

Landing / Staging - l’Ingestion des données dans snowflake à partir de Azure Datalake avec l’aide de Semarchy XDI
Pour les besoins de cet article, nous allons partir du principe que la gestion des droits et de la liaison à la source de données externes, c'est à dire notre Datalake, est déjà implémentée. Nous allons nous concentrer maintenant sur toute la mise en œuvre de notre architecture.
Comme évoqué dans l'article précédent, nous allons utiliser Azure Datalake comme source de données. Selon les bonnes pratiques énoncées par Snowflake, il est fortement conseillé de segmenter les fichiers en parties dont la taille est inférieure ou égale à 150-250 Mo. De cette manière, il sera beaucoup plus facile pour Snowflake de gérer lui-même la parallélisation en interne. Cet article étant avant tout un POC, nous n’allons pas forcément respecter cette règle.
Pour l'ingestion, nous utiliserons donc une procédure générique Snowflake que nous allons décrire en Javascript (pour rappel : il reste possible de décrire les procédures dans d'autres langages, Python par exemple). Mais avant de la présenter, nous allons mettre en place une table de paramétrage qui pourrait se situer dans un schéma technique (ici, nous allons la mettre dans le schéma).
Cette table de paramétrage va nous permettre de :
- Trouver un fichier sur notre Datalake avec son chemin
- Relier un fichier à une table selon sa nomenclature (nous utiliserons une regex pour le masque du nom de fichier)
- Appliquer un «file_format» à chaque fichier. Le file format est un objet de Snowflake décrivant la manière d'importer le fichier dans le SGBD en fonction de ses caractères de séparation, ses formats de dates, la gestion des valeurs manquantes ou "NULL", etc.
Voici le code de création avec des exemples de remplissage de cette table :
--Table de paramétrage pour l'ingestion automatique
CREATE OR REPLACE TABLE TECH.TECH_PARAM_INGESTION (
TABLE_NAME VARCHAR(100),
SCHEMA VARCHAR(100),
FILEPATH_STAGE VARCHAR(300),
FILENAME_MASK VARCHAR(100),
FILE_FORMAT VARCHAR(100),
NB_DAYS_INGEST INTEGER
);
INSERT INTO TECH.TECH_PARAM_INGESTION VALUES ('RAW_test', 'RAW', 'DATALAKE_RAW/TEST/', 'test.*.csv', 'CSV_STANDARD', 60);
Avant de continuer, nous avons besoin de créer les tables de destination du landing dans notre BDD. On pensera bien à ajouter les deux champs techniques suivants :
- METADATA$FILLENAME : nom du fichier d'origine. Il sera utile lors de phases de débug.
- METADATA$FILEDATE : date du fichier source. Cela va nous permettre de connaître l’ancienneté de la version des enregistrements.
/* Exemple de DDL pour une table du schéma RAW */
create or replace TABLE RAW.RAW_TEST (
METADATA$FILENAME VARCHAR(1000),
METADATA$FILEDATE DATE,
Id VARCHAR(200),
Nom VARCHAR(200),
Code VARCHAR(200)
);
Maintenant que nous avons une table de paramétrage et nos tables de destination dans le schéma RAW_TRACA, nous allons pouvoir passer à notre procédure stockée d'ingestion (l’explication est en dessous de l’implémentation) :
CREATE OR REPLACE PROCEDURE RAW.INGESTION_DATA("P_SCHEMA" VARCHAR(200), "P_TABLE_NAME" VARCHAR(200), "P_DATE_TO_LOAD" VARCHAR)
RETURNS STRING
LANGUAGE JAVASCRIPT
EXECUTE AS OWNER
AS $$
var result = "";
// === PARTIE I - Récupération de la table à ingérer si le nom est renseigné dans la table des paramètres d''ingestion
if (P_TABLE_NAME!=null) {
var sql_command_get_ingest = `SELECT * FROM ` + P_SCHEMA + `.TECH_PARAM_INGESTION WHERE TABLE_NAME = \'` + P_TABLE_NAME + `\' AND CHARGEMENT_ACTIF = 1`
} else {
// sinon, on prend tous les résultats de la table (pour le schéma donné)
var sql_command_get_ingest = `SELECT * FROM ` + P_SCHEMA + `.TECH_PARAM_INGESTION WHERE CHARGEMENT_ACTIF = 1`
}
// Récupération des tables du schéma pour l''ingestion
var sql_get_ingest = snowflake.createStatement({
sqlText: sql_command_get_ingest
});
var result_get_ingest = sql_get_ingest.execute();
// === PARTIE II - Pour chaqhe résultats de la partie I
while (result_get_ingest.next()){
filepathStage = result_get_ingest.FILEPATH_STAGE;
filename = result_get_ingest.FILENAME_MASK;
fileformat = result_get_ingest.FILE_FORMAT;
nbDaysIngest = result_get_ingest.NB_DAYS_INGEST;
tableName = result_get_ingest.TABLE_NAME;
// === PARTIE II - A - Création du sql de la requête de copie
// Récupération des noms de colonnes de la table concernée
var sql_command_get_table_columns = `SELECT LISTAGG (\'t.$\' || (ORDINAL_POSITION - 2) || \' AS \' || column_name, \', \' )
WITHIN GROUP (ORDER BY ORDINAL_POSITION) AS QUERY_FIELD
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = \'` + P_SCHEMA + `\' AND TABLE_NAME = \'` + tableName + `\'
AND COLUMN_NAME NOT IN ( \'METADATA$FILENAME\', \'METADATA$FILEDATE\');`
var sql_get_table_columns = snowflake.createStatement({
sqlText: sql_command_get_table_columns
});
var result_get_table_columns = sql_get_table_columns.execute();
result_get_table_columns.next();
var queryField = result_get_table_columns.QUERY_FIELD;
// === PARTIE II - B - On définit les dossiers à récupérer dans le datalake
if (P_DATE_TO_LOAD != null) {
// Attention : P_DATE_LOAD doit être sous la forme YYYY-MM-DD
var sql_command_get_nb_days = `SELECT SUBSTR(\'` + P_DATE_TO_LOAD + `\', 9, 2) AS DAY,
SUBSTR(\'` + P_DATE_TO_LOAD + `\', 6, 2) AS MONTH,
SUBSTR(\'` + P_DATE_TO_LOAD + `\', 0, 4) AS YEAR`
} else {
var sql_command_get_nb_days = `SELECT LPAD(DAY(DATEADD(DAY, \'-\' || seq4(), current_date())), 2 ,\'0\') as DAY,
LPAD(MONTH(DATEADD(DAY, \'-\' || seq4(), current_date())), 2 ,\'0\') as MONTH,
YEAR(DATEADD(DAY, \'-\' || seq4(), current_date())) as YEAR
FROM table (generator(rowcount => ` + nbDaysIngest + `))`;
}
var sql_get_nb_days = snowflake.createStatement({
sqlText: sql_command_get_nb_days
});
var result_get_nb_days = sql_get_nb_days.execute();
// PARTIE II - C - Copie des fichiers du datalake dans les tables RAW de snowflake
// Pour chaque dossier du stage concerné, on copie le fichier
while (result_get_nb_days.next()){
day = result_get_nb_days.DAY;
month = result_get_nb_days.MONTH;
year = result_get_nb_days.YEAR;
// Suppression des données si le fichier a déjà été intégré
var sql_cmd_delete_old = "DELETE FROM " + P_SCHEMA + "." + tableName + " WHERE METADATA$FILENAME IN (SELECT DISTINCT METADATA$FILENAME FROM @" + P_SCHEMA + "." + filepathStage + year + "/" + month + "/" + day + ") ;"
var statement_delete_old = snowflake.createStatement({
sqlText: sql_cmd_delete_old
});
var result_delete = statement_delete_old.execute();
// Copie dans la table
var sql_command_copy = `COPY INTO ` + P_SCHEMA + `.` + tableName + ` FROM (
SELECT METADATA$FILENAME, TO_DATE(\'`+ year + `/` + month + `/` + day + `\',\'yyyy/mm/dd\') AS METADATA$FILEDATE, ` + queryField + ` FROM @` + P_SCHEMA + `.` + filepathStage + year + `/` + month + `/` + day + `(FILE_FORMAT => ` + fileformat + `) t)
PATTERN = \'.*` + filename + `\'
FORCE = TRUE`;
// Mise en log de la requête de copie
var sql_add_log = "INSERT INTO tech_log_ingestion (line) VALUES (\'" + sql_command_copy.substring(0, 4000).replaceAll("\'", "\'\'") +"\');"
var query_add_log = snowflake.createStatement({
sqlText: sql_add_log
}) ;
query_add_log.execute() ;
var sql_copy = snowflake.createStatement({
sqlText: sql_command_copy
});
var result_copy = sql_copy.execute();
}
result = result + P_SCHEMA + "." + tableName + " updated \\n";
}
return sql_command_copy ;
$$;
L’explication de la méthode technique d’ingestion dans snowflake à partir de Azure Datalake avec l’aide de Semarchy xDI
Cette procédure est longue, mais voici une explication concise de ce qu'elle fait :
- Partie I - Récupération des informations de paramétrage selon les paramètres donnés :
- Si aucun paramètre n'est donné sur le nom de la table, on va requêter l'ensemble des tables du schéma dans la table de paramétrage pour récupérer les informations nécessaires à l'import.
- Si le nom de la table à récupérer est précisée, on va requêter la table de paramétrage uniquement sur cet enregistrement.
- Partie II - Pour chaque résultat de la partie I (donc si on a précisé le nom de la table à récupérer, nous n'avons qu'un seul tour de boucle à effectuer) :
- A - On crée une requête SQL d’ingestion en récupérant dynamiquement les noms des colonnes de nos tables cibles. On ajoute les deux colonnes (nom du fichier source, date du fichier source).
- B - On récupère les dossiers à cibler dans le Datalake en fonction de la plage de date qui a été fixée et le path récupéré dans la table de paramétrage. C'est sur ces fichiers que nous allons boucler.
- C - Enfin, pour chaque dossier à scanner, on va supprimer les anciennes données dans la cible correspondantes à notre date et nom de fichier (ce qui permettra d'éviter de doublonner), puis on va exécuter la requête définie dans II-A-
Cette procédure peut être appelée via Semarchy xDI en la reversant et en l'utilisant dans une brique "SQL Operation". On peut ainsi faire un seul appel et charger toutes les tables décrites dans la table de paramétrage, ou filtrer les appels sur seulement certains fichiers à charger.
Maintenant que notre procédure stockée est en place, nous pouvons l’appeler dans Semarchy xDI :
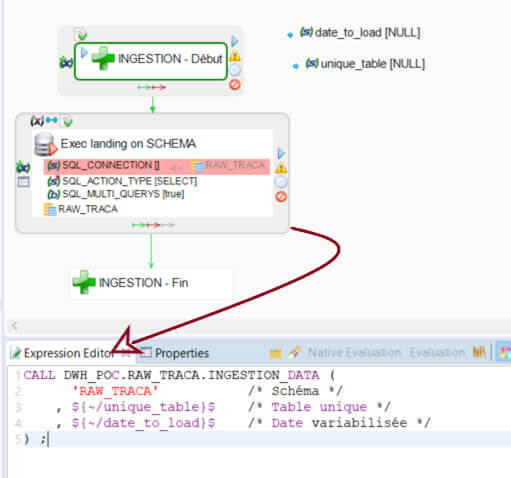
Dans ce process, nous avons une brique «SQL Operation» de type SELECT, qui va faire un appel à la procédure Snowflake d'ingestion des données. On va vouloir variabiliser le jour ainsi que la table à charger. On mettra par défaut les valeurs NULL, la procédure va pouvoir les interpréter et réagir en conséquence. Nous allons exporter ce process en tant que delivery pour pouvoir l’utiliser dans une brique «execute delivery» de Semarchy xDI. Nous verrons l’utilité de cette manipulation dans la suite de cet article.
Pour la suite de l'article, suivez ce lien.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ou Semarchy xDI ? Rendez vous sur la page Contact