

Du 15 au 18 septembre 2025, s’est tenue à Vienne la European Microsoft Fabric Community Conference (alias FabCon Europe).
Cet événement majeur se décline deux fois par an : une édition aux États-Unis (Las Vegas en 2025) et une édition en Europe. C’est l’occasion pour Microsoft de dévoiler sa roadmap, ses nouveautés et quelques previews autour de sa plateforme de données Microsoft Fabric, mais aussi une rare opportunité d’échanger directement avec les experts présents.
Next Decision était sur place et vous livre sa lecture de l’événement ainsi qu’un retour sur les annonces qui nous ont le plus marqués.
Après des éditions précédentes riches en vagues massives de nouveautés, nous avons cette fois eu le sentiment d’assister à un mouvement de consolidation de la plateforme Fabric. Microsoft a mis l’accent sur :
- La CI/CD pour renforcer l’automatisation, le déploiement et la collaboration des équipes,
- Les performances, améliorées sur l’ensemble des objets de la plateforme,
- La gouvernance avec un prisme sécurité, autour d’annonces très attendues autour de OneLake Security,
- Et bien sûr, l’Intelligence Artificielle, omniprésente dans les sessions et discussions, avec un focus sur ses usages concrets dans Fabric.
Moins d’annonces “coup de tonnerre” peut-être, mais un vrai signal : Microsoft prend en compte les retours de ses utilisateurs et avance dans une logique de maturité.
La roadmap Fabric reste néanmoins très riche. Nous avons sélectionné pour vous les annonces qui nous semblent les plus marquantes.
Autour de la plateforme Microsoft Fabric
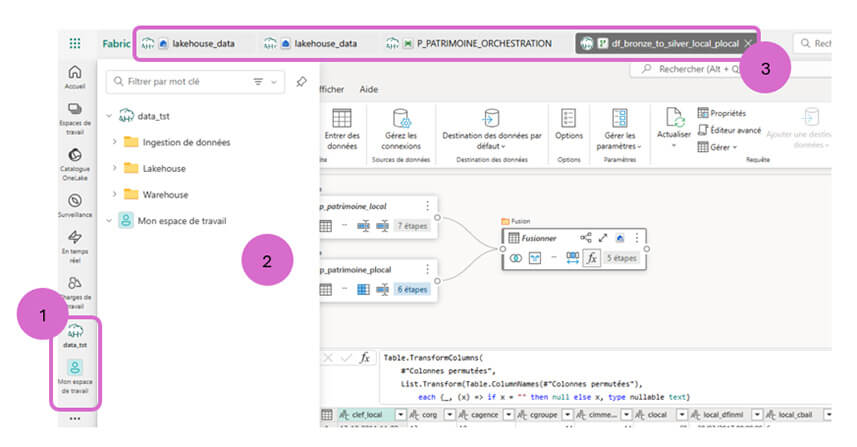
Un changement fort d’interface a été déployé. Pour y avoir accès, il faudra se positionner sur la vue Fabric plutôt que sur celle Power BI qui reste à l’heure actuelle sur la vision classique, que nous connaissons. Cette évolution répond à une demande récurrente : la difficulté de navigation dans les objets ouverts.
Jusqu’ici, Fabric empilait tous les objets consultés dans le bandeau de menu gauche, ce qui pouvait rapidement devenir confus. Microsoft introduit désormais une nouvelle navigation :
- Les espaces de travail restent accessibles dans le menu de gauche (1),
- Un menu dédié détaillant toute l’arborescence des objets de l’espace de travail consulté (2),
- Tous les objets ouverts sont regroupés en onglets en haut de l’interface (3).
Autour de l’ingestion de données avec Data Factory
L’ingestion des données est un sujet central en termes de nouveautés.
Parmi les nouveautés, nous notons notamment :
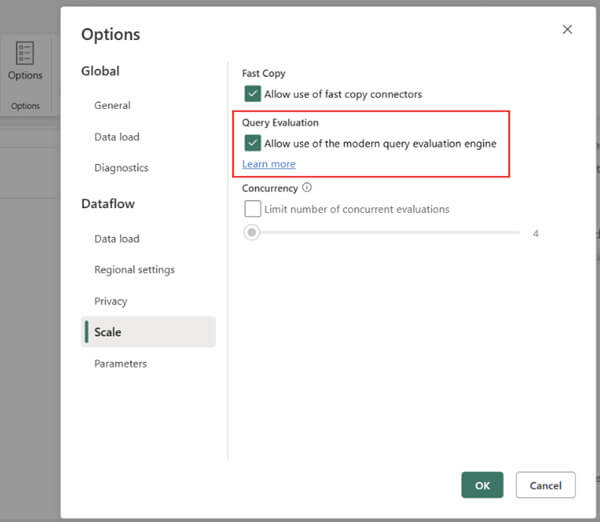
- Le Modern Query évaluation engine, nouvelle preview des Dataflows Gen2, promet des performances accrues au niveau de l’exécution de ces objets. Microsoft indique que les temps de traitement pourraient être divisés par deux pour les flux les plus volumineux. Comme pour de nombreuses fonctionnalités en préversion, il faut activer cette option depuis le Dataflow (preview activable sur les anciennes versions comme sur les plus récentes).
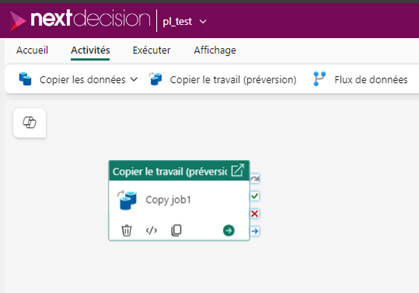
- La mise à disposition d’une nouvelle activité de « CopyJob » au sein des pipelines de données. L’activité de « CopyJob » nous permet d’ingérer des données de manière massive et sans transformations dans un lakehouse ou un warehouse. Elle est très intéressante dans son fonctionnement puisqu’elle intègre la gestion de l’incrémental et c’est une activité avec de très bonnes performances d’ingestion. Dorénavant, nous pouvons orchestrer cette activité dans un pipeline de données ; ce qui constitue une grande nouveauté pour tous ceux qui ingèrent les données en masse dans le lakehouse.
- De nouvelles sources de données disponibles pour le mirroring :
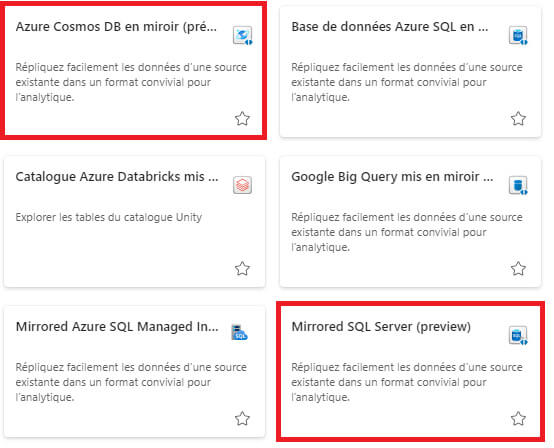
Deux nouvelles sources sont arrivées depuis peu :
- La mise en miroir des bases SQL Server
- Et des bases Azure Cosmos DB
Le mirroring permet de créer un réplica de bases externes directement dans Fabric, sans avoir à gérer un processus d’ingestion classique.
Son principal atout : la prise en charge du Change Data Capture (CDC) qui limite les flux aux seuls changements, réduisant ainsi la charge et améliorant la fraîcheur des données.
À noter : le mirroring n’est pas un remplacement universel des pipelines. Il est particulièrement adapté pour la réplication quasi temps réel de bases opérationnelles, mais reste moins flexible qu’une ingestion orchestrée pour les scénarios nécessitant des transformations, du nettoyage ou une gouvernance fine des flux.
Côté développeurs, nous avons été agréablement surpris de constater que Microsoft facilite de plus en plus l’utilisation de systèmes de développements hors Fabric tel que Visual Studio Code, qui bénéficie désormais de son connecteur direct aux espaces de travail de la plateforme. Une intégration plus aisée et bienvenue.
Autour de la sécurité
La FabCon a également été marquée par plusieurs annonces concernant la sécurité sur la plateforme, avec en particulier l’arrivée de OneLake Security, un terme revenu à de nombreuses reprises dans les sessions.
Mais en quoi consiste cette première étape vers une sécurité centralisée dans OneLake ? En Preview, la nouveauté concernera d’abord le Lakehouse. Elle permettra de définir une sécurité d’accès aux données - à la ligne, à l’objet ou à la colonne - directement depuis les tables du Lakehouse. Cette configuration se propagera ensuite automatiquement à tous les objets hérités du Lakehouse, assurant une cohérence et une simplification de la gestion des droits.
Un nouvel onglet OneLake Security fera également son apparition dans le catalogue OneLake, offrant une vue claire sur les rôles et attributions.
Peu de visuels sont disponibles à ce stade, la fonctionnalité n’étant encore accessible qu’en Preview (et pas encore activée sur notre tenant). Ci-dessous, toutefois, un aperçu de l’onglet « sécurité » accessible depuis le catalogue.
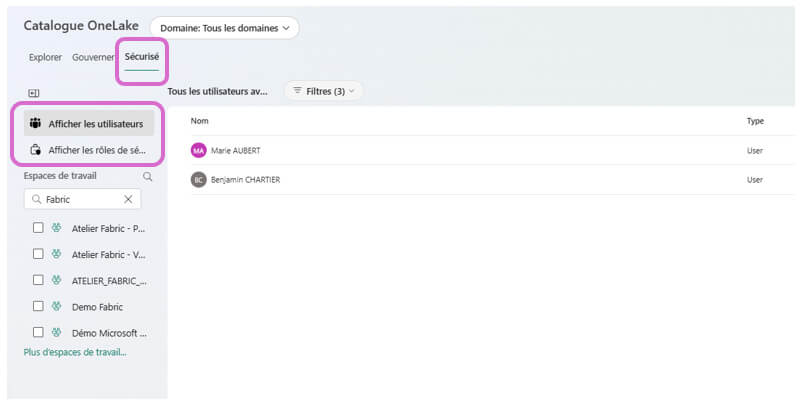
Avec une sécurité plus centrale dans la plateforme émerge naturellement une notion plus forte de gouvernance. Microsoft a donc renforcé ses outils de pilotage et de surveillance afin de donner aux administrateurs une meilleure visibilité sur l’usage et les performances de Fabric.
Nous notons ainsi l’arrivée d’une nouvelle version de la Capacity Metrics (dernière mise à jour : version 47). Elle apporte :
- Un suivi beaucoup plus fin, allant jusqu’au détail des requêtes les plus consommatrices de CU
- Une profondeur d’historique élargie
- Une navigation par espace de travail
- L’ajout de nouveaux onglets dédiés à des analyses plus détaillées

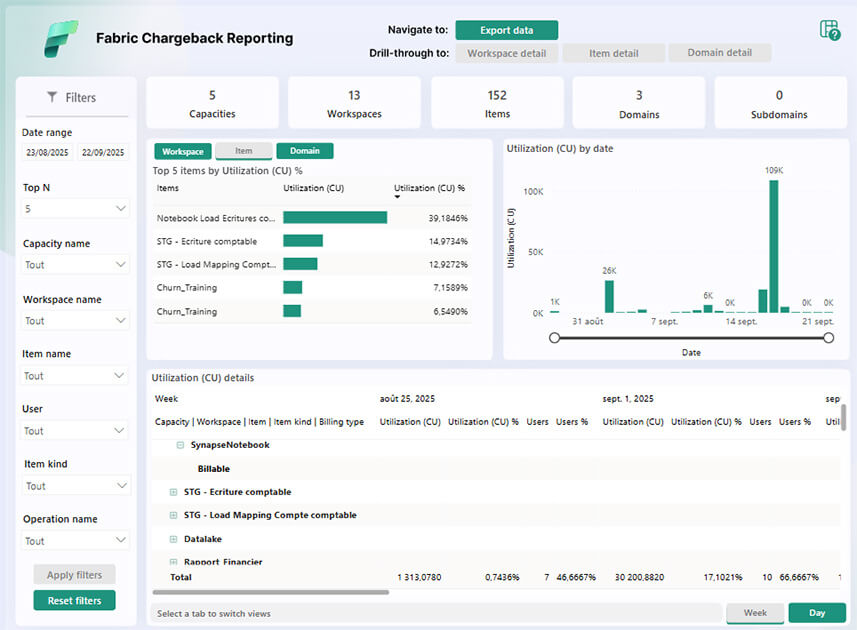
Autre nouveauté côté gouvernance : l’arrivée de l’application Reporting Chargeback Ayant pour objectif de fournir une vision consolidée de la consommation de ressources et permettre un suivi détaillé des coûts liés à l’usage de Fabric.
Cette application facilite :
- L’attribution des coûts par espace de travail, objet ou domaine,
- L’analyse de la consommation afin d’identifier les usages les plus gourmands,
- Plus largement, le pilotage de la consommation des environnements Fabric par utilisateur, espace de travail, objet, capacité, type d’opération…
Autour de la CI/CD
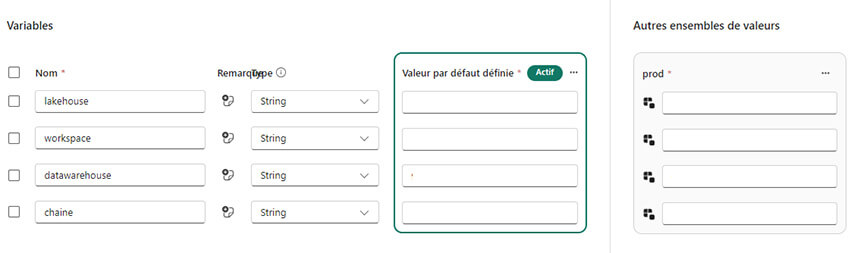
Grande nouvelle durant cette FabCon nous avons eu la confirmation que les bibliothèques de variables sont disponibles de manière générale dans Fabric. Pour rappel, les bibliothèques de variables nous permettent de créer des variables et de les appeler leur de nos développements.
Ce qui est remarquable avec ces bibliothèques, c'est que nous pouvons déterminer les ID des espaces de travail, lakehouse, datawarehouse ou même chaîne de connexion SQl afin d’automatiser le passage des environnements de développement aux environnements de production lors des déploiements.
Nous avons également ressenti une forte tendance à tendre vers une structuration et une organisation véritablement de développement dans Fabric, notamment en intégrant dès le début des développements l’utilisation de Azure DevOps pour assoir tout de suite une solution de CI/CD.
Nous sommes convaincus que dorénavant, dès le début du projet, nous devons synchroniser les espaces de travail de développement et de production dans des repository git et les attacher à une branche distincte.
Pour nous l’organisation la plus simple serait d’avoir l’espace de développement attaché à la branche main de notre projet git et de créer des branches features pour chaque développeur. Le principe de pull request assure ensuite que la branche main de notre projet est toujours fonctionnelle. Le second élément est l’intégration d’un pipeline de déploiement entre notre espace de travail de développement et de production afin d’être sûre que la production et à l’image de l’espace de développement.
Autour du Warehouse
Attendue par beaucoup, la fonction MERGE arrive en préversion. Elle combine plusieurs opérations SQL qui sont l’INSERT, l’UPDATE et le DELETE dans une seule et même commande. Elle va permettre de dynamiser nos transformations au sein du warehouse et ainsi améliorer la lisibilité : un grand bol d’air frais pour tous les développeurs SQL.

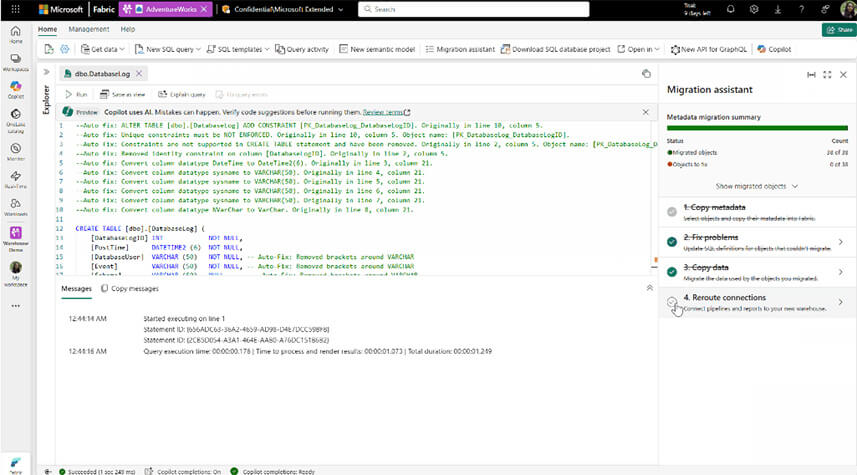
Une autre belle annonce autour du nouvel assistant de migration des entrepôts de données Fabric. Ce nouvel assistant, disponible en option, permet de migrer facilement les entrepôts ou bases de données Azure Synapse vers Microsoft Fabric à l’aide d’un fichier DACPAC.
La Fabric Conférence est aussi l’occasion de découvrir quelques sessions beaucoup plus techniques. Nous avons eu le plaisir d’en suivre une consacrée aux optimisations dans le Warehouse, l’occasion d’apprendre la venue de nouveautés prometteuses (roadmap non encore précisée pour certaines) telles que :
- L’ajout des CLUSTER
- La mise en place de “Custom Pool” : ce mécanisme permet une isolation physique des traitements via des pools dédiés. Chaque pool est défini comme un prorata de la capacité totale, ce qui évite que des requêtes très gourmandes en ressources n’empiètent sur l’exécution des traitements de production. Cette fonctionnalité est déjà disponible en preview privée.
Cette session a également été le moment de rappeler de bonnes pratiques, bien connues et éprouvées ces dernières années autour de l’écriture de requêtes SQL (type de données à clarifier, éviter les nvarchar(8000), etc.) ou encore de la consultation du plan d’exécution d’une requête. Le plan d’exécution reste accessible, via XML, depuis SQL Server Management Studio (SSMS). Les interfaces n’ont pas changé, nous ne sommes pas perdus !
Autour de Power BI
Déjà annoncée ces derniers mois, l’arrivée de la création de modèles sémantiques en mode Import directement depuis l’interface Fabric a de nouveau été mise en avant par Microsoft. Concrètement, cette évolution ouvre la voie à une expérience 100 % en ligne : depuis la récupération des données jusqu’à leur restitution, sans passer par Power BI Desktop.
Forcément, les discussions “off” ont été nombreuses autour d’une possible fin progressive de Desktop. Chez Next Decision, nous restons encore très attachés à cet outil, mais il faut reconnaître que cette nouveauté simplifiera considérablement la vie de certaines équipes, notamment celles pour qui l’installation ou la mise à jour de Desktop pouvait s’avérer contraignante.
Parmi les annonces marquantes côté Power BI / DAX, Microsoft a officialisé l’arrivée des UDF (User Defined Functions). Une avancée très attendue qui permettra enfin de créer, réutiliser et partager ses propres fonctions DAX.
Concrètement, cela ouvre la porte à :
- Une factorisation du code dans les modèles
- Une standardisation des calculs entre équipes et projets
- Une meilleure maintenabilité des solutions, en réduisant la duplication des formules
Autre annonce clé : l’arrivée en Preview de la fonctionnalité Enhanced DAX Time Intelligence !
Jusqu’ici, les fonctions DAX de gestion du temps reposaient sur des calendriers standards, souvent limités à l’année civile. Avec cette évolution, il devient possible de définir et d’utiliser des calendriers personnalisés (par exemple fiscaux ou retail 4-5-4). Cela permettra d’adapter nativement les calculs temporels aux réalités métiers, sans avoir à multiplier les contournements ou tables de dates spécifiques.
Pour de plus amples détails sur ces deux fonctions, nous vous donnons RDV dans notre newsletter consacrée aux nouveautés Power BI du mois prochain.
Enfin, nous notons un renforcement fort avec les partenaires de l’écosystème Data. Nous constatons que des rapprochements importants se concrétisent notamment avec Snowflake avec qui il est de plus en plus facile de travailler directement dans la plateforme (mirroring Snowflake).
Vous l’aurez compris, la Fabric Conférence constitue un événement riche en annonces et nouveautés, dont nous ne pouvions retracer qu’une partie ici, mais également en échanges avec l’opportunité de rencontrer les experts Microsoft et la grande communauté autour de l’éditeur. Reste donc à tester et mettre en œuvre l’ensemble de ces éléments.
Et pour ceux d’entre vous qui auraient envie de suivre l’événement : les prochaines FabCon se tiendront à Atlanta en mars 2026 ou à Barcelone en septembre 2026.
Restez connectés, très bientôt une grande nouveauté côté Next Decision afin de toujours plus vous partager les informations importantes !
Nos consultants Next Decision sont experts certifiés Microsoft Fabric et vous accompagnent dans votre projet Microsoft Fabric. Nous pouvons également vous former. Contactez-nous !