

Nous vous proposons de revenir sur le dernier événement de Microsoft : l’Ignite qui s’est déroulé du 18 au 22 novembre 2024 à Chicago. Beaucoup d’annonces ont été faites notamment sur Microsoft Fabric.
Dans cet article, nous aborderons les nouveautés qui nous semblent les plus importantes. N’hésitez pas à nous solliciter pour plus d’informations.
Commençons par un listing de l’ensemble des nouvelles fonctionnalités Microsoft Fabric annoncées pendant le Microsoft Ignite.
- Plateforme
- Nouveaux tris des éléments
- Le catalogue Onelake
- Le commutateur du tenant
- Data Bases
- Fabric databases
- Data engineering
- Tableau d’affichage des notebooks
- Data Factory
- Import / export de vos pipelines
- Nouvelles fonctionnalités de copilot dans vos pipelines
- Monitoring
- Monitorer avec EventHouse
- Modèle de données
- Nouvelle possibilité dans l’actualisation des tables
Passons maintenant aux fonctionnalités coup de cœur de Next Decision concernant les nouveautés d'octobre - novembre de Microsoft Fabric !
Plateforme Microsoft Fabric
Nouveaux tris des éléments
La première nouveauté que nous souhaitions aborder est d’ordre organisationnelle. Auparavant, lorsque vous ajoutiez un élément à votre espace de travail, ces derniers étaient classés par expériences (Data Factory, Power BI, …). Pour rappel, vous pouvez retrouver les expériences via le bouton en bas à gauche de votre page.
Cet ancien tri pouvait amener quelques confusions dans le choix des éléments. Depuis ce mois de novembre, les éléments sont maintenant classés de manière beaucoup plus logique :

Ce nouveau tri suit le cycle de vie de la donnée, à savoir : obtenir des données, préparer les données, visualiser les données, etc.
Le catalogue OneLake
Cette nouvelle fonctionnalité du catalogue OneLake permet à toutes les personnes travaillant sur les données d’avoir un endroit unifié regroupant toutes les données et surtout maintenant toutes les activités !

Vous allez pouvoir filtrer vos données et activités par type de données comme les données, les insights, les processus, les solutions ou encore les configurations.

Vous pourrez également filtrer par domaines et ainsi obtenir plus facilement les données et activités d’un domaine défini.
Sur la barre à gauche de votre écran, vous retrouverez également les éléments que vous avez créés sous la rubrique « Mes éléments », vous trouverez aussi les éléments par espaces de travail.
Vous avez donc maintenant toutes les informations sur vos données et vos activités dans un endroit unifié, rangées de manière logique et hiérarchique. Mais le catalogue OneLake ne s’arrête pas là puisque vous avez aussi toute une partie gouvernance et traçabilité de vos activités.

Dans l’exemple ci-dessus, nous obtenons les informations sur le modèle sémantique sélectionné. Dans le cas présent, nous avons accès aux différentes mises à jour.

Si vous cliquez sur « Traçabilité », vous obtenez toutes les activités sous-jacentes et liées au modèle sémantique.
Bien entendu ce nouveau catalogue OneLake reste soumis à la sécurité que vous lui attribuez. La sécurité reste un sujet central, vous n’aurez accès qu’aux données auxquelles vous avez accès.
Le catalogue OneLake se pose encore davantage comme le socle et point d’entrée de la plateforme.
Le commutateur de tenant
Grande nouveauté ! Le commutateur de tenant va vous apporter beaucoup d’agilité dans votre travail quotidien. Si vous travaillez sur plusieurs tenants différents, le commutateur va vous permettre de switcher entre les tenants. Cette nouvelle fonctionnalité vous apportera beaucoup de flexibilité et de réactivité.

Les Databases
Fabric databases

La grande nouveauté concerne assurément les Fabric Databases !
En effet, nous avons beaucoup de connecteurs possibles dans l’écosystème Fabric afin de se connecter à des blobs Azure, des fichiers, des ERP ou tout autre système de stockage de données. Mais il manquait au sein de l’écosystème Microsoft Fabric la possibilité de créer et gérer une base de données native.
C’est donc chose faite avec les Fabric Databases. Vous avez dorénavant la possibilité de créer une base de données avec la technologie OLTP supportée par le moteur SQL Server, directement dans Fabric. Ceci est très intéressant car cela élargit encore plus le champ des possibilités dans les architectures d’ingestion des données. Ces nouvelles bases de données intègrent directement toutes les fonctions de Transact-SQL ainsi que la possibilité d’utiliser un SQL Endpoint.
Microsoft Fabric - qui était jusque-là une plateforme de données unifiée et analytique - devient avec l’arrivée de ces databases une plateforme aussi transactionnelle. Nous avons donc désormais accès à toutes les fonctionnalités opérationnelles en plus des fonctionnalités analytiques, et tout ceci toujours au sein de la même plateforme de données.

Le second élément qui est particulièrement intéressant avec ces nouvelles bases de données est de pouvoir faire du “Translytical apps” dans Fabric, c’est-à-dire la possibilité de faire du “write back”.
En pratique, depuis un rapport Power BI , vous allez avoir la possibilité d’écrire directement dans la base de données sous-jacente, en cliquant sur un bouton de votre rapport Power BI qui va utiliser une fonction pour écrire dans votre base de données.
Imaginons qu’une erreur de saisie se soit glissée dans votre base de données, comme une date de naissance, 05/05/1899 au lieu de 05/05/1999 par exemple. Vous pourrez alors modifier cette valeur depuis votre rapport Power BI et modifier les données directement en base.
À noter que cette nouvelle fonctionnalité est un “sneak peak”, c'est à dire une démonstration faite par Microsoft mais sans roadmap de mise en production.
Data Engineering
Tableau d’affichage des notebooks
Passons maintenant à l’univers Apache Spark et cette nouvelle fonctionnalité qui vient améliorer toujours plus la visualisation des DataFrames dans les notebooks. Lorsque vous lancez une commande « display() » dans un notebook spark, vous avez maintenant la possibilité de générer des graphiques directement dans votre notebook.

Cette nouvelle est particulièrement intéressante puisque vous avez dorénavant la possibilité de vérifier la qualité de vos données de manière visuelle mais aussi d’avoir une première visualisation des distributions de vos variables.
Cette fonctionnalité va encore plus loin puisqu’elle vous permet de créer votre propre graphique afin de visualiser le comportement d’une variable en fonction d’une autre. Pour ce faire, il vous suffit de cliquer sur « Construire le mien » et de paramétrer votre graphique.

L’exemple ci-dessus vous propose la visualisation en box plot de la colonnes « Sales » représentant les ventes dans notre Data Frame. Nous visualisons la moyenne, le minimum, le maximum, les quantiles et la médiane.
Toutes ces informations peuvent être vérifiées directement depuis vos notebooks, ce qui va optimiser vos intégrations de données.
Data Factory
Import / export de vos pipelines et l’aide de développement
Coté Data Factory, deux nouveautés font leur apparition :
- Microsoft nous donne la possibilité d’exporter ou d’importer un pipeline de données, ce qui s'avère très pratique pour partager vos travaux avec vos collaborateurs.
Deux boutons font leur apparition dans le canevas de vos pipelines. Le bouton de gauche vous permettra d’exporter votre pipeline, l’export se matérialisera en un fichier ZIP avec à l’intérieur des fichiers en format text. Le second bouton vous permettra d’importer un pipeline.
- Une seconde nouveauté est arrivée dans le canevas de vos pipelines. Ce bouton ressemble beaucoup à l’image d’un modèle sémantique mais il vous propose tout autre chose. En effet si vous cliquez sur ce bouton, Fabric vous donnera plusieurs possibilités d’actions :


Microsoft Fabric vous propose des actions pré-développées capables d’être utilisées tout de suite. Une approche low-code pratique si l’univers Azure Data Factory n’est pas votre compétence première.
Nouvelles fonctionnalités de Copilot dans vos pipelines
Enfin, parlons de Copilot qui vient s’intégrer directement dans vos expériences de pipelines Data Factory. En effet, cette nouvelle intégration de Copilot dans vos pipelines est particulièrement intéressante car non seulement Copilot peut vous aider dans le développement de vos pipelines ou encore peut vous résumer le travail d’un pipeline.

Mais le plus intéressant est l’aide à la compréhension des erreurs. Si vous utilisez des pipelines dans vos développements Fabric, vous avez dû remarquer que les informations concernant cette erreur sont plutôt pauvres en détails.
Cette fois Copilot vient jouer le rôle d’assistant à la compréhension puisqu’il va vous permettre d’avoir des éléments détaillés. Votre réactivité et la gestion des logs sera beaucoup plus rapide et vous gagnerez en efficacité dans vos développements.

Le monitoring dans Microsoft
Nouveau monitoring avec EventHouse
Côté monitoring, vous pouvez dorénavant le gérer avec un Eventhouse et donc du temps réel ! Changement radical de paradigme puisque le temps réel va nous permettre d’avoir toutes les informations des exécutions de vos activités.
Pour l’utiliser, il vous suffit d’aller dans les paramètres de votre espace de travail et cliquer sur « supervision ». Un Eventhouse va être créé ainsi qu’une base KQL. Ces deux nouveaux éléments seront visibles depuis votre espace de travail.

Vous aurez ensuite la possibilité de visualiser les events de vos activités en temps réel. Cette nouvelle fonctionnalité permettra de monitorer toutes les exécutions rapidement et efficacement.
Attention, pour le moment seuls les modèles sémantiques sont intégrés. Nous attendons donc avec impatience l’intégration des activités comme les pipelines, les notebooks ou encore les rapports. Cette fonctionnalité est pour le moment cantonnée à votre espace de travail.
Modèle de données
Nouvelle actualisation des tables de votre modèle de données
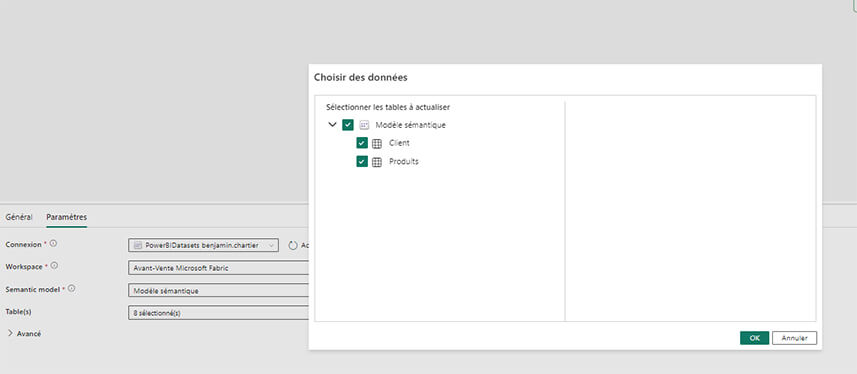
Pour finir cet article, nous vous proposons une nouvelle fonctionnalité très importante qui concerne le rafraîchissement des données dans vos modèles de données. En effet vous avez dorénavant la possibilité de choisir les tables que vous souhaitez mettre à jour.
Il est primordial de connaître parfaitement vos données si vous décidez d’actualiser seulement certaines tables.
Depuis votre activité de rafraîchissement de modèle sémantique dans votre pipeline, sous l’onglet table choisissez les tables à mettre à jour. Nous insistons sur le fait que cette nouvelle fonctionnalité est disponible seulement depuis un pipeline de données.
Et voilà, vous savez tout sur les nouveautés Microsoft Fabric made in Next Decision ! On vous donne RDV le mois prochain !
Nos consultants Next Decision sont experts certifiés Microsoft Fabric et vous accompagnent dans votre projet Microsoft Fabric. Nous pouvons également vous former, Contactez-nous !