

Nous analysons pour vous la suite Elasticsearch et vous livrons quelques astuces pour bien pratiquer l'outil !
L'architecture de développement Elasticsearch
L'architecture suivante a été appliquée sur la maquette Elasticsearch :
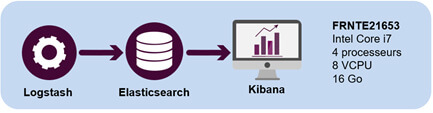
Ce serveur accueille donc 3 composants :
- Logstash : L'ETL fourni nativement par Elastic pour charger la base de données Elasticsearch
- Elasticsearch : La base de données
- Kibana : L'outil de reporting qui, naturellement, permet de visualiser les données présentes dans Elasticsearch
Cette architecture convient bien à la mise en place d’une maquette mais n’est pas recommandée en production. En effet, la puissance des bases NoSQL est décuplée dans un environnement distribué. Le paragraphe suivant donne un exemple d’architecture cible de production.
Architecture de la production Elasticsearch
Voici un exemple d'architecture de production Elasticsearch :
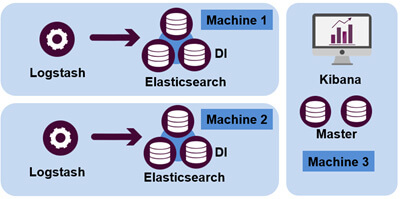
Dans cette architecture, on note plusieurs différences par rapport à l’architecture maquette :
- Cette architecture est distribuée : Il y a plusieurs noeuds Elasticsearch, ce qui permet de répartir à la fois les traitements et les données.
- Les nœuds Elasticsearch sont discriminés en fonction de leur usage : D = data, I = Ingestion, M = Master. Ici les deux nœuds ont des fonctions bien précises. Les deux Master de la machine 3 ne contiennent pas de données et n'ont pas de fonction d'ingestion non plus. De cette manière, ils se comportent comme des répartiteurs de charge. Les autres nœuds possèdent la donnée (D) et peuvent indexer du contenu (I) en provenance de Logstash.
Comment modéliser avec Elasticsearch ?
Elasticsearch et le modèle dénormalisé
Dans les bases NoSQL, il n’est pas possible de réaliser des jointures entre tables. De cette manière, il n’est donc pas possible de réaliser des jointures entre index dans Elasticsearch. Si les bases NoSQL ne supportent pas les jointures, c’est parce que ces dernières sont coûteuses en terme de temps.
Pour pallier à cette « contrainte », il convient donc de dénormaliser notre modèle. Cependant, il ne faut pas dénormaliser sans réflexion.
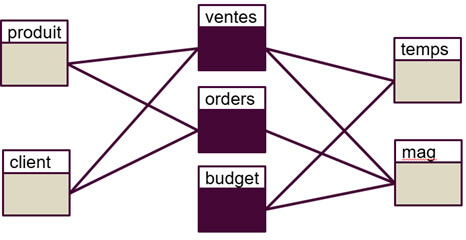
Voici un exemple de modélisation dimensionnelle classique, avec 3 tables de faits :
- Ventes
- Orders (commandes)
- Budget
Pour dénormaliser ce modèle, il n’est pas possible de tout intégrer dans un seul et même index, car cela n’a pas de sens d’un point de vue métier. En effet, mélanger les données de ventes et de budget n’a aucun sens (car n’étant pas liées aux mêmes dimensions).
Il conviendra donc ici de dénormaliser notre modèle de sorte à avoir un modèle par table de faits:
- Ventes avec ses dimensions associées : produit, client, temps et mag
- Orders avec ses dimensions associées : produit, client, temps et mag
- Budget avec ses dimensions associées : mag et temps
D'un point de vue Elasticsearch, cela se concrétisera par la création de 3 index séparés contenant chacun un contexte métier différent.
Elasticsearch et le modèle imbriqué
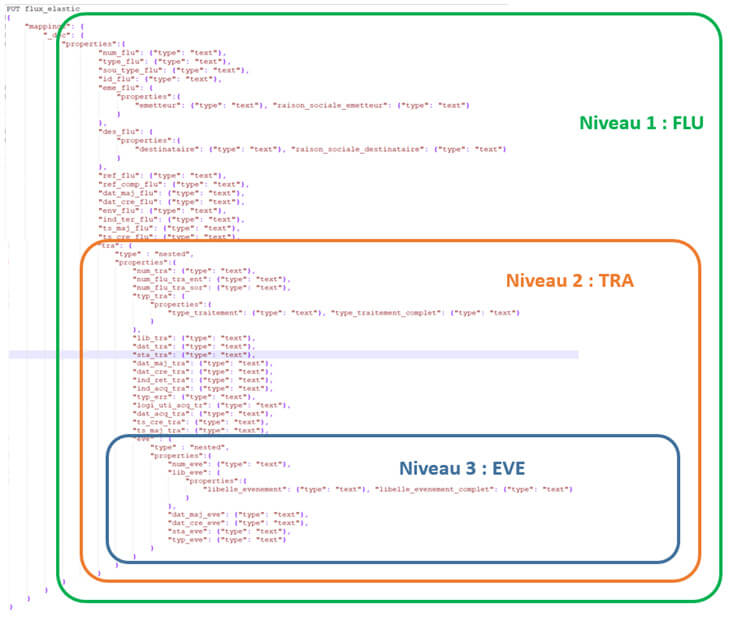
Parfois, il est tout de même utile de «simuler» le côté relationnel, notamment lorsque le modèle comporte des hiérarchies fortes. Dans l’exemple suivant, nous avons 3 niveaux hiérarchiques:
Niveau 1 : FLUX
Niveau 2 : TRAITEMENT
Niveau 3 : ÉVÉNEMENT
Dans ce cas, il est donc possible d’utiliser les notions de «nested» pour imbriquer des éléments entre eux, comme dans l’exemple ci-dessous :
L'ingestion de données dans Elasticsearch
Avec Logstash
Nativement, Elastic propose la solution Logstash en tant qu’ETL. Ce dernier permet de réaliser des transformations de données puissantes. Par contre, ce dernier est un programme Java. Cela le rend donc potentiellement plus lent que d’autres solutions.
Via des APIS
De base, tout Elasticsearch fonctionne via des APIs. Il est donc possible d’utiliser les APIs existantes pour intégrer du contenu dans la base de données:
- INDEX Api : Pour indexer du contenu, créer des index, etc.
- SEARCH Api : Pour réaliser des requêtes sur les données présentes dans Elasticsearch
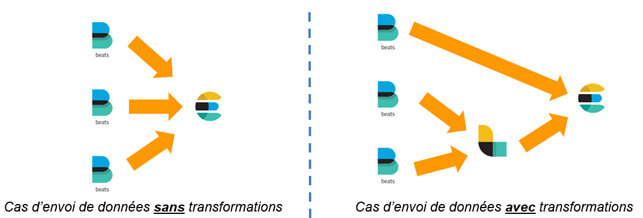
Via la suite de produits Beats
- Metricbeat : Agent de transfert de métriques issues de services (Apache, NGinx, etc.)
- Packetbeat : Agent de transfert de données réseaux
- Winlogbeat : Agent de transfert des logs d’événements Window
- Auditbeat : Agent de transfert de données d’audit Linux (auditd)
- Heartbeat : Agent de surveillance de disponibilité
Attention : Les agents Beats ne permettent pas de réaliser des transformations sur les données. Pour ce faire, il est possible de rediriger la sortie de Beats vers Logstash.
La mise à jour de données dans Elasticsearch
Ajout d'une donnée dans un document imbriqué
Il est possible d'utiliser l'API_update et le script pour ajouter un nouvel événement dans un traitement d'un flux :

Modification d'un champ dans un modèle imbriqué
Exemple de script pour mettre à jour dans un modèle Nested, toujours en employant l'API_update :

Comment requêter Elasticsearch ?
Requête via le langage naturel (DSL)
Nativement, Elasticsearch propose le langage DSL (Domain Specific Language) pour interroger les données présentes dans la base de données. Le format ressemble à l'écriture d'un document JSON.
Exemple de recherche :

Exemple de requête cherchant tous les enregistrements de l'index flux_elastic qui réunissent les conditions suivantes :
- Statut = ERROR
- Date_création comprise entre 01/01/2018 et 30/04/2018
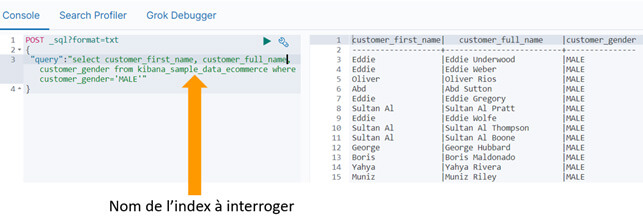
Requête en SQL
Bien qu'il ne soit pas possible de requêter Elasticsearch en SQL, le moteur propose une API pour traduire des requêtes SQL en DSL :
L'API propose également "translate" :
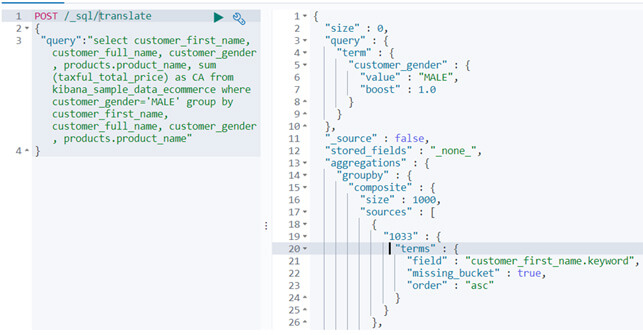
Attention néanmoins, le format SQL n'est pas intégralement pris en charge. Par exemple, il n'est pas possible de réaliser des sous-requêtes, ni des jointures. Enfin, le DSL généré n'est pas forcément le plus optimisé mais il permet tout de même d'obtenir une trame de requête.
Requête via des APIS / Langages tiers
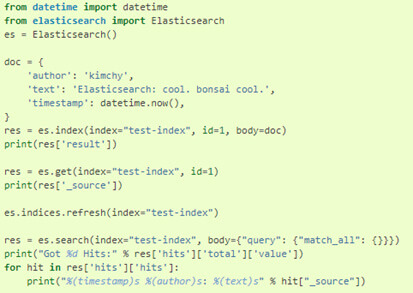
Enfin, il est possible d'utiliser l'API_search pour créer des recherches, à l'aide de n'importe quel autre langage, tel que Python, Perl, etc.
En Python, il y a le package Elasticsearch qui permet d'aller interroger / indexer du contenu dans la base de données :
La même chose est possible en Java :

Ou bien en Perl :
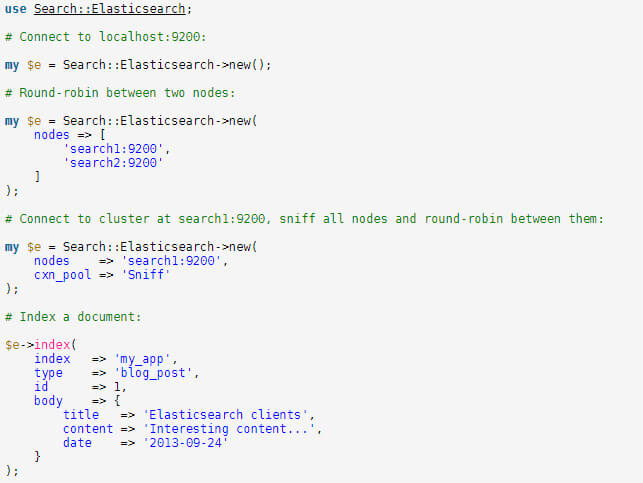
Elasticsearch pour d'autres usages ?
Analyse de logs
Historiquement, Elasticsearch est parfait pour de l'analyse de logs en temps réel. Voici un exemple d'architecture :
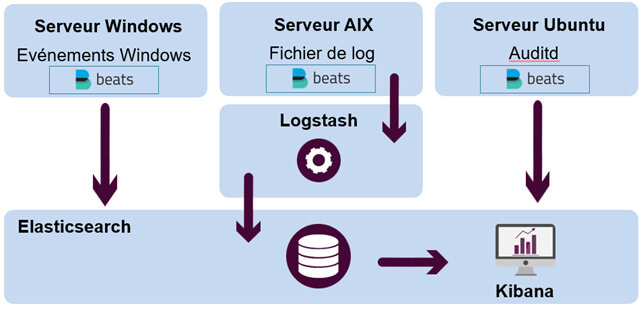
Dans le cas des événements Windows ou d'audits Linux, il n'y a pas de travail sur la donnée donc les logs peuvent directement passer de l'agent Beat vers Elasticsearch. Le fichier de log sur le serveur AIX a besoin, quant à lui, d'être parsé (découpé) et retravaillé. La donnée doit donc passer par Logstash avant d'aller dans Elasticsearch.
Vous souhaitez être formé sur Elasticsearch ? Next Decision dispense des formations ! Accédez à notre catalogue de formations Elasticsearch en suivant ce lien : Formation ELK
Vous recherchez des consultants experts en Elasticsearch ? Next Decision est là ! alors Contactez-nous !