


Data Build Tool, aka dbt, est un outil de data integration et de transformation des données open source, essentiel dans votre chaîne décisionnelle pour exploiter, structurer et analyser les données issues de vos sources de données hétérogènes. DBT permet de collecter, transformer les données, préparer les données et les rendre prêtes pour vos solutions analytiques, dashboards et outils décisionnels.
dbt, un outil d'intégration moderne dans l'architecture Big Data
dbt est un framework de data management et de transformation des données utilisant du SQL standard dans votre entrepôt de données (data warehouse), remplaçant les vieux scripts ETL / ELT par une approche plus agile, interactive et orientée analyses sophistiquées pour la vidéo, l’IoT, le web services et les systèmes liés à la supply chain ou aux données industrielles.
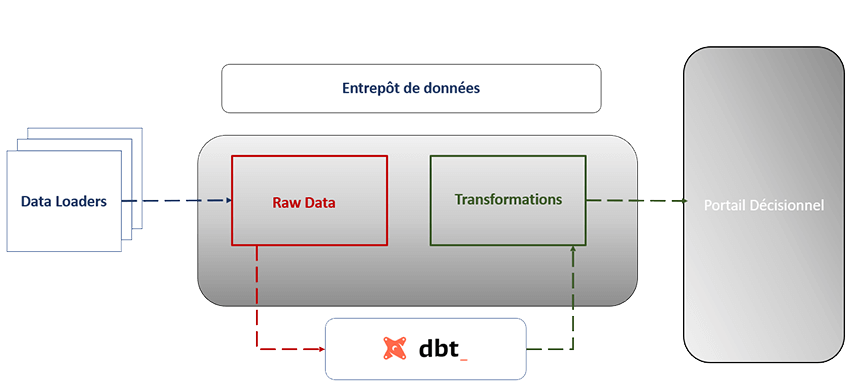
Il existe deux manières de travailler avec DBT pour optimiser votre Système d'Information.
Versions et interfaces de dbt :
- DBT Cloud : En utilisant l’environnement de développement sur le WEB (SaaS, version payante avec license), idéal pour l'automation des jobs, le monitoring, les services data gérés et le travail collaboratif.
- DBT Core : Interface en ligne de commande (CLI) agissant comme un backend puissant, DBT CLI peut être facilement installé sur votre poste de travail (Windows, Linux ou via Docker) ou un cluster. Il faudra préalablement installer Git for Windows ainsi que Python 3.5 au minimum (gestion via pip ou package), car le répertoire est dans GitHub. Cette version est gratuite et permet une gestion des données flexible et robuste.
2 prérequis pour utiliser DBT et manipuler les données de l'entreprise :
- Maîtriser le langage SQL (le tsandard pour interroger les bases de données relationnelles et analytiques
- Maîtriser les commandes GIT (pour le versioning des scripts et le travail en mode Agile).
Les principaux composants et structures de Data Build Tool
Dans DBT, il existe plusieurs répertoires dans un projet :
- Le dossier models contient les scripts SQL afin d’exécuter le modèle de données. Les modèles sont des requêtes SQL générant des données structurées ou intégrées selon le type de matérialisation (vue, table, table temporaire, incrémentielle) dans le Cloud Computing ou le serveur. C'est le cœur du traitement des données.
- Les fichiers.yml sont des fichiers de configurations. Ces derniers paramètrent la configuration des schémas pour gérer la bonne connection aux données. Il y a 3 fichiers YAML à connaître :
- dbt_project.yml : chaque projet DBT a un fichier dbt_project.yml associé. Ce fichier permet à DBT de reconnaître si un répertoire est un projet DBT et de définir le contexte du pipeline.
- profil.yml : Pour utiliser DBT CLI, il faut définir le profil de l’utilisateur dans un fichier yml en renseignant, selon le type de la base de données (Oracle, PostgreSQL, BigQuery, etc.), l’environnement de développement, la base cible, le schéma utilisé, la méthode d’authentification... On peut définir plusieurs profils pour séparer les environnements (Dev, Test, Prod).
- schema.yml : Ce fichier comprend des tests de qualité des données qui déterminent si les colonnes spécifiées (ex: clés primaires, attributs) ont des valeurs uniques, n’ont pas de valeurs Null, ou respectent des règles métier. Cela garantit des données exploitables pour le reporting.
- Le dossier seeds contient les fichiers .csv (souvent des données de référence ou sample) que DBT peut charger dans la base de données via un import simple et contrôler leur version.
- Le dossier snapshot permet de mettre en place des dimensions à variation lente de types 2 (SCD type 2) pour historiser les changements dans les tables de faits ou les dimensions.
- Le répertoire macros contient des morceaux de codes (proche du Jinja) ou des fonctions dans des fichiers .SQL permettant de réutiliser les scripts du modèle et éviter la répétition de longs bouts de code (principe DRY).
- Le répertoire tests permet d’exécuter des tests sur vos modèles (vérification des clés étrangères, unicité) et vous signale après l’exécution si le(s) test(s) est / sont OK, assurant un monitoring efficace de la qualité des données.
Type de matérialisation de modèles dans DBT
La matérialisation est une variable contrôlant la création du modèle et l'optimisation du stockage. Par défaut, le modèle sera une vue mais il en existe 4 types pour gérer les volumes de données :
- View (Vue logicielle) : le modèle est construit sous forme de vue dans la base de données (léger, pas de stockage physique, idéal pour l'ad hoc). C'est une vue logique (pas de duplication, données en temps réel possibles).
- Table : le modèle est construit sous forme de table physique (meilleure performance pour les outils de reporting comme Power BI ou Tableau Software).
- Ephemeral : table temporaire (utilisée comme sous-requête dans d'autres modèles).
- Incremental : permet d’insérer ou de mettre à jour des lignes, idéal pour les gros volumes de données et le Big Data, évitant de recharger tout l'historique.
Connexion aux bases de données
DBT prend en charge nativement les connexions aux data cloud platforms et entrepôts de données modernes suivants :
- Big Query (Google Cloud)
- Snowflake
- Amazon RedShift (AWS)
- Postgre (PostgreSQL)
D’autre part, DBT est un outil Open Source. La communauté a mis à disposition des connecteurs et plugins (via pip) pour pouvoir se connecter à une multitude de sources de données et SGBD, qu'elles soient relationnelles ou non : Oracle, SQL Server (Microsoft SQL), MySQL, Spark (écosystème Hadoop), Databricks, Azure Synapse, etc. Cela permet d'unifier des sources hétérogènes et de faciliter la migration depuis des systèmes legacy ou On-premise.
Avantages de Data Build Tool
- DBT CLI est un ELT gratuit pouvant se connecter à une multitude de bases de données et donc bénéficier de la puissance de calcul des Data Warehouses et du Cloud Computing.
- Flexibilité des modèles SQL pour créer des Data Marts, des cubes de données ou préparer la donnée pour le Data Mining.
- Le référentiel étant sur GitHub, le versionning, le travail en équipe (DevOps) et l'échange de projet sont simplifiés.
- Changement d’environnement simple (dev, prod, virtual) via les profils.
- Bonne gestion de la documentation (génération automatique d'un site statique décrivant le lineage, les dépendances et le dictionnaire de données).
Mode de fonctionnement de DBT
Comme vu précédemment, il y a deux versions de DBT. Ci-dessous les étapes de création d’un projet DBT-Core qui est la version gratuite sur Windows (similaire sous Linux ou Mac) :
-
Créer le référentiel du projet sur GitHub (ou GitLab/Bitbucket).
-
Cloner le dossier du projet en local.
-
Ouvrir le terminal et créer un environnement virtuel Python (pour isoler les packages).
-
Activer l’environnement.
-
Installer dbt-core et l'adaptateur requis (ex: pip install dbt-postgres ou dbt-snowflake).
-
Initier votre projet avec la commande dbt init
-
Configurer votre profil (profiles.yml) afin de vous connecter à la base de données cible.
-
Développer vos transformations avec des fichiers .sql (nettoyage, jointure, calcul de KPI).
-
Exécuter vos transformations avec la commande dbt run (création des tables/vues).
-
Commit puis Push votre répertoire pour sauvegarder le code.
Il est conseillé de développer les projets DBT-Core sur l’éditeur de code Visual Studio Code du fait de ses fonctionnalités d’assistance aux développements, de débogage et de son interface intuitive. De plus, cet éditeur de code gratuit et Open Source intègre GIT et un terminal.
Pourquoi utiliser Data Build Tool ?
DBT est devenu un standard :
-
Préparation des données et intégration des données en mode ELT.
-
Facilite l’exploitation des données dans vos pipelines, exécute des opérations et fournit un data hub pour vos équipes.
-
Agilité, modularité, et support des standards (SQL, YAML).
-
Permet de structurer une architecture de référence, de valoriser les données pour des analyses décisionnelles et de développer des analyses prédictives ou sophistiquées.
-
S’intègre à des outils comme Google Analytics, WordPress, Magento, CMS ou JQuery via APIs ou services web.
Dans quels cas utiliser Data Build Tool ?
DBT est devenu un standard pour les équipes Data (Ingénieurs, Analystes, Consultants BI) pour :
- Gestion des transformations dans les bases de données : Passer de données brutes (raw data) à des données intégrées et fiables pour la prise de décision.
- Tests de la qualité de données : S'assurer que les données ne sont pas dupliquées et respectent les règles (clé, format) avant d'alimenter les outils décisionnels.
- Analyse de données et Web Intelligence : Préparer des tables propres pour l'alimentation de tableaux de bord (Dashboards) sous Power BI, Qlik, Tableau ou Metabase.
- Data Science et IA : Fournir des datasets propres aux Data Scientists pour alimenter des algorithmes de Machine Learning, de prédictive ou d'analytique avancée.
- Centraliser les données : Créer une source unique de vérité (Single Source of Truth) pour les décideurs, la DSI et les métiers (Marketing, Finance, Retail).
FAQ Data Build Tool
Quelle est la différence entre DBT et un outil ETL classique comme Talend ou SSIS ?
Contrairement aux outils ETL (Extract-Transform-Load) traditionnels comme Talend ou SSIS qui transforment les données sur un serveur intermédiaire, DBT fonctionne en mode ELT. Il charge les données brutes (Extraction) puis réalise les transformations directement au sein de l'entrepôt de données (Data Warehouse) en utilisant la puissance du Cloud et du SQL. Cela permet de traiter de plus gros volumes de données plus rapidement.
Faut-il être expert en Python ou Java pour utiliser DBT ?
Non. Bien que DBT soit développé en Python, le langage principal utilisé par le Data Analyst ou le développeur pour créer des modèles est le SQL. Une connaissance de base de la ligne de commande (CLI) et de la configuration YAML est suffisante. Python sert principalement à l'installation ou pour des usages avancés (packages).
Avec quelles bases de données et sources de données DBT est-il compatible ?
DBT se connecte nativement aux solutions Big Data cloud comme BigQuery, Snowflake, Redshift et Databricks. Grâce à la communauté Open Source et aux adaptateurs, il peut aussi se connecter à PostgreSQL, Oracle, SQL Server (Microsoft), MySQL, Spark et bien d'autres bases de données relationnelles pour gérer des données hétérogènes.
Comment visualiser les données transformées par DBT ?
Une fois les données transformées et stockées dans des tables ou des vues propres (Data Marts), elles peuvent être connectées à n'importe quel outil de Business Intelligence ou de Data Visualisation tel que Power BI, Tableau Software, Qlik, Metabase ou Google Data Studio pour créer des tableaux de bord et aider à la prise de décision.
DBT permet-il de gérer la qualité des données (Data Quality) ?
Oui, c'est l'une de ses forces. DBT intègre nativement des fonctionnalités de tests (unicité, non-nullité, relations de clés étrangères) définis dans les fichiers schema.yml. Cela permet de garantir que les données exploitables livrées aux décideurs sont fiables et d'automatiser le monitoring de la qualité.
Qu'est-ce que la version "DBT Core" par rapport à "DBT Cloud" ?
DBT Core est la version Open Source et gratuite qui s'installe en ligne de commande (CLI) sur votre Desktop (Windows, Mac, Linux) ou via Docker. DBT Cloud est la version SaaS payante (avec license) qui offre une interface web, un planificateur de jobs (scheduler) et une intégration CI/CD facilitée pour l'automation des déploiements.
Comment DBT gère-t-il la documentation des données ?
DBT génère automatiquement un site web statique à partir de vos fichiers de configuration et de vos descriptions. Cette documentation sert de dictionnaire de données, affichant le lignage (Data Lineage), les dépendances entre les modèles, les descriptions des colonnes et les métadonnées, facilitant le travail de toute l'équipe Data.
Peut-on faire de l'analyse incrémentale avec DBT ?
Oui, grâce à la matérialisation de type incremental. DBT permet de ne traiter et de n'insérer que les nouvelles lignes ou les données modifiées depuis la dernière exécution. C'est essentiel pour l'optimisation des performances et la réduction des coûts sur les architectures Big Data traitant d'énormes volumes de données.
DBT est-il adapté aux méthodes Agiles et au DevOps ?
Absolument. DBT traite les transformations de données comme du code logiciel. L'intégration obligatoire avec Git (GitHub, GitLab, Bitbucket) permet le versionning, la révision de code (Pull Requests), et le travail collaboratif entre Data Scientists et Analystes, s'alignant parfaitement sur les pratiques DevOps et Agile.
Peut-on utiliser DBT pour la migration de données ?
Oui. DBT est un excellent outil pour les projets de migration ou de refonte de système d'information. Il permet de recréer la logique métier en SQL standardisé lors du passage d'une architecture On-premise (ex: Oracle) vers une architecture Cloud moderne, assurant la traçabilité et la validation des données migrées.
Retour aux éditeurs "Intégration et flux de données"
Vous souhaitez bénéficier d'experts, de développeurs ou d'une formation sur DBT ? Rendez vous sur la page Contact
Des par des consultants BI de Nantes, Paris, Lyon, Angers, Paris, Le Mans, Lille, Brest, Rennes, Niort, Laval, Lyon, Grenoble, Agen, Bayonne, Montpellier, Saint-Etienne, Bordeaux, Toulouse, La Rochelle, Nîmes, Marseille, Aix-en-provence...
Next Decision vous accompagne sur l'ETL DBT en Région Parisienne, île de france, Nord, Bretagne, Normandie, Nouvelle-Aquitaine, Midi-Pyrénées, Pays de la Loire, et Provence-Alpes-Côte d'Azur, Occitanie.