

Comment alimenter son ODS Snowflake avec Semarchy xDI
L'idée est simple. Nous voulons ne récupérer que les données les plus à jour depuis notre schéma "RAW" (schéma de Landing / Staging) de Snowflake. Pour ce faire, nous devons définir des clefs d'unicité fonctionnelle (pas forcément techniques, même si cela pourrait être une bonne pratique) sur les tables ODS.
Ensuite, pour chaque clef, on va chercher les données venant du fichier le plus récent. (On se base sur le champ "METADATA$FILEDATE"). Une fois qu'on a toutes les données nécessaires, on peut faire une requête de merge et insérer les données brutes filtrées dans le schéma ODS.
On garde les mêmes noms de colonne et les mêmes nominaux de tables. Il faut donc recréer des tables dans le schéma ODS pour chaque table Snowflake dans le schéma RAW.
create or replace TABLE ODS.ODS_TEST (
METADATA$FILENAME VARCHAR(1000),
METADATA$FILEDATE DATE,
ID INTEGER,
Nom VARCHAR(500),
Code VARCHAR(10)
);
Une fois notre structure créée, on va vouloir paramétrer notre procédure stockée. Nous aurons besoin, pour ce faire :
- Du nom du schéma source
- Du schéma Snowflake de destination
- De la table source
- De la table de destination
- De la clef d'unicité. (Une clef d'unicité pouvant être composée.) Nous allons formater la clef d’unicité avec le nom exact de la colonne. Dans le cas d’une clef composée, nous allons séparer les noms de colonnes par une "," (les espaces sont autorisés, on pourra les traiter facilement).
CREATE OR REPLACE TABLE TECH.TECH_PARAM_ODS (
TABLE_NAME_SRC VARCHAR(100),
TABLE_NAME_TRG VARCHAR(100),
SCHEMA_SRC VARCHAR(100),
SCHEMA_TRG VARCHAR(100),
CLEF_UNICITE VARCHAR(200)
);
INSERT INTO TECH.TECH_PARAM_ODS VALUES ('RAW_TEST', 'ODS_TEST', 'RAW', 'ODS', 'ID');
Ensuite, il nous reste à développer la procédure stockée de fusion (merge). Nous allons aussi utiliser du javascript pour générer le texte de la requête. Pour le transfert des données, on préférera l'utilisation d'un "MERGE" de Snowflake par rapport à un "DELETE INSERT", car la fusion est plus facilement contrôlable. Aussi, en cas d'erreur sur l'insertion, les données seront toujours disponibles (pas supprimées) et nous ne supprimerons pas, non plus, les données qui ne sont pas dans le scope des fichiers importés (bornes de dates, par exemple).
CREATE OR REPLACE PROCEDURE TECH.MERGE_INTO_ODS("P_SCHEMA_TRG" VARCHAR(200), "P_TABLE_NAME_TRG" VARCHAR(200))
RETURNS STRING
LANGUAGE JAVASCRIPT
EXECUTE AS OWNER
AS $$
// PARTIE I - A - on récupère les données de paramétrage
var return_value = ""
if (P_TABLE_NAME_TRG != null) {
var sql_cmd_get_params = `
SELECT *
FROM TECH_PARAM_ODS
WHERE TABLE_NAME_TRG = \'`+P_TABLE_NAME_TRG+`\'
AND SCHEMA_TRG = \'`+P_SCHEMA_TRG+`\'
AND CHARGEMENT_ACTIF = 1`;
} else {
var sql_cmd_get_params = `
SELECT *
FROM TECH_PARAM_ODS
WHERE SCHEMA_TRG = \'`+P_SCHEMA_TRG+`\'
AND CHARGEMENT_ACTIF = 1`;
}
var query_get_params = snowflake.createStatement({
sqlText: sql_cmd_get_params
})
var result_get_params = query_get_params.execute();
while(result_get_params.next()) {
// PARTIE II - On formate les données de paramétrage pour préparer la requête INSERT
// déchargement des données de clefs d unicite
var techClefUnicite = result_get_params.CLEF_UNICITE ;
var tClefsUnicites = techClefUnicite.split(",").map(element => element.trim()) ;
var techSchemaSource = result_get_params.SCHEMA_SRC ;
var techSchemaCible = result_get_params.SCHEMA_TRG ;
var techTableSource = result_get_params.TABLE_NAME_SRC ;
var techTableCible = result_get_params.TABLE_NAME_TRG ;
// Formatage des textes de clauses select, join et group by
var unicityJoin = "" ;
tClefsUnicites.map(element => unicityJoin += `\n\t AND t.\"`+element+`\" = src.\"`+element+`\"` ) ;
var unicityNotNull = "";
tClefsUnicites.map(element => unicityNotNull += `\n\tAND tmp.\"` + element + `\" IS NOT NULL`) ;
var unicitySelect = "" ;
tClefsUnicites.map(element => unicitySelect += `\"` + element + `\", `) ;
unicitySelect = unicitySelect.substring(0, unicitySelect.length - 2)
var filtreAutreColonnes = "" ;
tClefsUnicites.map(element => filtreAutreColonnes += `\'` + element + `\', `) ;
filtreAutreColonnes = filtreAutreColonnes.substring(0, filtreAutreColonnes.length - 2)
// Formatage des noms de colonnes
var sql_cmd_get_columns = `
SELECT LISTAGG(\'"\' || column_name || \'"\', \',\') WITHIN GROUP (ORDER BY ORDINAL_POSITION) AS QUERY_FIELD
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = \'` + techSchemaCible + `\'
AND TABLE_NAME = \'` + techTableCible + `\'
AND column_name not in (` + filtreAutreColonnes + `)
`
var query_get_columns = snowflake.createStatement({
sqlText: sql_cmd_get_columns
})
var result_get_columns = query_get_columns.execute();
result_get_columns.next() ;
var sql_cmd_get_all_columns = `
SELECT LISTAGG(\'"\' || column_name || \'"\', \',\') WITHIN GROUP (ORDER BY ORDINAL_POSITION) AS QUERY_FIELD
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = \'` + techSchemaCible + `\'
AND TABLE_NAME = \'` + techTableCible + `\'
`
var query_get_all_columns = snowflake.createStatement({
sqlText: sql_cmd_get_all_columns
})
var result_get_all_columns = query_get_all_columns.execute();
result_get_all_columns.next() ;
var autreColonnes = "" ;
autreColonnes = result_get_columns.QUERY_FIELD
var touteColonnes = "" ;
touteColonnes = result_get_all_columns.QUERY_FIELD
autreColonnesPrefixes = ""
autreColonnes.split(",").map(element => autreColonnesPrefixes += "src." + element + ", ")
autreColonnesPrefixes = autreColonnesPrefixes.substring(0, autreColonnesPrefixes.length - 2)
autreColonnesUpdate = ""
autreColonnes.split(",").map(element => autreColonnesUpdate += "t." + element + " = src." + element + ", ")
autreColonnesUpdate = autreColonnesUpdate.substring(0, autreColonnesUpdate.length - 2)
unicitySelectPrefixes = ""
unicitySelect.split(",").map(element => unicitySelectPrefixes += "src." + element + ", ")
unicitySelectPrefixes = unicitySelectPrefixes.substring(0, unicitySelectPrefixes.length - 2)
var touteColonnesNonTech = ""
touteColonnes.split(",").map(element => touteColonnesNonTech += ["\"METADATA$FILENAME\"", "\"METADATA$FILEDATE\""].includes(element.trim().toUpperCase()) ? "" : element.trim() + ", " )
touteColonnesNonTech = touteColonnesNonTech.substring(0, touteColonnesNonTech.length - 2)
// PARTIE III - A - Ecriture de la requête d insertion
var sql_cmd_mergeODS = `
MERGE INTO ` + techSchemaCible + `.` + techTableCible + ` t
USING (
SELECT DISTINCT
METADATA$FILEDATE,
METADATA$FILENAME,
`+ touteColonnesNonTech +`
FROM (
SELECT
MAX(METADATA$FILEDATE) OVER (PARTITION BY `+unicitySelect+`) AS METADATA$FILEDATE,
MAX(METADATA$FILENAME) OVER (PARTITION BY `+unicitySelect+`) AS METADATA$FILENAME,
`+touteColonnesNonTech+`
, rank() over (partition by `+ unicitySelect +` order by METADATA$FILEDATE DESC ) as rnk
FROM ` + techSchemaSource + `.` + techTableSource + `
) tmp WHERE rnk = 1
`+unicityNotNull+`
) AS src
ON 1=1
` + unicityJoin + `
WHEN MATCHED THEN UPDATE SET
` + autreColonnesUpdate + `
WHEN NOT MATCHED THEN INSERT (
/* Colonnes clefs */
` + unicitySelect + `,
/* Colonnes non-clefs*/
` + autreColonnes + `
) VALUES (
/* Colonnes clefs */
` + unicitySelectPrefixes + `,
/* Colonnes non-clefs*/
` + autreColonnesPrefixes + `
)
`
// PARTIE III - B - mise en log + Exécution de la requête de fusion
var sql_add_log = "INSERT INTO tech_log_merge_ods (line) VALUES (\'" + sql_cmd_mergeODS.substring(0, 4000) +"\');"
var query_add_log = snowflake.createStatement({
sqlText: sql_add_log
}) ;
query_add_log.execute() ;
var query_merge_ods = snowflake.createStatement({
sqlText: sql_cmd_mergeODS
})
var result_merge_ods = query_merge_ods.execute() ;
return_value += `Merge succeeded for `+ techSchemaCible +`.` + techTableCible+`\n`
}
return return_value
$$;
/* Exemple d appel */
CALL MERGE_INTO_ODS('ODS_TRACA', 'ODS_BOVIN_EVENEMENT');
Explication textuelle de l'alimentation d'un ODS Snowflake avec Semarchy xDI
Encore une fois, cette requête est longue mais voici le résumé de ce qu'elle fait :
- Partie I - On récupère les données de la table de configuration. Cela va nous permettre de décharger les clefs d'unicité et les sources/destinations.
- Partie II - On se prépare à la conception de la requête
- A - On décharge les données qu'on a récupérées de la requête de la partie I
- B - On formate les clauses d'unicité et un filtre pour la partie II – C
- C - On récupère les autres colonnes non-clés pour remplir les clauses restantes de notre requête de fusion.
- Partie III
- A - On génère la requête de MERGE dans Snowflake
- B - On exécute cette requête et on envoie un feedback en retour
Il faudra ajouter (que ce soit dans cette procédure ou dans la précédente) un mécanisme de gestion d'erreur pour être le plus qualitatif possible sur notre code. Pour le moment nous n'avons pas besoin de cela.
Si vous avez lu toute la procédure, vous devriez avoir remarqué un appel à une table "tech_log_merge_ods". Cela permet de connaitre le texte exact de la requête qui a été exécutée. Cela pourra s’avérer être intéressant dans une phase de développement ou de débug.
Nous allons ici garder la logique de pouvoir forcer l'import de seulement certaines tables, mais nous allons gérer la pluralité d'appels avec Semarchy xDI.
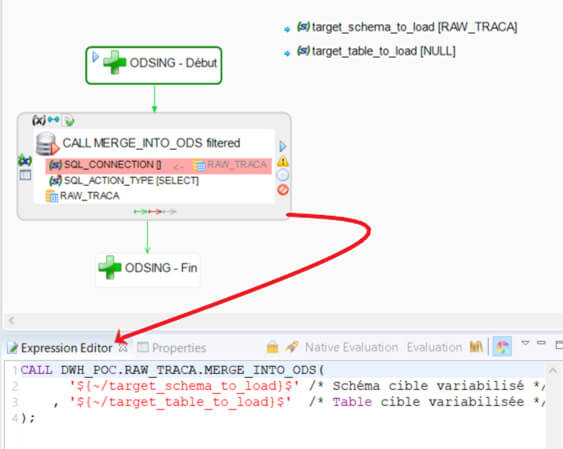
Ici, le principe est le même que pour la phase d'ingestion. La seule chose que ce process va faire est d'appeler la procédure stockée Snowflake de merge, en variabilisant le nom du schéma ainsi que de la table visée.
Nous allons aussi exporter ce process en tant que « delivery » pour pouvoir l’utiliser dans une brique « execute delivery » de Semarchy xDI. Nous verrons l’utilité de faire cela dans un prochain point. Il faut retenir que c’est bien Semarchy xDI qui gérera la logique d’appel.
Parallélisation des phases génériques Snowflake et Semarchy xDI
L’une des forces communes de Semarchy xDI et de Snowflake est de pouvoir paralléliser des traitements. Pour Semarchy xDI ce sera via des briques "execute delivery" qu’il faudra paramétrer pour être lancées en asynchrone.
Pour Snowflake, la parallélisation sera possible via les multi-cluster Warehouses. Ainsi, nous avons tout un tas de leviers nous permettant de gagner du temps sur nos chargements.
Nous allons nous concentrer sur la parallélisation des traitements avec Semarchy xDI. Il sera toujours possible d’augmenter notre performance en travaillant sur la configuration de notre Warehouse et de faire des auto-scale-up (de manière transparente, le Warehouse va utiliser un deuxième cluster en parallèle).
Pour paralléliser des traitements, nous allons donc utiliser les briques "execute delivery" reliées à un "Bind link" (représenté en gris) qui va permettre d'envoyer un à un les différents résultats d'une requête (SQL Operation).
On va donc utiliser cela pour la phase d'ingestion (RAW), qui va être parallélisée selon les jours à charger (1 thread = 1 jour). Pour la phase d'ODS on peut aussi utiliser une parallélisation qui se portera ici sur les tables (1 thread = 1 table).
Si une erreur intervient sur un des process en parallèle, il ne faut pas qu'il bloque les autres traitements de la phase, mais il ne faut pas passer à la phase suivante.
Le nombre de sessions parallèles va être pondéré par les limites de Snowflake, qui limite à 20 le nombre de requêtes simultanées sur un seul cluster (nous n’en utilisons qu’un). On va donc gérer cela dans les sous-process (d’ingestion et d’ODS) dans la propriété "Meta-Inf" avec la ligne suivante :
<nbMaxParallelSessions>20</nbMaxParallelSessions>
Les autres processus (Datamarts et Datawarehouse) ne sont pas forcément parallélisables du fait des différentes interactions qu'il peut y avoir entre les tables des mêmes schémas. On va donc les garder tels quels.
Enfin, si une erreur intervient dans l'ensemble du process ou des sous process, il faut avoir un mécanisme de "Fail-Safe" qui permettra de suspendre l'utilisation du Warehouse, et ainsi ne pas perdre de crédits inutilement. Ensuite, il faut générer une erreur pour prévenir l'automate ou l'utilisateur ayant lancé le job.
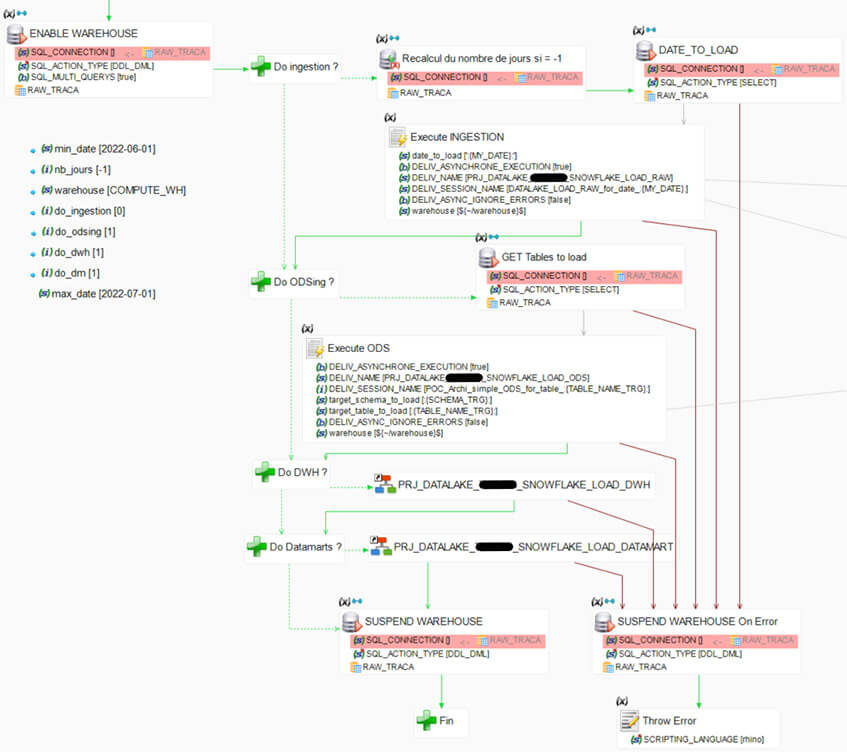
Dans ce process MAIN, nous pouvons voir :
- Les arguments d’entrées
- Les do_xxx : permet de passer outre certaines étapes, en le paramétrant directement via un outil externe
- Les dates : permet de définir la date minimale et la date maximale du chargement
- Nb_jours : permet de récupérer le nombre de jours à charger à partir de la date minimale. Si ce nombre de jour est à -1, on prend tous les jours de la date minimale à la date maximale
- Warehouse : Le Warehouse utilisé est variabilisé. Cela sera utile pour changer de Warehouse en cours de route par exemple
- ENABLE WAREHOUSE (SQL Operation) : permet de réactiver le Warehouse et de bien se positionner sur les bons objets
- Recalcul du nombre de jour si nb_jour = -1 (SQL to parameter) : requête SQL permettant de récupérer le nombre de jours
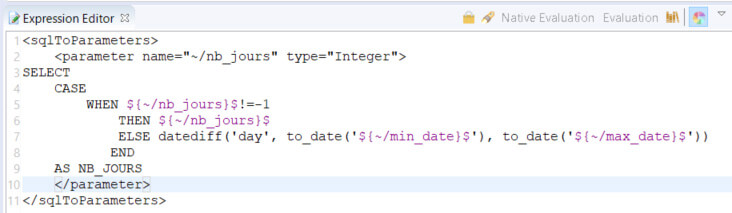
- DATE TO LOAD (SQL Operation) : Génère des dates (1 date par jour à charger). Pour chaque date générée, on appelle la brique suivante avec un Bind link (en gris)
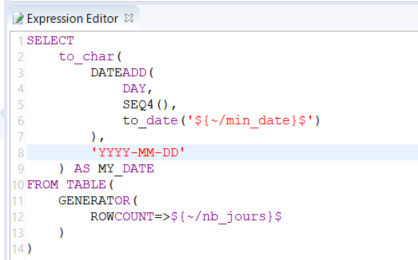
- Execute Ingestion (Execute delivery): Le process d’ingestion va être exécuté par cette brique. Les process sont exécutés de manière asynchrone avec 1 date par thread (20 max.)
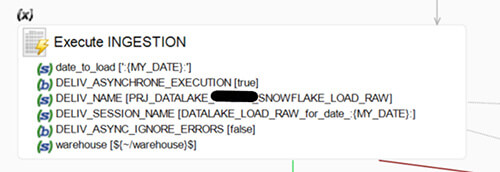
- GET Tables to load(SQL Operation) : Récupère les éléments à charger dans notre table de paramétrage «ods» pour pouvoir lancer des exécutions pour chaque entrée via un bind link.

- Execute ODS (Execute delivery) : Le process de fusion avec l’ODS va être exécuté par cette brique. Nous sommes aussi en asynchrone ici, et nous allons utiliser 1 thread par table à charger.
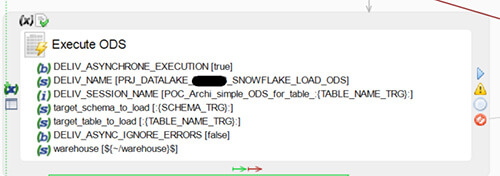
- Le process de chargement du datawarehouse
- Le process de chargement du ou des datamarts
- La gestion des erreurs :
- Suspend warehouse on error : cela nous fera gagner du temps et de l’argent sur l’utilisation des crédits par le Warehouse en le suspendant directement après son utilisation.

- Throw Error: génère une erreur de syntaxe. De ce fait, des automates pourront lancer une alerte en cas d’erreur de ce process.
- Suspend warehouse on error : cela nous fera gagner du temps et de l’argent sur l’utilisation des crédits par le Warehouse en le suspendant directement après son utilisation.
Cliquez sur ce lien pour la suite et fin de l'article.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ou Semarchy xDI ? Rendez vous sur la page Contact