

Ce tuto vous décrit la méthodologie standard pour exporter des données depuis un serveur TM1 Planning Analytics vers un Lakehouse Microsoft Fabric.
L'objectif est de découpler les données de référence (Dimensions) des données transactionnelles (Faits) pour construire un modèle décisionnel (BI) performant et évolutif.
Architecture globale
L'approche retenue est celle du Modèle en Étoile (Star Schema). Au lieu d'exporter une table unique "à plat" (contenant beaucoup de redondances textuelles), nous procédons en trois phases distinctes :
- Extraction des Dimensions (Le référentiel) : Récupération dynamique de tous les axes d'analyse (Clients, Produits, Temps, Géographie) avec leurs attributs
- Extraction des Faits (Les données) : Récupération des données chiffrées brutes (P&L, Ventes) via des requêtes MDX optimisées, en utilisant les codes techniques (IDs)
- Modélisation Sémantique : Reconstruction de l'intelligence métier dans Fabric en liant les faits aux dimensions
(Voir schéma flux global en fin de document)
Méthodologie pas à pas
Phase 1 : Industrialisation du Référentiel (Dimensions TM1)
L'objectif est de créer un "aspirateur universel" qui détecte et met à jour automatiquement les tables de dimension.
Étape A : Le pipeline d'extraction
Nous utilisons l'API REST de TM1 (OData) pour lister et extraire les éléments.
1/ Lister les dimensions : Une activité Web interroge l'API pour obtenir la liste de toutes les dimensions non-système. (voir notre article relatif à l'utilisation des APis dans Planning Analytics)
Requête :
Dimensions?$select=Name&$filter=not startswith(Name,'}')
2/ Boucle (ForEach) : Le pipeline itère sur chaque dimension trouvée.
3/ Extraction (Copy Data) : Pour chaque dimension, on extrait la liste "physique" des éléments (et non la hiérarchie).
- URL Dynamique : Dimensions('@{item().Name}')/Hierarchies('@{item().Name}')/Elements?$select=Name,Attributes
- Note technique : L'utilisation de /Elements garantit l'unicité de la clé primaire (pas de doublons).
- Destination : Fichiers JSON bruts dans le Lakehouse (Files/raw_tm1/DIMs/dim_*.json)
Étape B : Transformation (Notebook PySpark)
Un script Python scanne le dossier de réception et transforme les JSON bruts en tables Delta structurées.
- Aplatissement : Le script détecte dynamiquement les attributs dans le JSON (ex: Attributes.Caption, Attributes.StartDate) et les convertit en colonnes.
- Nettoyage : Les noms de colonnes sont normalisés pour être compatibles SQL.
- Résultat : Création automatique des tables dim_region, dim_month, etc.
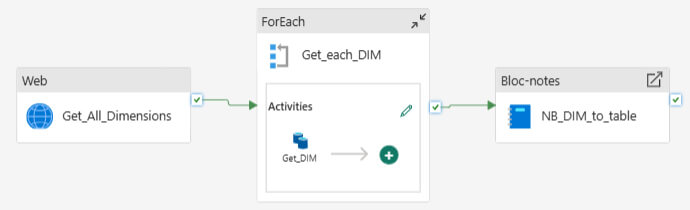
Flux d'ingestion des dimensions

Boucle de transformation convertissant dynamiquement les attributs JSON TM1 en colonnes relationnelles

Génération automatique des tables Delta au format Lakehouse avec fusion de schéma
Phase 2 : Extraction des Faits (Transactionnel)
Pour les données chiffrées (volumétrie importante), nous utilisons le langage natif de TM1 : le MDX.
Étape A : La requête MDX
Contrairement aux exports Excel, la requête MDX doit être conçue pour la performance :
- Récupération des Codes (IDs) : On ne récupère pas les libellés (ex: "France"), mais les codes (ex: "FR"). Cela allège le stockage et facilite les jointures.
- Filtre Niveau 0 : On utilise TM1FILTERBYLEVEL(..., 0) pour ne récupérer que les données fines (feuilles) et laisser Power BI gérer les agrégations.
Exemple de structure MDX :
SELECT {[Mesure]} ON 0,
({Dim1_Niv0} * {Dim2_Niv0} * {Dim3_Niv0}) ON 1
FROM [Cube]
Étape B : Pipeline et Transformation
- Pipeline : Une activité Copy Data envoie la requête MDX (POST) et stocke la réponse JSON complexe (Axes et Cells) dans le Lakehouse.
- Notebook : Un script spécifique "unpivot" la réponse MDX pour associer chaque valeur à ses coordonnées dimensionnelles (Tuples).
- Résultat : Une table fact_pnl contenant uniquement des codes et des valeurs numériques
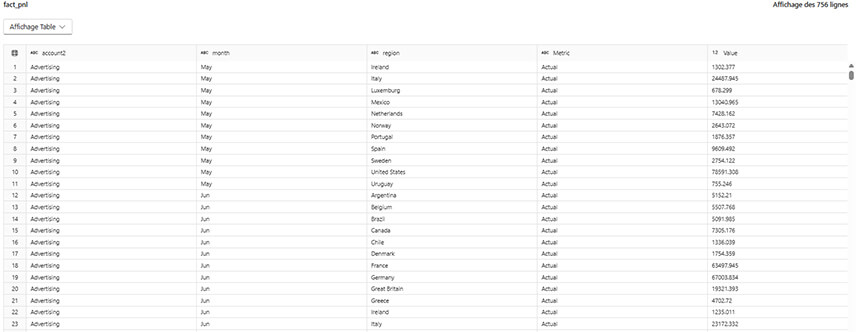
Table de faits normalisée (fact_pnl).
Les valeurs pourraient n’être que des clés techniques (IDs) ou des mesures numériques.
Phase 3 : Modélisation et Restitution
C'est l'étape finale où les données techniques deviennent des informations métier.
1/ Modèle Sémantique (Fabric SQL Endpoint) :
- Import des tables dim_* et fact_*.
- Création des relations (Drag & Drop) entre les colonnes Code des dimensions et les colonnes ID de la table de faits (Cardinalité 1 à Plusieurs).
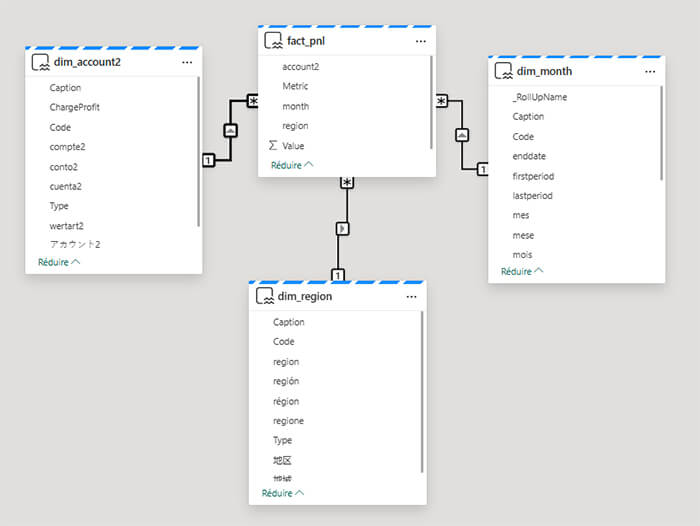
Modélisation sémantique en étoile (Star Schema)
La table de faits centrale fact_pnl est reliée aux dimensions référentielles (dim_region, dim_month, dim_account)
2/ Enrichissement :
- Mesures DAX : Création de calculs explicites (ex: Montant Réel = SUM(fact_pnl[Value])).
- Tri : Configuration du tri des colonnes textuelles (ex: Trier le nom du mois par son index chronologique).
3/ Reporting (Power BI) :
L'utilisateur final glisse le champ "Libellé" de la dimension et la "Mesure" du fait. Power BI recompose l'information automatiquement.
Exemple d'application : Analyse du P&L
Dans le cadre de notre projet pilote, cette méthode a été appliquée pour automatiser le reporting financier.
- Source : Cube P&L TM1.
- Dimensions traitées :
- dim_region : Gestion des pays, devises et hiérarchies géographiques
- dim_month : Gestion du temps, permettant un tri chronologique correct (Jan, Fév...) grâce à l'attribut StartDate
- dim_account : Gestion du plan de comptes, incluant les traductions (attributs multilingues)
- Fait : fact_pnl contenant les montants budgétaires et réels
Bénéfice constaté : L'architecture permet désormais de changer un attribut dans TM1 (ex: renommer un compte) et de voir la modification se répercuter instantanément sur tout l'historique des données dans Power BI, sans recharger la table de faits volumineuse.

Restitution dans Power BI
Traduction métier : Les codes de comptes sont remplacés par leurs libellés explicites ("Advertising").
Intelligence temporelle : Les mois sont triés chronologiquement (Jan > Fév) et non alphabétiquement.
Agrégation : Les totaux (Lignes et Colonnes) sont calculés dynamiquement par le moteur DAX de Fabric
Glossaire :
- Dimension TM1 = Dimension BI
- Élément niveau 0 = Clé de dimension
- Attribut TM1 = Colonne descriptive
- Mesure TM1 = Mesure DAX (après modélisation)
Bonnes pratiques :
- Toujours exporter les dimensions avant les faits
- Ne jamais stocker de libellés dans les tables de faits
- Ne jamais reconstruire de logique métier complexe dans les pipelines
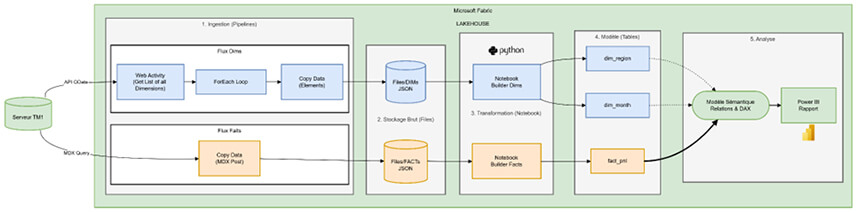
Architecture globale du flux de données (Pattern ELT).
Vue d'ensemble du pipeline d'intégration de TM1 vers Fabric. Les données sont extraites via deux flux distincts (Dimensions via API, Faits via MDX), stockées au format JSON (Bronze), transformées par Notebooks Spark (Silver), et exposées via un Modèle Sémantique en étoile (Gold) pour Power BI.
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur TM1 / Planning Analytics ? Rendez-vous sur la page Contact !