

Contexte général
Snowflake est une "modern data platform" hébergée dans le cloud. L’hébergement des données se fait dans un cloud au choix du client (Azure, Google ou AWS). Snowflake permet notamment de stocker, organiser, transformer et analyser de gros volumes de données, qu’elles soient structurées ou semi-structurées. Il est possible d’utiliser différents langages pour réaliser cela, notamment du SQL et du Python.
Talend est une solution d’intégration de données globale comportant plusieurs modules (ESB, ETL, ELT, API, Data Preparation, Data Quality, Data Stewardship, Change Data Capture). Dans notre contexte, nous allons utiliser la partie Data Integration. Il est donc possible d’utiliser Talend comme un ETL “classique” mais aussi comme un ELT.
Dans cet article, nous allons voir comment répliquer des données sources positionnées sur un SQLServer vers Snowflake avec Talend, et comment les transformer sur Snowflake grâce aux composants ELT disponibles.
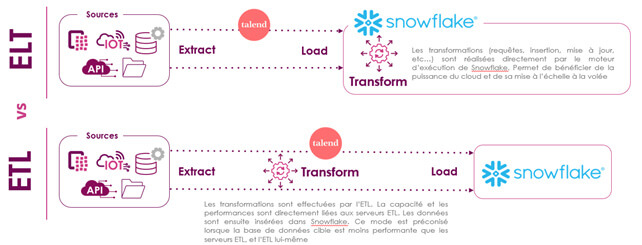
Différences ELT Vs ETL
Ingestion des données sources
Afin de transformer les données en mode “ELT”, il faut dans un premier temps récupérer les données de façon classique et les insérer dans Snowflake.
Nous ouvrons donc une connexion SQLServer pour notre source et une connexion Snowflake pour notre cible avec le composant tDBConnection :
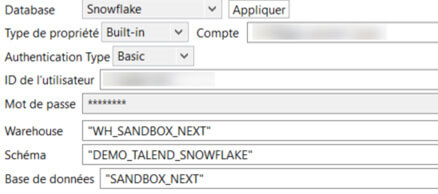
Sur la connexion Snowflake, on renseigne le compte, l’identifiant et le mot de passe ainsi que la base de données, le schéma et le moteur d’exécution de Snowflake (Warehouse). Il faut également renseigner le rôle dans les paramètres avancés.
On réplique ensuite nos données depuis notre base SQLServer vers Snowflake avec les composants tDBInput et tDBOutput. On utilise les composants de connexion déjà présents dans le job Talend. Dans notre exemple, notre table se nomme “CUSTOMER” et contient les données de clients localisés dans différentes villes (Lyon, Nantes, Bordeaux, Toulouse…).
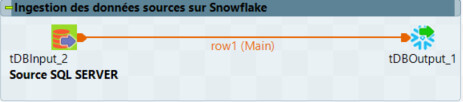
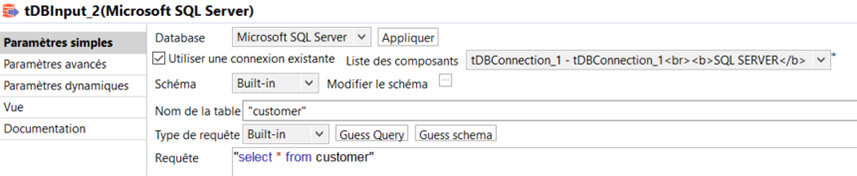
Dans le composant d’input, on renseigne la requête SQL et on définit le schéma de sortie.
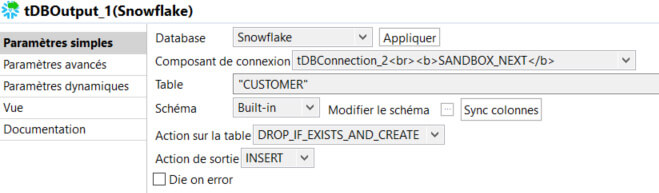
Dans le composant d’output, on renseigne le nom de la table cible. Si le nom n’est pas renseigné, il prend par défaut le nom du lien d’entrée (ici row1). On choisit ensuite la stratégie d’intégration qui convient, pour notre cas “DROP IF EXISTS AND CREATE” et “INSERT”.
Transformation des données
En mode ELT, plusieurs solutions existent :
- Utiliser le composant Talend dédié à l’ELT
- Exécuter des procédures stockées et développées dans Snowflake
- Exécuter des commandes SQL via le composant tSnowflakeRow
Transformation des données via le composant ELT de Talend
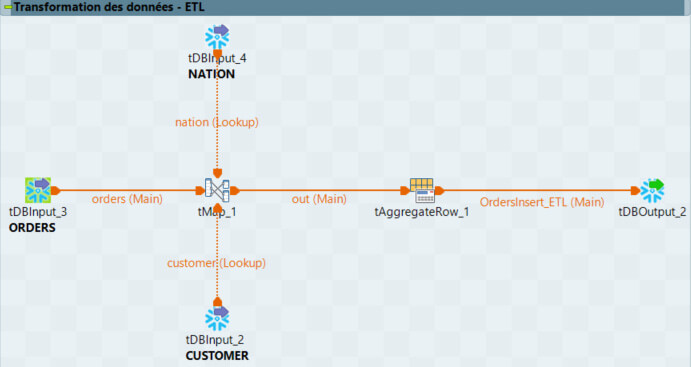
Maintenant que nos données sont dans Snowflake, nous allons utiliser le composant dédié à l’ELT de Talend pour effectuer des transformations directement dans Snowflake. Pour cela, nous allons exploiter les composants tELTInput, tELTOutput et tELTMap pour créer le job suivant :
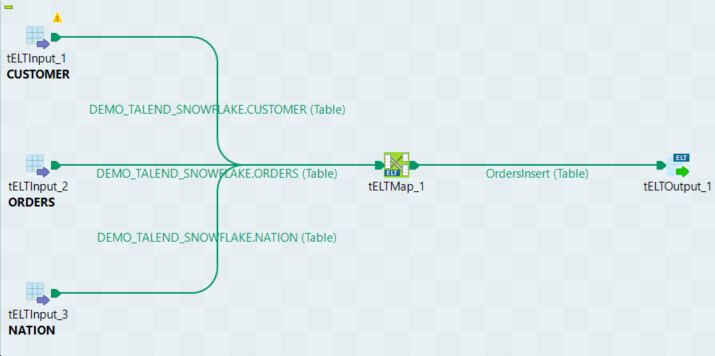
Notons que les composants d’entrée (tELTInput) et de sortie (tELTOutput) n'établissent pas de connexions à la base de données. On renseigne simplement le nom du schéma et de la table souhaitée ainsi que la technologie utilisée (Mapping Snowflake) et le schéma de sortie.
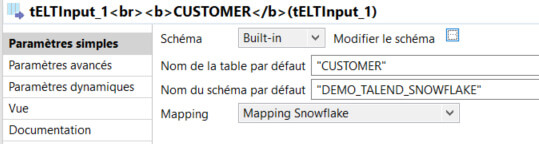
La connexion à la base se fait sur le composant tELTMap, responsable de la transformation des données et de l’exécution des opérations nécessaires. On peut utiliser une connexion déjà ouverte dans notre job en cochant “Utiliser une connexion existante”.

Sur le mapping, on ajoute manuellement les tables en entrée (croix verte dans le coin supérieur gauche).
On peut ensuite créer nos jointures et faire nos transformations comme dans un tMap classique. Dans notre cas, on va simplement afficher le nombre de commandes et la somme totale par pays en utilisant les fonctions SUM et COUNT DISTINCT et une clause GROUP BY. À noter que dans le composant EltMap, on utilise du code SQL pour créer des formules, contrairement au composant tMap où l’on utilise du code Java.
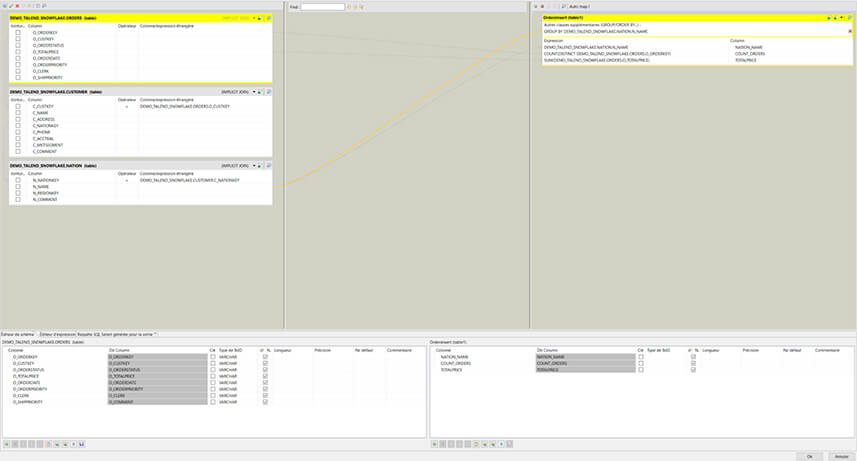
Dans le bandeau inférieur, on a la possibilité de voir la requête générée par le mapping (onglet Requête SQL générée pour la sortie table1) :
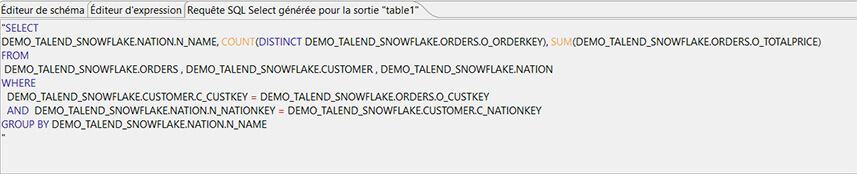
On pourra donc tester notre transformation directement en exécutant la requête dans Snowflake afin de vérifier le résultat.
On relie ensuite la sortie du mapping au composant tELTOutput, on renseigne le nom du schéma et de la table de sortie ainsi que la stratégie d’intégration : on supprime et crée la table et on fait une insertion.
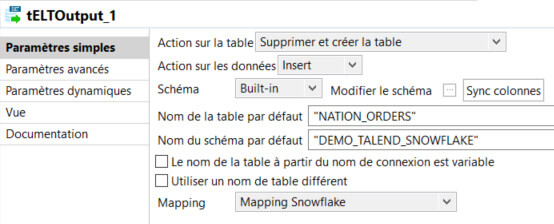
La table générée sur Snowflake :
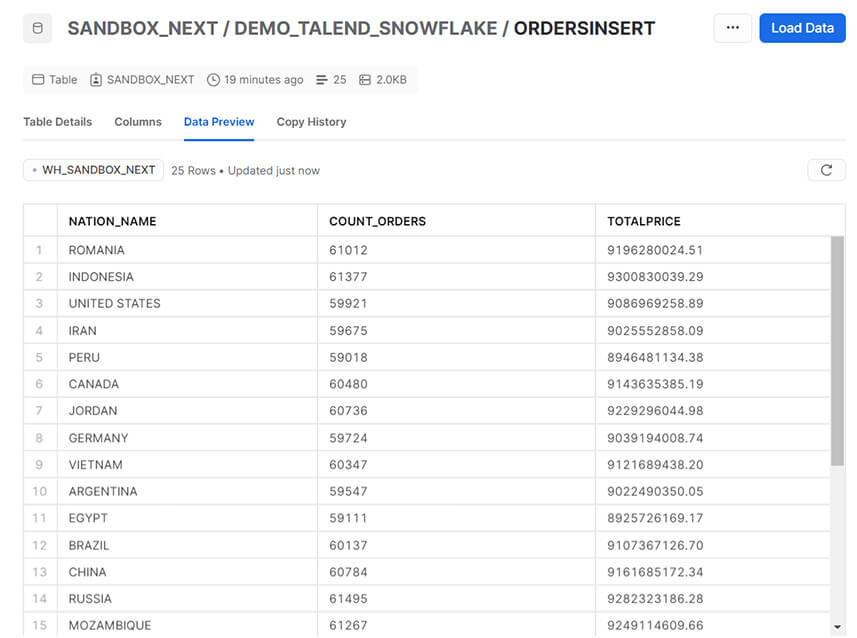
Appel d’une procédure dans Snowflake
On a également la possibilité d’appeler des procédures stockées Snowflake sur Talend avec le composant tDBRow. Dans notre cas, on va seulement répliquer une table de la même base de données. La procédure stockée exécute une instruction SQL dynamique CREATE OR REPLACE TABLE … AS SELECT * FROM … avec les paramètres renseignés.

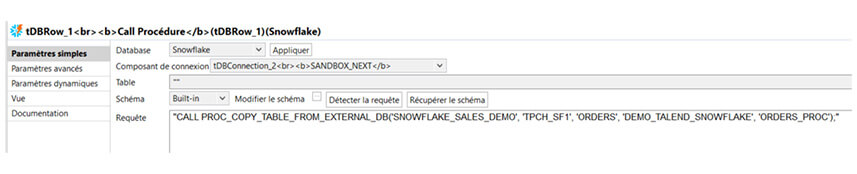
De la même façon, n’importe quel ordre SQL pourra être exécuté à l’aide de ce composant (INSERT, DELETE, UPDATE, MERGE…).
Performances ELT / ETL
Agrégation de données / volumétrie faible en sortie
Nous utilisons un moteur XS, soit le plus petit de Snowflake.
Pour le job créé à l’étape précédente, nous obtenons un temps d’exécution de 6 secondes pour une volumétrie de 3 millions de lignes en lecture et 25 lignes en écriture. En appliquant les mêmes transformations avec les composants ETL, nous obtenons un temps d’exécution de 50 secondes (cf ci-dessous).
Copie de données sur 15 000 000 de lignes
Nouvel exemple avec une copie de données d’une table à une autre. Nous utilisons toujours un moteur XS, soit le plus petit de Snowflake.
Comme vous pouvez le voir ci-dessous, en ELT, nous obtenons une insertion de 15 000 000 de lignes en 15 secondes.

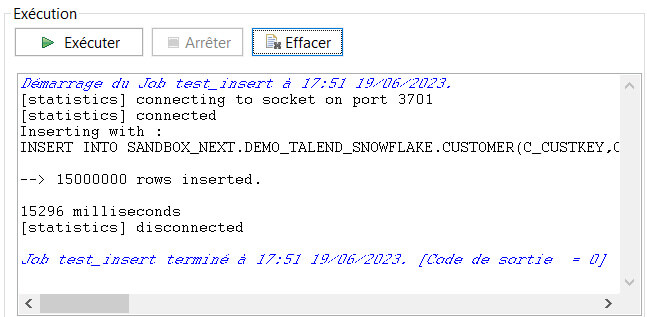
En mode ETL, nous obtenons cette même insertion en 138 secondes.

Le gain est donc de presque 90% entre les deux fonctionnements.
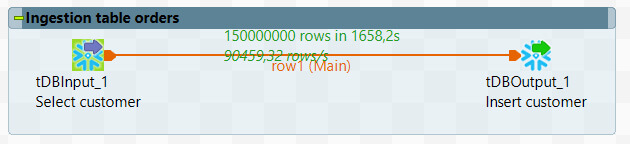
Copie de données sur 150 000 000 de lignes
Nous utilisons à nouveau un moteur XS, soit le plus petit de Snowflake. Et nous augmentons la volumétrie (x10) avec 150 000 000 de lignes à copier.
En mode ELT, nous sommes à 82 secondes.

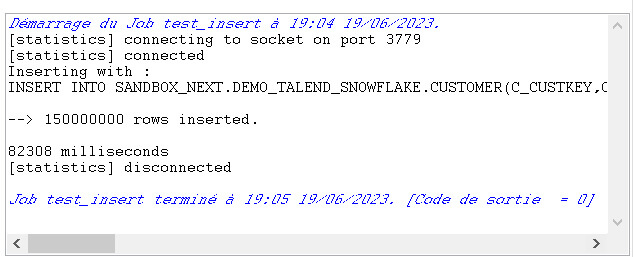
En mode ETL, nous obtenons un résultat de 1650 secondes
Le gain est de 95% dans ce cas-là.
Nous réalisons le même test avec un moteur XL (8x plus puissant que le XS). Nous obtenons les résultats suivants :
- ELT : 13 secondes
- ETL : 1003 secondes
Conclusion performances
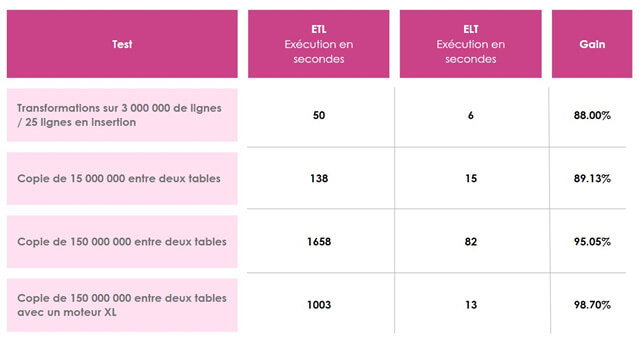
Nous voyons donc que le gain reste à peu près constant par rapport à la volumétrie lors de l’utilisation du même moteur. Cependant ce gain explose lorsqu’on profite de la scalabilité de la puissance du moteur de Snowflake.
Axes d'améliorations et optimisations
Côté optimisation des coûts et gain de temps sur un flux global, Snowflake ayant un moteur d’exécution très performant comme nous avons pu le constater, il est indispensable de paralléliser au maximum l’ingestion et la transformation des données dans notre ordonnancement Talend.
Côté Talend, l’ajout de quelques composants pourraient être bénéfiques pour profiter encore plus de l’ELT. Nous avons identifié quelques points :
- L’amélioration du composant tELTMap, pour le côté intuitif, afin de ne plus devoir écrire de code SQL, par exemple pour les SUM / GROUP BY. Cela faciliterait la prise en main de l’ELT par des novices en SQL
- La possibilité d’exécuter une transformation en ELT via les composants classiques
- La possibilité de pouvoir faire des “MERGE” (insertion ou mise à jour) dans les composants output
- La création d'un composant ELT permettant d’écrire notre code SQL complètement via un SELECT, avec une partie graphique pour sélectionner le mode chargement (INSERT, DELETE+INSERT, MERGE, DELETE), le type de table (ou vues), etc… pour les personnes ayant une forte affinité SQL
Pour conclure
Nous avons vu que l’utilisation de l’ELT améliore grandement les performances sur Snowflake par rapport à l’utilisation de l’ETL classique de Talend.
En effet, avec l’utilisation d’un ETL classique, Talend récupère les données sur son serveur d’exécution et les retravaille afin de les renvoyer dans Snowflake. Alors qu’en mode ELT, les données restent à l’intérieur de Snowflake, ce qui permet de bénéficier de la puissance de la plateforme.
Les composants ELT Talend sont disponibles sur plusieurs bases de données et plateformes. Cependant, elles ne vont pas toutes offrir les mêmes performances. De même, l’efficacité d’une utilisation en mode ETL variera en fonction de la puissance de votre base de données.
Dans une approche moderne, avec des bases de données de plus en plus performantes, l’ELT devient un incontournable pour traiter des volumétries de données importantes, et l’ETL sera réservé aux flux inter applicatifs et à la réplication des données.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ou Talend ? Rendez-vous sur la page Contact.