

Préambule
Beaucoup de tutoriels parlant de la stack ELK (Elasticsearch Logstash Kibana) ou de Kafka existent sur Internet. Cela dit, ils sont souvent en anglais et, parfois, sur des versions anciennes des produits. Le but de ce tuto est donc de montrer, avec les versions plus récentes de chaque produit, comment réaliser simplement un pipeline complet de données depuis un site web vers Kibana.
Prérequis
Pour pouvoir réaliser ce tuto, il faut disposer :
- D’un environnement avec Docker (Pour notre part, nous avons monté une VM CentOS sur laquelle nous avons installé Docker et Docker-compose)
- Des images qui vont bien pour le projet :
docker pull bitnami/apache:latest
docker pull docker.elastic.co/beats/filebeat:7.6.2
docker pull bitnami/zookeeper:latest
docker pull bitnami/kafka:latest
docker pull docker.elastic.co/logstash/logstash:7.6.2
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.6.2
docker pull docker.elastic.co/kibana/kibana:7.6.2
- Nous nous servons aussi du conteneur Portainer pour faciliter la création des stack et la gestion des conteneurs (Ceci n’est bien entendu pas obligatoire.)
Présentation du cas d'usage et architecture du Data Pipeline (Avec ELK et Kafka)
L’enjeu de ce tutoriel est de présenter un cas d’usage complet de collecte de données issues d'un site web pour les envoyer au travers des différentes couches très classiques d'un environnement de type Big Data (Apache Kafka, Logstash, Elasticsearch,etc.)

Voici les différentes couches de notre pipeline :
- Le site web génère des fichiers de logs avec, notamment, les accès sur le site Internet
- Filebeat va collecter les données présentes dans ce fichier de logs et l’envoyer à Apache Kafka
- Apache Kafka stocke les messages reçus par Filebeat et les stocke dans une file d’attente (topic)
- Logstash est abonné à un topic Kafka et reçoit les messages au fil de l’eau. Il va également transformer la donnée reçue par Kafka (notamment parser la donnée)
- Logstash envoie la donnée dans un index Elasticsearch
- Kibana permet de créer des visualisations de données au-dessus d’Elasticsearch
À noter : Dans ce tutoriel, nous n'aborderons pas les notions suivantes :
- Sécurisation des différentes couches : Elasticsearch et kafka ne sont pas sécurisés dans ce tutoriel
- Sécurisation des échanges : pas de mise en place de SSL / TLS
- Distribution : pour l’exemple, notre cluster Kafka ou Elasticsearch ne contiennent qu’un seul noeud
Ce tutoriel a donc pour objectif de vous présenter de manière simple comment mettre en place un pipeline pour une démo ou pour un POC mais absolument pas pour de la production. N’oubliez pas de toujours sécuriser au maximum votre donnée (Par des mots de passe, par de la distribution de données pour créer de la résilience et par la mise en place d’échanges sécurisés type SSL / TLS).
Étape 1 : mettre en place le site Web
Avant de mettre en place le Data Pipeline, il convient d’avoir d’abord un site web qui génère de la log. Pour l’occasion, nous utiliserons l’image Docker bitnami/apache. Par défaut, les conteneurs basés sur cette image verront leurs logs affichés dans la sortie standard (/dev/stdout) mais ce n’est pas pratique pour la suite. Nous allons donc modifier donc le fichier httpd.conf pour augmenter le niveau de log (LogLevel info) et faire en sorte que ce soit un fichier en sortie : "logs/access_log.log".
Exemple des modifications apportées au fichier httpd.conf :
LogLevel info
<IfModule log_config_module>
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\"
\"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %b" common
<IfModule logio_module>
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\"
\"%{User-Agent}i\" %I %O" combinedio
</IfModule>
CustomLog "logs/access_log.log" common
</IfModule>
Maintenant que le fichier httpd.conf est prêt, nous le déposons sur la VM dans /root et utilisons la notion de volumes pour pouvoir le rendre visible dans le conteneur :
version: '2'
# Les services
services:
# Notre super site Internet!!
site_web:
image: 'bitnami/apache:latest'
container_name: 'site_web'
user: root
ports:
- '80:8080'
volumes:
# Pour customiser le fichier de configuration d'Apache :
- /root/httpd.conf:/opt/bitnami/apache2/conf/httpd.conf
# Pour partager les fichiers de logs d'Apache dans le volume
- data_logs:/opt/bitnami/apache2/logs
# Les volumes pour persister et partager la donnée entre les conteneurs
volumes:
data_logs:
driver: local
Le second volume (data_logs) nous sera utile plus tard : il va nous permettre de partager le contenu du répertoire /opt/bitnami/apache2/logs avec un autre conteneur (Filebeat en l'occurrence).
Une fois la stack lancée, il est possible de voir le conteneur en cours d’exécution :

En allant dans le conteneur, il est possible de faire un tail -f sur le fichier de logs afin de s’assurer que ce dernier se remplit correctement à chaque fois que nous tenterons d’aller sur le site web :
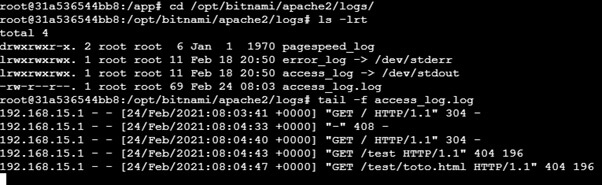
Tout semble OK : passons maintenant à Filebeat !
Étape 2 : Mise en place de Filebeat (Stack ELK)
Filebeat sera l’agent léger chargé d’aller collecter les données du fichier access_log.log précédemment configuré. Pour cela, il s’appuie sur un fichier filebeat.yml.
Fichier filebeat.yml à déposer sur la machine, dans /root :
filebeat.inputs:
- type: log
paths:
- "/usr/share/filebeat/data/access_log.log"
fields:
apache: true
fields_under_root: true
output.kafka:
hosts: ["kafka:9092"]
topic: 'web-logs'
codec.format:
string: '%{[@timestamp]} %{[message]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
Ici, la sortie est du kafka. Il suffit de lui renseigner l’adresse du broker, le nom du topic dans lequel on souhaite écrire et le format d’écriture des logs.
Astuce : Pour vérifier que filebeat visualise bien les données, ne pas hésiter à utiliser d’abord la sortie console, au lieu de Kafka :
output.console:
pretty: true
Cela permettra de voir, dans la sortie du conteneur Filebeat, les logs du serveur Web arriver.
Enfin, voici comment intégrer filebeat dans la stack docker compose :
# Filebeat : Pour aller collecter les données de logs du site Web ci-dessus
fb_collect_logs:
image: 'docker.elastic.co/beats/filebeat:7.6.2'
container_name: 'fb_collect_logs'
user: root
volumes:
- data_logs:/usr/share/filebeat/data
- /root/filebeat.yml:/usr/share/filebeat/filebeat.yml
# Pour lancer Filebeat :
command: ["-e"]
depends_on:
- site_web
networks:
- elk_network
Étape 3 : Mise en place de Zookeeper et de Kafka
Apache Kafka est un serveur de messagerie très utilisé dans des cas d’usage impliquant un besoin de faire du temps réel. Pour pouvoir l’utiliser, il est nécessaire d’avoir également Apache Zookeeper dont le rôle est de s’assurer que Kafka est en bonne santé.
Pas de configuration particulière à prévoir (volumes). Voici la stack sur les deux nouveaux conteneurs à créer :
# Apache Zookeeper : Maintenance de Apache Kafka
zookeeper:
image: 'bitnami/zookeeper:latest'
restart: always
hostname: zookeeper
ports:
- 2181:2181
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
networks:
- elk_network
depends_on:
- fb_collect_logs
# Apache Kafka : Collecte des données issues de Filebeat
kafka:
image: 'bitnami/kafka:latest'
hostname: kafka
ports:
- '9092:9092'
environment:
- KAFKA_BROKER_ID=1
- KAFKA_LISTENERS=PLAINTEXT://:9092
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
depends_on:
- zookeeper
networks:
- elk_network
Astuce : Ilest possible de visualiser les messages qui se trouvent dans un topic, afin de s’assurer que les briques communiquent bien entre elles :

Pour cela, utliser l’outil kafka-console-consumer.sh :
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic web-logs
Étape 4 : Mise en place de Logstash, d'Elasticsearch et de Kibana (Stack ELK)
Pour Logstash, il faut constituer un fichier de configuration qui va servir à l’outil pour collecter, transformer et écrire la donnée depuis Kafka vers Elasticsearch.
Fichier pipeline_web_logs.conf à mettre sur /root :
input {
kafka {
bootstrap_servers => "kafka:9092"
topics => ["web-logs"]
}
}
filter {
grok {
match => {"message" => '%{TIMESTAMP_ISO8601:date_filebeat} %{IP:client} - - \[%{HTTPDATE:date_log}\] \"%{WORD:methode} %{NOTSPACE:request_page} HTTP/%{NUMBER:http_version}" %{NUMBER:server_response}'}
}
date {
match => ["date_log", "dd/MMM/YYYY:HH:mm:ss Z"]
target => "date_log"
locale => "en"
}
mutate {
add_field => {
"Contexte" => "Demo_Next"
}
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
index => "web_logs"
}
}
Une fois le fichier de configuration prêt, il ne reste plus qu’à créer la stack ELK avec les trois outils (Elasticsearch, Logstash et Kibana)
# Logstash : Récupération des données de Apache Kafka pour envoi dans Elasticsearch
logstash:
container_name: logstash
image: docker.elastic.co/logstash/logstash:7.6.2
ports:
- "5044:5044"
volumes:
- /root/pipeline_web_logs.conf:/usr/share/logstash/pipeline/logstash.conf
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
networks:
- elk_network
depends_on:
- elasticsearch
- kafka
# Elasticsearch : Base de données NOSQL
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
container_name: elasticsearch
environment:
- cluster.name=cluster
- bootstrap.memory_lock=true
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elk_network
# Kibana : Pour visualiser les données qui sont dans Elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:7.6.2
container_name: kibana
environment:
SERVER_NAME: kibana
ELASTICSEARCH_HOSTS: '["http://elasticsearch:9200"]'
ports:
- 5601:5601
networks:
- elk_network
depends_on:
- elasticsearch
Étape 5 : Mettre le tout en musique! (Stack ELK + Kafka)
Maintenant que la stack complète est prête, il ne reste plus qu’à créer des visualisations dans Kibana et réaliser le test complet entre le moment où le site web est actualisé et le moment où la donnée apparaît dans Kibana :
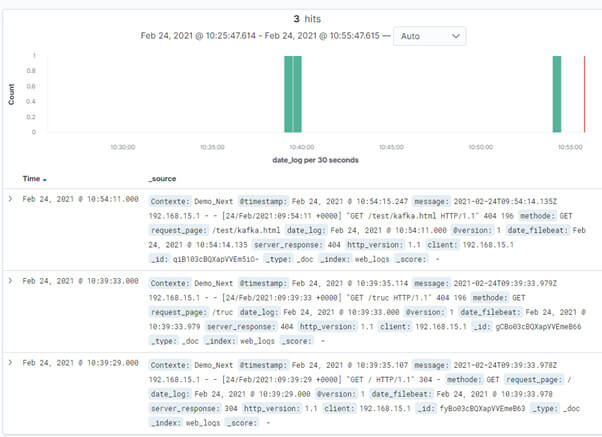
Votre index contient 3 dates :
- date_log : la date à laquelle l’événement s’est produit dans le site web
- date_filebeat : la date à laquelle filebeat a collecté ce message
- @timestamp : la date à laquelle la donnée a été indexée dans Elasticsearch
Ces 3 dates vous permettront alors de mesurer la latence qui existe entre le moment où la donnée est générée dans la source et le moment où elle apparaît dans Kibana.
Ainsi s'achève notre tuto. Retrouvez tous nos articles tutos, astuces et bonnes pratiques dans notre wiki !
Saviez-vous que nous pouvions vous former sur la stack ELK ? Consultez notre formation ELK - Elasticsearch Logstash Kibana.
À la recherche de consultants experts de la stack ELK ? Nous pouvons également vous former ! Contactez-nous !