

Face à des poids lourds du cloud tels que Microsoft, Google, Amazon ou Snowflake, on peut être tenté de mettre en place une modern data platform disposant d’un Lakehouse par exemple, le tout en voulant s’appuyer sur des briques Open Source et, le tout, On-Premise.
Quelques arguments en faveur de cette démarche :
- Confidentialité des données : tout est stocké on-premise (ou chez un hébergeur avec un cloud privé)
- Contrôle des accès aux données
- Réduction des coûts de licences d’une plateforme Cloud (dont on ne maîtrise pas les augmentations de coûts dans les années à venir)
Cette démarche n’est en revanche pas exempte de défauts. En voici quelques uns :
- Infrastructure à réaliser sur mesure, on-premise
- Coûts de mise en oeuvre potentiellement élevés : rien n’est managé donc il faut tout recréer
- Choix d’outils complexe : beaucoup de nouveaux acteurs arrivent sur le marché, il faut donc choisir clairement son orientation
- Mise à jour régulière nécessaire des différentes briques de la stack
Bref, cela nécessite des compétences techniques élevées et le ROI n’est pas aussi immédiat que lorsque l’on opte pour une solution cloud. Mais à l’heure des questions autour de la souveraineté, cette approche peut être porteuse de sens.
Choix technologiques
Si on souhaite reproduire un Microsoft Fabric ou un Snowflake on-premise, il faut dans un premier temps choisir les différentes briques qui seront utiles au projet. Cette étape est assez chronophage car il y a beaucoup d’itérations avant de trouver potentiellement la bonne stack finale.
Voici les règles que nous souhaitions respecter au maximum pour notre stack :
- On privilégiera les solutions proposant une offre gratuite et Open Source (sous licence Apache 2.0)
- Entre le format de stockage Delta et Iceberg, nous nous orientons vers de l’Icerberg. Ça sera le socle de notre système transactionnel (futur entrepôt de données)
Voici les briques nécessaires au projet :
- Couche de stockage objet : C’est le cœur de stockage de la solution. Il faut une solution qui permette le stockage de tous formats de fichiers. C’est notre futur Datalake. On voudra stocker dans cette espace des fichiers divers et variés tels que des fichiers csv, des json, des parquet, des fichiers delta ou iceberg. Historiquement, nous avions opté pour MinIO mais son manque de roadmap claire sur la version gratuite nous a fait basculer sur une solution alternative : RustFS.
- Stockage fichier : Nous avons fait le choix de nous orienter vers le format Iceberg. Ce format nous permet un côté transactionnel, idéal pour un entrepôt de données et des projets décisionnel.
- Catalogue de métadonnées : Cet élément est indispensable pour maintenir la structure des fichiers Iceberg. Nous choisirons Nessie.
- Moteur SQL : Encore un élément très important de notre stack. Il nous faut un moteur SQL qui permette d’interagir avec nos fichiers Iceberg et nous offre des fonctionnalités SQL prête pour de la BI et des projets de DataScience. Ici, nous avons opté pour Dremio.
- ETL : Nous avons choisi deux solutions pour notre stack : Apache Nifi et DBT.
- Outils BI : N’importe quel outil pourrait se connecter à notre stack, tel que des PowerBI ou Qliksense. Ici, en restant sur de l’Open Source, on peut envisager Metabase.
- Data Science : Dans la même logique, on opte pour Apache Zeppelin qui propose des notebooks très puissants.
- Orchestration : Enfin, la couche d’orchestration des flux de données sera réalisée avec Apache Airflow
Voici, en synthèse, notre future stack :
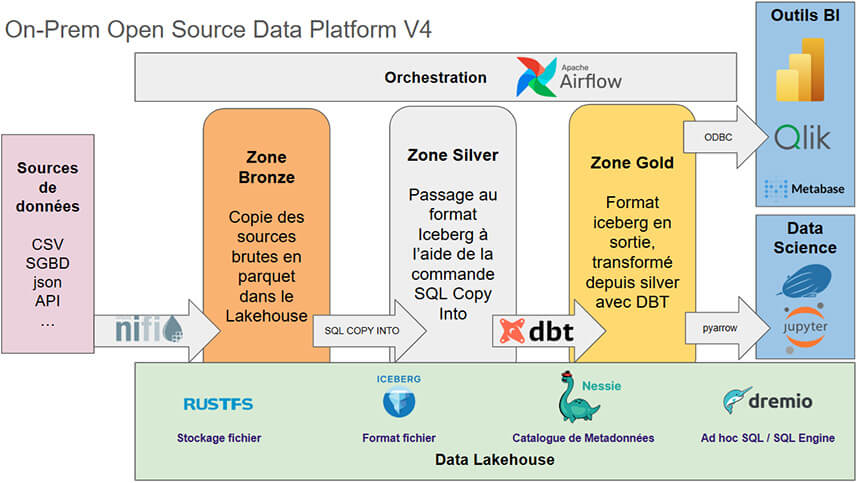
Nous allons pouvoir découper notre stack en différents lots :
- Lot 1 : création du Data Lakehouse avec RustFS, Iceberg, Nessie et Dremio
- Lot 2 : ajout du volet Data Science avec Apache Zeppelin
- Lot 3 : intégration d’Apache Nifi / DBT
- Lot 4 : Orchestration des flux de données avec Apache Airflow
Lot 1 : Bâtir notre Data Lakehouse
Pour cette première brique, plusieurs éléments nous seront nécessaires :
- RustFS
- Iceberg
- Nessie (Nous avions pensé également à Polaris mais, malheureusement, ce catalogue n’est pas disponible dans l’offre Open Source et uniquement dans l'offre Enterprise.)
- Dremio
Notre docker compose :
version: "3"
services:
# Nessie Catalog Server Using In-Memory Store
nessie:
image: projectnessie/nessie:latest
container_name: nessie
environment:
- nessie.tracing.enabled=false
- quarkus.oidc.tenant-enabled=false
networks:
iceberg:
ports:
- 19120:19120
rustfs:
image: 'rustfs/rustfs:latest'
environment:
- RUSTFS_CONSOLE_ENABLE=true
- RUSTFS_ACCESS_KEY=admin
- RUSTFS_SECRET_KEY=password
volumes:
- rustfs_data:/data
ports:
- '9000:9000'
- '9001:9001'
networks:
iceberg:
container_name: rustfs
dremio:
platform: linux/x86_64
image: dremio/dremio-oss:latest
ports:
- 9047:9047
- 31010:31010
- 32010:32010
container_name: dremio
environment:
- DREMIO_JAVA_SERVER_EXTRA_OPTS=-Dpaths.dist=file:///opt/dremio/data/dist<br< a=""> /> - DREMIO_TELEMETRY_DISABLED=true
networks:
iceberg:
volumes:
- dremio_data:/opt/dremio/data
- dremio_conf:/opt/dremio/conf</br<>
networks:
iceberg:
volumes:
nessie_data:
rustfs_data:
dremio_data:
dremio_conf:
Pour cette première partie de la stack, pas de nécessité de créer de dockerfile (mais cela sera nécessaire pour les prochaines étapes…)
Il ne nous reste plus qu’à configurer l’ensemble :
Étape 1 : Créer un bucket dans RustFS
L’accès à RustFS se réalise via l’URL suivante : http://localhost:9001/rustfs/
Il faut se connecter à l’aide du compte / mot de passe du docker compose puis créer son bucket : warehouse
On peut organiser un peu les dossiers dans ce nouveau bucket en créant des dossiers :
(Exemple d’organisation en mode médaillon)
Étape 2 : Créer un compte dans Dremio et faire le lien avec RustFS et Nessie
Maintenant que le bucket est créé, il faut, dans Dremio, faire le lien entre RustFS et Nessie, en créant une nouvelle source :
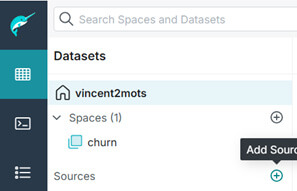
Voici la liste des catalogues lakehouse disponibles :
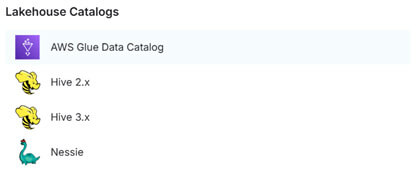
Ici, nous aurions aimé pouvoir choisir Polaris mais il n’est pas présent dans Dremio Community Edition donc nous allons choisir Nessie.
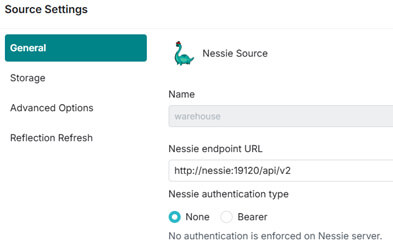
Nous faisons, pour commencer, le lien vers notre Nessie, sans autorisation.
Dans la partie Storage, nous mettons le chemin du bucket ainsi que le compte / mot de passe pour y accéder :
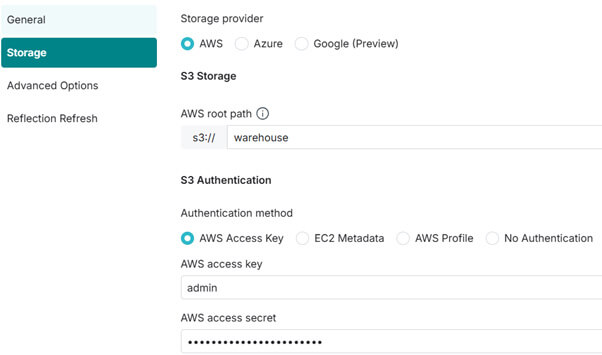
Enfin, nous ajoutons quelques options supplémentaires pour faire le lien avec RustFS :
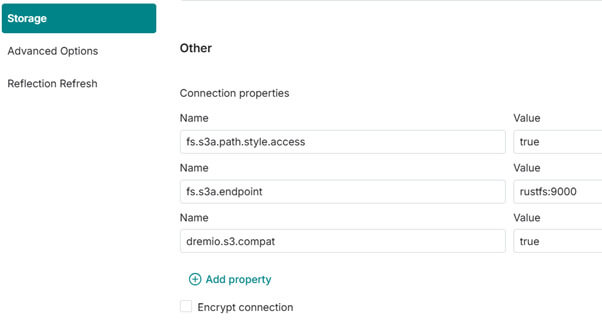
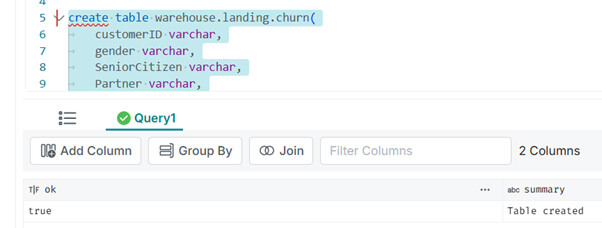
Étape 3 : Créer ses premières tables au format Iceberg et réaliser des chargements manuels
Maintenant, nous pouvons créer nos premières tables en iceberg manuellement, pour tester que tout est bien fonctionnel :
create table warehouse.landing.churn(
customerID varchar,
gender varchar,
SeniorCitizen varchar,
Partner varchar,
Dependents varchar,
tenure varchar,
PhoneService varchar,
MultipleLines varchar,
InternetService varchar,
OnlineSecurity varchar,
OnlineBackup varchar,
DeviceProtection varchar,
TechSupport varchar,
StreamingTV varchar,
StreamingMovies varchar,
Contract varchar,
PaperlessBilling varchar,
PaymentMethod varchar,
MonthlyCharges varchar,
TotalCharges varchar,
Churn varchar
)
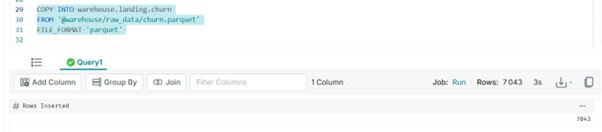
COPY INTO warehouse.landing.churn
FROM '@warehouse/raw_data/churn.parquet'
FILE_FORMAT 'parquet'
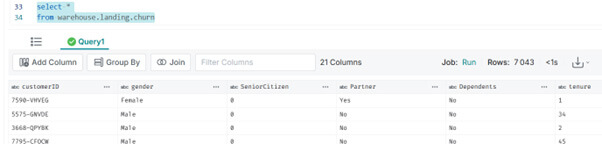
select *
from warehouse.landing.churn
create table warehouse.bronze.churn as
select * from warehouse.landing.churn

Tout semble fonctionnel pour ce premier lot !
Nous venons de créer le premier lot de notre stack : le lakehouse.
Ce dernier est donc constitué des éléments suivants :
- RustFS : Pour le stockage objet
- Iceberg : Pour le format de fichier
- Nessie : Pour le metadata catalog
- Dremio : Pour le requêtage SQL
Nous aimerions maintenant ajouter un volet Data Science à notre stack avec une brique très connue : Apache Zeppelin.
Lot 2 : Ajout de la partie Data Science
Maintenant que notre socle Lakehouse est créé, on peut ajouter la partie Data Science.
Nous allons devoir créer un dockerfile dédié à Zeppelin, car nous souhaitons ajouter plusieurs éléments à l’image de base :
- pyarrow (Flight SQL : pour interagir avec Dremio)
- Spark / Scala : pour pouvoir utiliser le langage pySpark / SQL dans les notebooks
Voici le dockerfile final :
# ---------------------------------------------------------------------
# Apache Zeppelin + Spark + Scala + PyArrow (Flight SQL)
# ---------------------------------------------------------------------
FROM apache/zeppelin:0.11.2
USER root
# === Dépendances système ===
RUN apt-get update && \
apt-get install -y \
openjdk-11-jdk \
scala \
python3-pip \
wget \
curl \
build-essential \
libssl-dev \
libgrpc++-dev \
libprotobuf-dev \
protobuf-compiler-grpc \
python3-dev \
git && \
rm -rf /var/lib/apt/lists/*
# === Installer Spark ===
ENV SPARK_VERSION=3.5.7
ENV HADOOP_VERSION=3
ENV SCALA_VERSION=2.13
ENV SPARK_HOME=/opt/spark
ENV PATH="$PATH:$SPARK_HOME/bin"
RUN mkdir -p /opt/spark && \
wget -qO- https://downloads.apache.org/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}-scala${SCALA_VERSION}.tgz \
| tar xvz -C /opt/spark --strip-components=1
# === Installer PyArrow (avec Flight SQL) + Pandas ===
RUN pip install --no-cache-dir --upgrade pip && \
pip install --no-cache-dir \
"pyarrow[flight,parquet,pandas]" \
pandas \
requests
# === Config Zeppelin : désactiver authentification ===
RUN cp /opt/zeppelin/conf/zeppelin-site.xml.template /opt/zeppelin/conf/zeppelin-site.xml && \
sed -i 's|<value>org.apache.zeppelin.realm.LdapRealm</value>|<value>anonymous</value>|g' /opt/zeppelin/conf/zeppelin-site.xml || true
EXPOSE 8080
USER ${NB_UID}
=== Commande de démarrage ===
CMD ["/opt/zeppelin/bin/zeppelin.sh"]
Et notre docker compose modifié :
zeppelin:
build:
context: dockerfile
dockerfile: dockerfile_zeppelin
container_name: zeppelin
ports:
- "8080:8080"
environment:
- ZEPPELIN_LOG_DIR=/logs
- ZEPPELIN_NOTEBOOK_DIR=/notebooks
volumes:
- ./notebooks:/notebooks
- ./logs:/logs
networks:
- iceberg
Là alors, il sera possible de créer un notebook en pySpark :
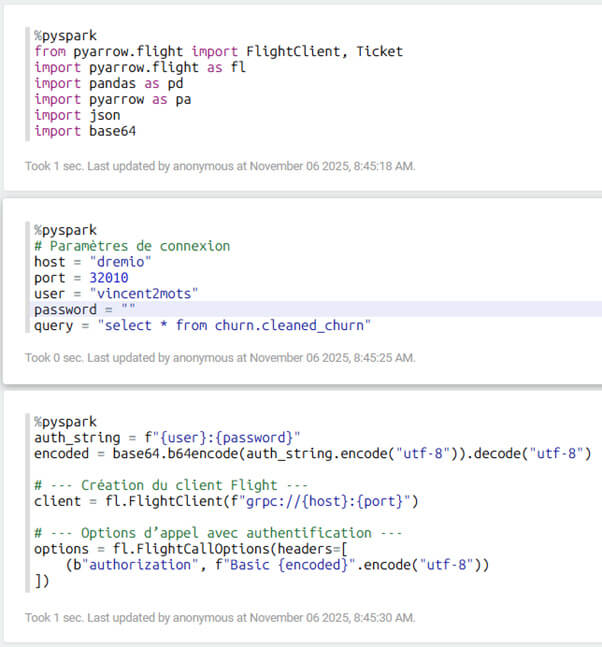
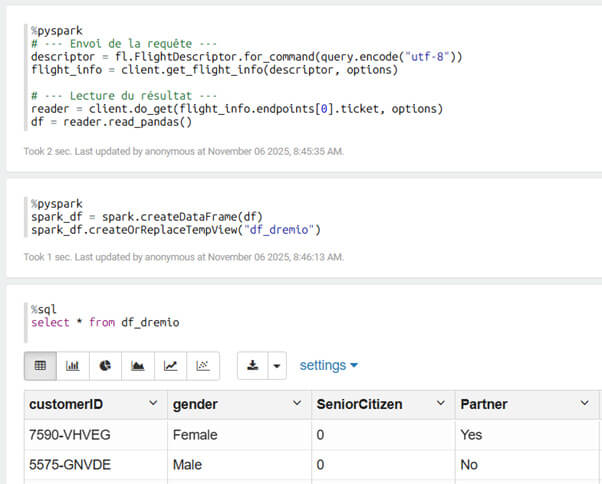
Une fois les données dans le dataframe Pandas, il devient alors aisé d’utiliser Scikit-Learn pour réaliser du Machine Learning.
La suite ?
Dans le lot suivant, nous aborderons l’intégration / transformation de données avec Apache Nifi et DBT. Puis il sera nécessaire de voir Apache Airflow pour l’orchestration de tous ces éléments.
Vous souhaitez bénéficier d'experts ou d'un accompagnement sur votre projet data ? Rendez-vous sur la page Contact.