

Maintenant que notre flux « main » est développé (voir cet article) et que nous avons des données dans notre ODS, nous pouvons commencer à alimenter des tables de notre Data Warehouse Snowflake.
Du fait des nombreuses transformations apportées à nos données d’ODS, nous allons avoir tendance à favoriser l'utilisation des mappings Semarchy xDI.
Cette phase étant spécifiquement liée à des règles métiers, nous n’allons pas y entrer en détail. Sachez cependant que les développements de cette étape sont similaires à tout autre développements ETL/ELT avec Semarchy xDI (Snowflake est très bien intégré dans la solution).
Les datamarts Snowflake et lien Semarchy XDI
Modélisation pour Snowflake
Pour les datamarts, il est préférable d’adopter une modélisation en étoile ou en flocon, avec au centre, notre table de faits portant tous nos évènements. Sur les côtés graviteront des tables de dimensions, des sortes de référentiels.
Implémentation dans Semarchy xDI de traitement Snowflake
L'implémentation xDI va être simple : à l’instar de la phase de Data Warehousing, nous allons privilégier les mappings pour gérer les transformations.
On doit faire un mapping pour chaque table décrite. Chaque mapping sera ensuite chaîné dans un process, lui-même appelé par notre process principal. On intervient en UPSERT (la suppression physique est possible à ce stade, car les données sont censées être stockées dans notre DWH). On chargera bien entendu les données des tables de dimension avant celles des tables de faits (contrainte de clef étrangère).
Pour chaque mapping on va utiliser une requête métadata particulière qui va nous permettre de gérer les valeurs non présentes : la valeur "N/A" (pour Null / Absente). Elle permet d'éviter les valeurs NULL et enlève un potentiel d'erreurs liées à la prise en compte des NULL dans les fonctions d'agrégation.
SELECT
0 as id
,'N/A' as VAL
On va ensuite faire une union entre les valeurs de l'ODS et les valeurs de la requête "N/A" pour ensuite insérer le tout dans les tables de dimension.
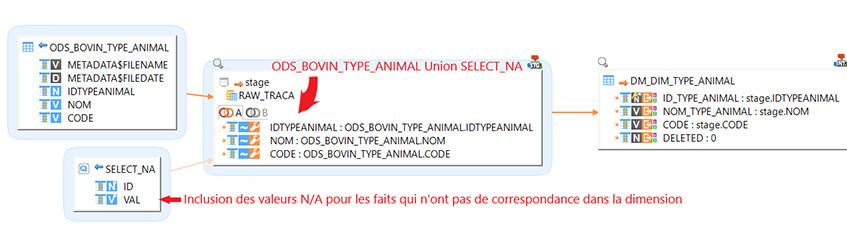
Pour la table de faits présente dans Snowflake, pour chaque champs nous allons utiliser la fonction COALESCE (champs, 0) pour pouvoir, en cas d'absence de valeur dans un fait, faire une liaison directe avec les "N/A" (cela vaut pour toutes les dimensions).
Étude des performances de la combinatoire Semarchy XDI / Snowflake
Salve 1 : Mono Warehouse
Salve Mono Warehouse avec une parallélisation à 20 sessions simultanées maximum pour la phase de raw.
Les traitements sont parallélisés sur la phase d'ODS aussi, à raison d'un thread par table de l'ODS à charger (20 max. simultanées, mais ce chiffre ne sera pas atteint dans notre POC).
Scénarios et phases de la salve
- Full load (intégralité de l'historique) : depuis le 1er janvier 2019 (scénario proche de l'initialisation). On fait le test sur un environnement local et un environnement distant sur serveur on-prem.
- Small load (seulement un mois de données) : depuis le 1erjuin 2022 (scénario proche du mécanisme incrémental). Idem, on fait les tests sur les deux environnements.
- Medium Warehouse (full et small load) : pour les deux chargements, on ne prend que l'environnement distant, plus proche d'une utilisation industrialisée classique.
Les tables ODS et RAW sont vidées entre chaque phase pour avoir une statistique significative de la performance, en excluant les soucis de volumétries (dans les merges, sélections et insertions).
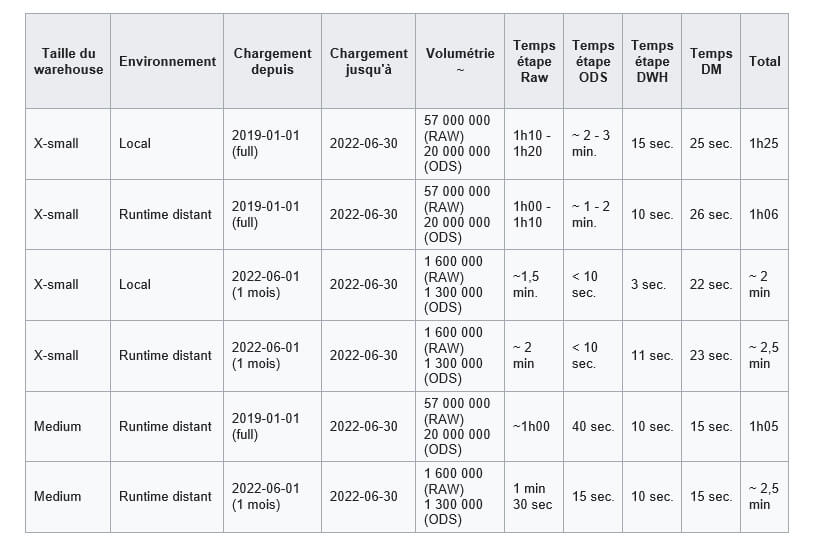
On peut noter que sur de gros chargements, on gagne du temps entre l'exécution locale et l'exécution sur runtime distant. Ce gain de temps est dû à l'interfaçage réseau, ainsi qu'aux ressources dont le runtime dispose qui sont plus importantes sur le serveur du runtime que sur les machines locales. Cependant, la majorité de l'interfaçage réseau va se faire entre notre Datalake Azure et Snowflake concenant le transfert des données pendant la phase RAW.
Pour ce qui est du niveau de service médium, quand on regarde les détails des exécutions de la phase RAW (à la maille de la journée chargée), le temps moyen de récupération est moins grand qu'avec le service "X-Small", mais avec une variance supérieure. Cependant, dans l'ensemble, cette montée de service n'est pas significativement meilleure et doit néanmoins être pondérée. Durant la phase RAW, nous chargeons les données de tous les fichiers sur un jour par exécution parallélisée. Cela implique beaucoup de récursion et d'aller-retour sur le Datalake et des dossiers de ce dernier, donc beaucoup d'interactions avec le réseau et plus qu'avec le moteur du Warehouse lui-même (ce qui explique une meilleure moyenne mais une moins bonne variance). L'intérêt d'un Warehouse en médium va porter principalement sur les parties suivantes (qui vont de Snowflake à Snowflake) mais ce n'est pas malheureusement, ce qui nous permettra de gagner le plus de temps.
Tarifs et coûts des scénarios
On peut définir une approximation du coût de notre chargement avec les données précédemment compilées.
Cette partie est confidentielle. Pour être accompagné par nos experts Snowflake en vue de se projeter sur le coût d’une future implémentation ou sur l’optimisation d’une implémentation Snowflake, contactez-nous.
Axes d'amélioration pour les temps de traitements Snowflake/Semarchy xdi
Un des axes d'amélioration possible pour notre architecture est la segmentation des fichiers selon les bonnes pratiques Snowflake : c'est, rappellons le, d'utiliser des fichiers d'environ 100-250 Mo, et compressés en GZIP. Cette segmentation peut se faire lors de l'export du fichier via des outils C#. L'optimisation devrait être visible pour chaque requête générée par notre procédure d'ingestion et pourra donc avoir un impact significatif sur les performances.
Un deuxième axe d'amélioration serait l'utilisation de plusieurs clusters dans les Warehouses. Or, même si le nombre maximum de requêtes simultanées sur un cluster est une contrainte de Snowflake, dans notre implémentation c'est Semarchy xDI qui gère ce point via des métadata de delivery. Attention, ces métadata NE SONT PAS dynamisables. Il faudra donc décider en avance du nombre de clusters à utiliser.
Enfin, un troisième axe d'amélioration possible pourrait être de manipuler plusieurs Warehouses en même temps. Avec un autre Warehouse s’exécutant en parallèle, on pourrait gagner en temps pour le même nombre de crédits.
Conclusion sur une architecture AZURE Datalake / Snowflake / Semarchy xdi
Nous sommes arrivés au bout du chemin !
Bien sûr, cet article n’est pas spécifique aux besoins de tout le monde et est volontairement lacunaire sur certains points qui appartiennent plus au côté fonctionnel et métier.
Nous avons tout de même pu voir un exemple d’implémentation technique d’une architecture data BI avec des outils modernes (Datalake, Snowflake).
Semarchy xDI intègre très bien l’outil Snowflake et se révèle très puissant lorsqu’il s’agit de traiter avec des modèles. L’intégration des Snowpipes dans la solution ne la rendra que meilleure !
Snowflake révèle une étonnante facilité de développement et une puissance de calcul qui surpasse bon nombre d’outils présents actuellement sur le marché. Et ce, alors que nous n’avons utilisé que les premiers niveaux de services sans implémenter tous les leviers d’optimisation qui sont à notre disposition.
BONUS : Aide à l’écriture du DDL pour les tables RAW et ODS
Ce script Powershell permet d'accélérer la partie création des tables et configuration des tables de paramètres. Il suffit de télécharger les fichiers du Datalake, de remplir les informations demandées par le script. Ce dernier va récupérer automatiquement les headers du CSV et va les transformer en noms de colonne.
La clef d'unicité doit aussi être définie à l'avance. Le masque des noms de fichiers est toujours le même (ajouter « .*\\ » avant le .csv). Aussi, les chemins dans le Datalake s'arrêtent au niveau de la date. Via un outil tel qu’Azure Storage Explorer, on pourra récupérer aisément ce chemin.
Enfin, il faudra quand même bien penser à préciser les types des colonnes, notamment de la table ODS. Les colonnes de la table RAW peuvent rester en VARCHAR(200) sachant que c'est avant tout du landing.
Le code généré est copié dans le presse-papier automatiquement et peut être ensuite récupéré, modifié et exécuté dans un environnement DDL Snowflake.
$confFile = Get-Content -Path "C:/Users/gmuraro/Desktop/sf_ddl_conf.json" | ConvertFrom-Json
$sql_ddl_command = "/*=== SCRIPT D'INCLUSION DANS LE DWH ===*/`n"
foreach ($conf in $confFile.confs) {
# Get Columns
$filePath = $conf.conf.filePathDisk
$firstLine = Get-Content -Path $filePath | Select-Object -First 1
$columns = $firstLine -split ';'
$prefixs = @("RAW", "ODS")
$nom_table= $conf.conf.tableName
$filePathStage = "DATALAKE_RAW/" + $conf.conf.filePathLake
$fileNameMask = $conf.conf.fileNameMask
$fileFormat = $conf.conf.fileFormat
$unicity = $conf.conf.unicty
$sql_ddl_command += "`n/*=== DDL DE $nom_table ===*/`n"
foreach($prefix in $prefixs){
$nom_table_concret = $prefix+"_"+$nom_table
$sql_ddl_command += "CREATE OR REPLACE TABLE $nom_table_concret (`n METADATA`$FILENAME varchar(1000), `n METADATA`$FILEDATE DATE,/* Modifier ici les colonnes, varchar(200) par défaut*/"
foreach ($column in $columns) {
$column_cleaned = $column
$column_cleaned = $column_cleaned -replace ("[^a-zA-Z\d\s:]", '')
$column_cleaned = $column_cleaned -replace (' ', '_')
$tabs = " "*$((27 - [int]($column_cleaned.length)) +1)
$column_cleaned = $column_cleaned.toUpper()
$sql_ddl_command += "`n $column_cleaned $tabs VARCHAR(200),"
}
$sql_ddl_command = $sql_ddl_command.substring(0,$sql_ddl_command.length - 1)
$sql_ddl_command += "`n);`n"
}
$sql_ddl_command +=
"
MERGE INTO TECH_PARAM_INGESTION t
USING (
/* Modifier la source du merge au besoin */
SELECT
'RAW_$nom_table' AS TABLE_NAME
,'RAW_TRACA' AS SCHEMA
,'$filePathStage' AS FILEPATH_STAGE
,'$fileNameMask' AS FILENAME_MASK
,'$fileFormat' AS FILE_FORMAT
,60 AS NB_DAYS_INGEST
,1 AS CHARGEMENT_ACTIF
) AS src
ON src.TABLE_NAME = t.TABLE_NAME
WHEN MATCHED THEN UPDATE SET
t.SCHEMA = src.SCHEMA
,t.FILEPATH_STAGE = src.FILEPATH_STAGE
,t.FILENAME_MASK = src.FILENAME_MASK
,t.FILE_FORMAT = src.FILE_FORMAT
,t.NB_DAYS_INGEST = src.NB_DAYS_INGEST
,t.CHARGEMENT_ACTIF = src.CHARGEMENT_ACTIF
WHEN NOT MATCHED THEN INSERT (
TABLE_NAME
,SCHEMA
,FILEPATH_STAGE
,FILENAME_MASK
,FILE_FORMAT
,NB_DAYS_INGEST
,CHARGEMENT_ACTIF
) VALUES (
src.TABLE_NAME
,src.SCHEMA
,src.FILEPATH_STAGE
,src.FILENAME_MASK
,src.FILE_FORMAT
,src.NB_DAYS_INGEST
,src.CHARGEMENT_ACTIF
) ;
"
$sql_ddl_command += "
MERGE INTO TECH_PARAM_ODS t
USING (
/* Modifier la source du merge au besoin */
SELECT
'RAW_$nom_table' AS TABLE_NAME_SRC
, 'ODS_$nom_table' AS TABLE_NAME_TRG
, 'RAW_TRACA' AS SCHEMA_SRC
, 'RAW_TRACA' AS SCHEMA_TRG
, '$unicity' AS CLEF_UNICITE
, 1 AS CHARGEMENT_ACTIF
) AS src
ON src.TABLE_NAME_TRG = t.TABLE_NAME_TRG
WHEN MATCHED THEN UPDATE SET
t.TABLE_NAME_SRC = src.TABLE_NAME_SRC
,t.TABLE_NAME_TRG = src.TABLE_NAME_TRG
,t.SCHEMA_SRC = src.SCHEMA_SRC
,t.SCHEMA_TRG = src.SCHEMA_TRG
,t.CLEF_UNICITE = src.CLEF_UNICITE
,t.CHARGEMENT_ACTIF = src.CHARGEMENT_ACTIF
WHEN NOT MATCHED THEN INSERT (
TABLE_NAME_SRC,
TABLE_NAME_TRG,
SCHEMA_SRC,
SCHEMA_TRG,
CLEF_UNICITE,
CHARGEMENT_ACTIF
) VALUES (
src.TABLE_NAME_SRC,
src.TABLE_NAME_TRG,
src.SCHEMA_SRC,
src.SCHEMA_TRG,
src.CLEF_UNICITE,
src.CHARGEMENT_ACTIF
) ;
"
}
Write-Output $sql_ddl_command
Set-Clipboard $sql_ddl_command
Pour faciliter l’utilisation de ce script, voici un exemple de JSON qui peut être créé en parallèle (sf_ddl_conf.json) :
{
"confs" : [
{
"conf" : {
"tableName" : "VOLAILLE_ENTREE_LOT",
"filePathDisk" : "C:\\Users\\gmuraro\\Downloads\\un_fichier_de_données_20220130.csv",
"filePathLake" : "LE/PATH/DANS/LE/DATALAKE/",
"fileNameMask" : " un_fichier_de_données_.*\\\\.csv",
"fileFormat" : "FF_TEST_CSV",
"unicty" : "ID"
}
}
]
}
Pour ajouter une configuration, il faudra ajouter un élément dans « confs » avec la même structure.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ou Semarchy xDI ? Rendez vous sur la page Contact