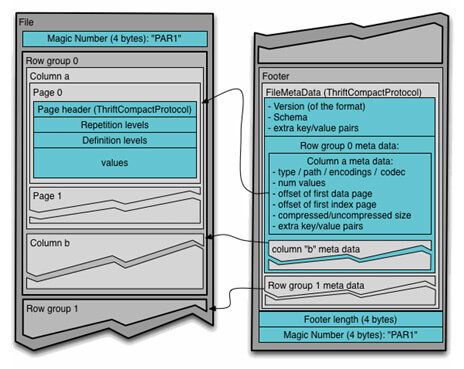
Choisir son format de fichiers idéal - Parquet
Spark supporte de nombreux formats comme CSV, JSON, XML, AVRO, … Cependant utiliser un fichier Parquet, (format de stockage d’informations colonnes) avec une compression snappy permet d’optimiser votre job Spark.
L’encodage au format binaire des informations et la compression par colonne permettent un traitement efficace d’un très grand volume de données, d’autant plus que Parquet détecte les données de même type et les données identiques. Il est très performant pour la lecture de données massives de fichiers à structure complexe et minimise les entrées/sorties.
Si vous voulez compresser votre fichier, quel que soit son type, choisissez un format où le fichier est divisible comme snappy (et non zip par exemple) afin de gagner en performance.
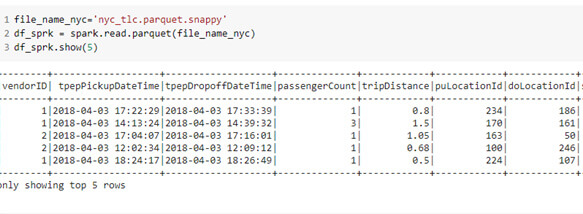
Éviter les brassages de données et filtrer les informations non pertinentes
Brasser les informations est une opération qui coûte cher et peut vous causer un dépassement de la mémoire. Afin de limiter les opérations d’entrées et de sorties sur le disque, de consommation de la mémoire vive, nous recommandons de filtrer dès le départ les colonnes/informations qui vous intéressent.
Voici quelques opérations qui demandent un shuffle des données et qui sont, dans la mesure du possible, à réaliser après le filtrage : groupByKey(), reduceByKey(), repartition(), join()
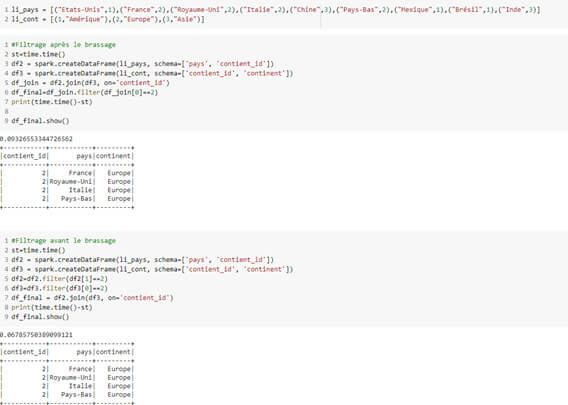
Être attentif au partitionnement
Le nombre de partitions d’un RDD par défaut est le nombre de cœurs que possède la machine ou sur les exécuteurs du cluster (selon le mode local ou cluster). Il est égal au nombre de tâches exécutées par les workers sur les données. Si elles sont trop nombreuses, certaines seront alors vides. Il ne faut donc pas chercher à en créer davantage pour obtenir une meilleure parallélisation. Apache Spark en recommande 3 par CPU disponible.

Interface web de Spark qui permet de monitorer les tâches :

Pour réduire le nombre de tâches, sans brassage des données (shuffling), vous pouvez utiliser coalesce() et répartition() qui délivrent les partitions de manière équilibrée en réorganisant l’information. On peut aussi partitionner par colonne avec partitionBy(), dans le but de partitionner de manière isolée et sans brasser les données, vous faisant ainsi gagner ainsi en performance.
Pensez bien au conseil précédent, n'oubliez pas le filtrage auparavant !
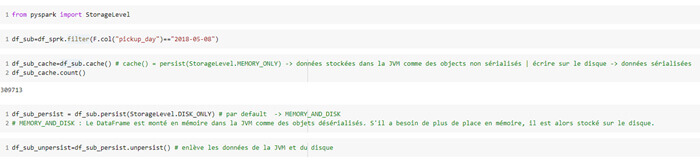
Réutiliser efficacement des opérations - Persistance
Avoir recours aux mêmes opérations régulièrement a un prix. Privilégiez, tout en étant vigilant aux gros volumes de données, la mise en cache de ces données en mémoire ou sur le disque avec la fonction persist().
Optimiser les performances avec des variables distribuées et partagées
Les jointures peuvent demander énormément de calculs et les répartir sur les exécuteurs est important. La fonction brodcast() vous permet de distribuer une copie de la variable sur tous les nœuds du cluster.
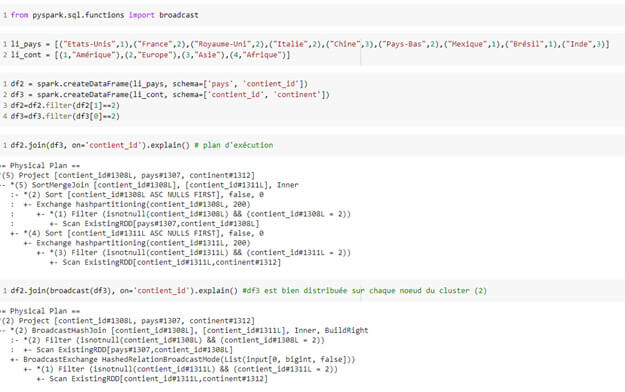
Les accumulateurs sont des variables partagées sur plusieurs nœuds du cluster et supportent uniquement les opérations associatives et commutatives.
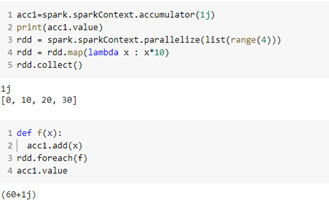
Ces deux types de variables vous permettront d'améliorer les performances de votre job Spark.
Quelques astuces Spark
- Minimisez les opérations d’entrées et de sorties
- En production, ne pas utiliser show()
- Evitez Pandas, bibliothèque de traitement de données non distribuée et privilégiez Koalas qui a implémenté les DataFrames Pandas sous Spark et couvre plus de 70% de ses fonctions
- Pour concevoir vos modèles de Machine Learning et utiliser des outils d'analyse prédictive, privilégiez MLlib comme bibliothèque, elle mettra à profit la distribution au service de vos prédictions.

Vous souhaitez bénéficier d'experts, d'une formation sur Spark ? Nos consultants sont là pour vous accompagner dans vos projets ! Contactez-nous !