

Cet article est valable sur toutes les versions de Qlik : Qlik Sense, Qlik Sense cloud/SaaS et QlikView.
Le load Distinct dans Qlik
Lorsque l’on utilise un Load DISTINCT au chargement d’une table, cela a pour effet de supprimer les valeurs en double de la table source. Par contre, lorsque l’on combine cette instruction à une opération de jointure ou d’union, il peut y avoir des comportements surprenants.
Prenons ces 2 tables contenant chacune des doublons :
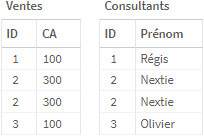
Lorsque l’on fait une jointure classique entre elles, on obtient le résultat suivant :

Ce qui est bien le résultat attendu puisque l’ID 2 est en doublon dans les deux tables, on obtient donc 4 lignes pour ce consultant.
Si maintenant nous ajoutons simplement l’instruction DISTINCT dans la seconde table :

Nous obtenons un résultat plutôt inattendu puisque ce sont tous les doublons de la table FINALE qui ont été supprimés !
De la même façon, si nous déplaçons l’instruction DISTINCT dans la 1ère instruction LOAD :

Le résultat demeure le même !
Solution de contournement dans Qlik
Conclusion : Lorsque l’on utilise un DISTINCT dans une jointure (xxx JOIN) ou une union (CONCATENATE ou concaténation automatique), le dédoublonnage se fait sur la table de sortie et non sur la table intermédiaire !
Ce comportement peut être pratique pour être sûr de ne pas avoir de doublons dans la table finale mais peut engendrer des erreurs s’il n’est pas maitrisé. La solution de contournement est donc de passer par une table temporaire pour réaliser ce dédoublonnement.
Nos consultants Next Decision sont experts certifiés Qlik et vous accompagnent dans votre projet Qlik. Nous pouvons également vous former ! Contactez-nous !